Les corps humains ont des conceptions similaires. Cependant, les langues diffèrent dans la façon dont elles divisent le corps en parties et les nomment. Par exemple, les anglophones ont deux mots pour pied et jambe, alors que d'autres langues expriment les concepts pied et jambe en un seul mot.
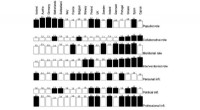
L’étude de la variation du vocabulaire des parties du corps dans diverses langues attire depuis de nombreuses années l’attention des chercheurs en linguistique, en anthropologie et en psychologie. Semblables aux principes développés pour le domaine sémantique de la couleur, des tendances universelles ont été identifiées et contrastées avec des variations spécifiques à la culture.
L'émergence de nouvelles méthodes d'analyse de réseau a permis de réaliser des comparaisons de vocabulaire à grande échelle dans des domaines sémantiques spécifiques pour étudier les structures universelles et culturelles.
Le professeur Johann-Mattis List, qui dirige la chaire de linguistique computationnelle multilingue à l'université de Passau, fait partie des chercheurs qui ont développé des algorithmes afin de faire la lumière sur la question de savoir comment les humains forment leur vocabulaire dans différentes langues.
Il a rejoint des chercheurs du Département d'évolution linguistique et culturelle de l'Institut Max Planck d'anthropologie évolutionniste de Leipzig, dans leur étude comparant le vocabulaire des parties du corps dans 1 028 langues.
L'étude, intitulée "Les facteurs universels et culturels façonnent les vocabulaires des parties du corps", a été publiée dans Scientific Reports. .
"Bien que nos corps suivent des conceptions similaires, les langues diffèrent dans la façon dont elles divisent le corps en parties et les nomment", explique Annika Tjuka, ancienne doctorante du professeur List et maintenant chercheuse postdoctorale au MPI-EVA, qui a lancé et mené l'étude.
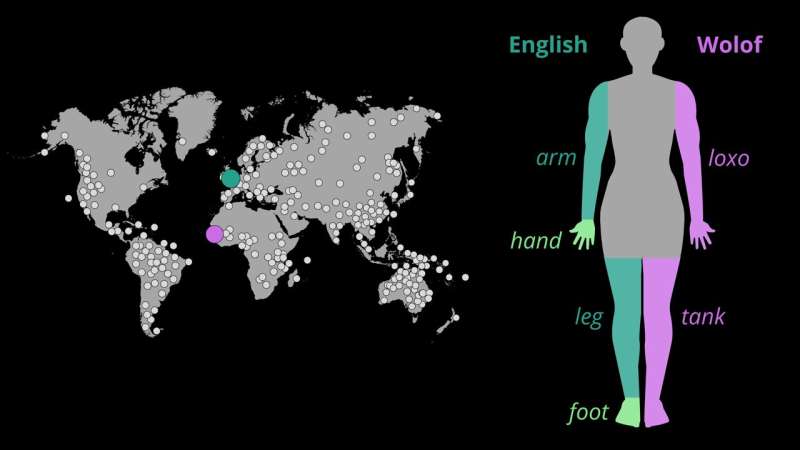
"En anglais, nous avons un mot pour bras et un autre pour main, mais le wolof, langue parlée au Sénégal en Afrique de l'Ouest, utilise un seul mot, loxo, pour désigner les deux parties du corps. Les locuteurs des deux langues ont un corps humain. Ainsi, pourquoi diffèrent-ils dans les parties qui reçoivent des noms uniques ?
Les résultats confirment le principe selon lequel s’il existe un mot distinct pour pied, alors il y en aura également un pour main. Mais les résultats montrent également qu’une partie du corps adjacente à une autre est plus susceptible de porter le même nom. L'une des raisons de ce modèle est que des langues comme le wolof se concentrent et mettent l'accent sur les caractéristiques fonctionnelles qui relient deux parties.
Les locuteurs reconnaissent que nous lançons une balle avec notre main et notre bras, ou que nous marchons avec notre jambe et notre pied. Des langues comme l'anglais, en revanche, se concentrent sur des repères visuels comme le poignet ou la cheville pour séparer les parties.
Le vocabulaire des parties du corps varie d'une langue à l'autre. Cependant, des tendances générales se dessinent au sein de cette diversité. "Pour comprendre les facteurs qui façonnent la diversité linguistique, nous avons besoin de davantage de données. Nous devons documenter les langues parlées dans des zones linguistiquement diverses. Et nous devons collecter des données sur le contexte sociologique dans lequel les langues sont parlées", explique le Dr Tjuka.
Pour la présente étude, l'équipe de linguistes a utilisé une base de données existante, Lexibank, développée par des chercheurs du MPI-EVA de Leipzig et de la Chaire de linguistique informatique multilingue de Passau. Il s'agit d'une vaste collection de listes de mots dans les langues du monde.
Grâce à une approche informatique, les chercheurs de Passau et de Leipzig ont extrait les mots de 36 parties du corps dans toutes ces langues et analysé les relations entre les mots dans une analyse de réseau.
"Il nous a fallu plusieurs années pour rassembler les données dans la collection Lexibank", explique le professeur List, qui a travaillé comme chercheur principal au MPI-EVA à Leipzig. "Nous pouvons maintenant commencer à analyser les données de différentes manières."
Le professeur List dirige le groupe de recherche « ProduSemy » à l'Université de Passau. Avec son équipe de recherche, il utilise également la base de données afin de comprendre comment les familles de mots se forment dans les langues.
Plus d'informations : Annika Tjuka et al, Les facteurs universels et culturels façonnent le vocabulaire des parties du corps, Rapports scientifiques (2024). DOI :10.1038/s41598-024-61140-0
Informations sur le journal : Rapports scientifiques
Fourni par l'Université de Passau