Le cadre de pré-formation phonétique-sémantique (PSP) utilise l'apprentissage du "programme sensible au bruit" pour améliorer efficacement les performances de l'ASR dans les environnements bruyants. intégrant l'échauffement, l'apprentissage auto-supervisé et le réglage fin. Crédit :Recherche sur l'intelligence artificielle CAAI , Presse de l'Université Tsinghua
Des assistants vocaux populaires comme Siri et Amazon Alexa ont introduit la reconnaissance vocale automatique (ASR) au grand public. Bien que des décennies de fabrication, les modèles ASR ont du mal à être cohérents et fiables, en particulier dans les environnements bruyants. Des chercheurs chinois ont développé un cadre qui améliore efficacement les performances de l'ASR pour le chaos des environnements acoustiques quotidiens.
Des chercheurs de l'Université des sciences et technologies de Hong Kong et de WeBank ont proposé un nouveau cadre :la préformation phonétique-sémantique (PSP) et ont démontré la robustesse de leur nouveau modèle par rapport à des ensembles de données vocales synthétiques très bruyantes.
Leur étude a été publiée dans CAAI Artificial Intelligence Research le 28 août.
"La robustesse est un défi de longue date pour ASR", a déclaré Xueyang Wu du département d'informatique et d'ingénierie de l'Université des sciences et technologies de Hong Kong. "Nous voulons augmenter la robustesse du système ASR chinois à moindre coût."
L'ASR utilise l'apprentissage automatique et d'autres techniques d'intelligence artificielle pour traduire automatiquement la parole en texte à des fins telles que les systèmes à commande vocale et les logiciels de transcription. Mais les nouvelles applications axées sur le consommateur exigent de plus en plus que la reconnaissance vocale fonctionne mieux :gérez davantage de langues et d'accents, et fonctionne de manière plus fiable dans des situations réelles telles que les vidéoconférences et les entretiens en direct.
Traditionnellement, la formation des modèles acoustiques et linguistiques qui composent l'ASR nécessite de grandes quantités de données spécifiques au bruit, ce qui peut être coûteux en temps et en coût.
Le modèle acoustique (AM) transforme les mots en "phones", qui sont des séquences de sons de base. Le modèle de langage (LM) décode les téléphones en phrases en langage naturel, généralement avec un processus en deux étapes :un LM rapide mais relativement faible génère un ensemble de phrases candidates, et un LM puissant mais coûteux en calcul sélectionne la meilleure phrase parmi les candidats.
"Les modèles d'apprentissage traditionnels ne sont pas robustes contre les sorties de modèles acoustiques bruyants, en particulier pour les mots polyphoniques chinois avec une prononciation identique", a déclaré Wu. "Si la première passe du décodage du modèle d'apprentissage est incorrecte, il est extrêmement difficile pour la deuxième passe de la rattraper."
Le framework PSP nouvellement proposé facilite la récupération des mots mal classés. En pré-formant un modèle qui traduit les sorties AM directement en phrases avec toutes les informations contextuelles, les chercheurs peuvent aider le LM à se remettre efficacement des sorties bruyantes de l'AM.
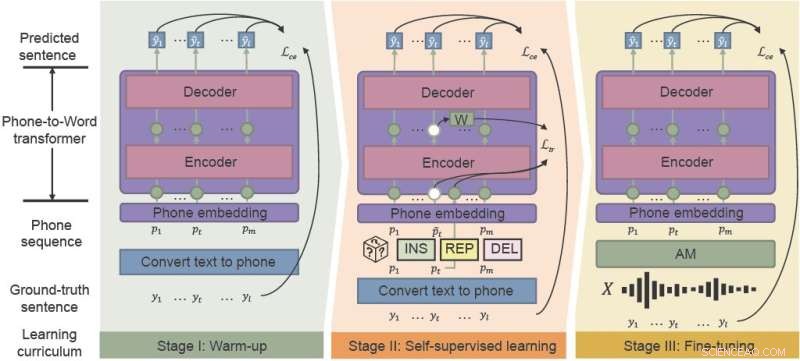
Le cadre PSP permet au modèle de s'améliorer grâce à un régime de pré-formation appelé programme sensible au bruit qui introduit progressivement de nouvelles compétences, en commençant facilement et en passant progressivement à des tâches plus complexes.
"La partie la plus cruciale de notre méthode proposée, l'apprentissage du curriculum sensible au bruit, simule le mécanisme de la façon dont les êtres humains reconnaissent une phrase à partir d'un discours bruyant", a déclaré Wu.
L'échauffement est la première étape, où les chercheurs pré-entraînent un transducteur téléphone-mot sur une séquence téléphonique propre, qui est traduite uniquement à partir de données textuelles non étiquetées, afin de réduire le temps d'annotation. Cette étape "réchauffe" le modèle, initialisant les paramètres de base pour mapper les séquences téléphoniques aux mots.
Dans la deuxième étape, l'apprentissage auto-supervisé, le transducteur apprend à partir de données plus complexes générées par des techniques et des fonctions d'apprentissage auto-supervisé. Enfin, le transducteur téléphone-mot qui en résulte est affiné avec des données vocales réelles.
Les chercheurs ont démontré expérimentalement l'efficacité de leur cadre sur deux ensembles de données réelles collectées à partir de scénarios industriels et de bruit synthétique. Les résultats ont montré que le framework PSP améliore efficacement le pipeline ASR traditionnel, en réduisant les taux d'erreur relative des caractères de 28,63 % pour le premier ensemble de données et de 26,38 % pour le second.
Dans les prochaines étapes, les chercheurs étudieront des méthodes de pré-formation PSP plus efficaces avec de plus grands ensembles de données non appariées, en cherchant à maximiser l'efficacité de la pré-formation pour le LM robuste au bruit. Utilisation de l'apprentissage multitâche pour la traduction vocale à faible latence














