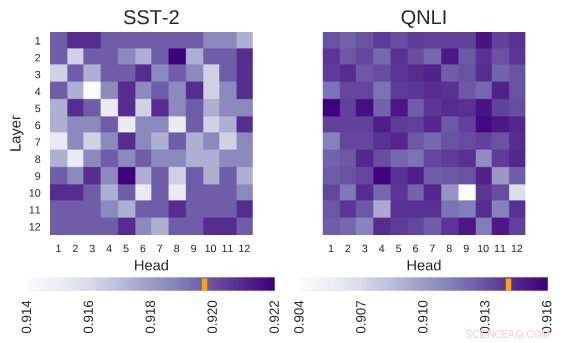
L'architecture BERT étudiée a l'architecture de 12 couches par 12 têtes. Chaque cellule de cette figure montre les performances du BERT si la tête correspondante est éteinte. Les couleurs plus foncées indiquent des performances plus élevées, et les cellules blanches indiquent les têtes sans lesquelles les performances de BERT diminuent. Stanford Sentiment Treebank (SST-2):Il existe plusieurs informations de codage de têtes qui sont nécessaires pour la tâche. Question Inférence du langage naturel (QNLI) :la plupart des têtes améliorent les performances globales lorsqu'elles sont éteintes. Crédit :Kovaleva et al.
BERT, un modèle basé sur un transformateur caractérisé par un mécanisme d'auto-attention unique, s'est jusqu'à présent avéré être une alternative valable aux réseaux de neurones récurrents (RNN) pour s'attaquer aux tâches de traitement du langage naturel (NLP). Malgré leurs avantages, jusque là, très peu de chercheurs ont étudié en profondeur ces architectures basées sur le BERT, ou essayé de comprendre les raisons de l'efficacité de leur mécanisme d'auto-attention.
Conscient de cette lacune dans la littérature, des chercheurs du Text Machine Lab de Lowell pour le traitement du langage naturel de l'Université du Massachusetts ont récemment mené une étude sur l'interprétation de l'auto-attention, le composant le plus vital des modèles BERT. L'investigateur principal et auteur principal de cette étude étaient Olga Kovaleva et Anna Rumshisky, respectivement. Leur article pré-publié sur arXiv et qui sera présenté à la conférence EMNLP 2019, suggère qu'un nombre limité de modèles d'attention se répète dans les différents sous-composants du BERT, faisant allusion à leur sur-paramétrisation.
"BERT est un modèle récent qui a fait une percée dans la communauté PNL, prendre en charge les classements à travers plusieurs tâches. Inspiré par cette tendance récente, nous étions curieux d'étudier comment et pourquoi cela fonctionne, " a déclaré l'équipe de chercheurs à TechXplore par e-mail. " Nous espérions trouver une corrélation entre l'auto-attention, le principal mécanisme sous-jacent du BERT, et des relations interprétables linguistiquement dans le texte d'entrée donné."
Les architectures basées sur BERT ont une structure en couches, et chacune de ses couches se compose de ce qu'on appelle des « têtes ». Pour que le modèle fonctionne, chacune de ces têtes est entraînée à coder un type d'information spécifique, contribuant ainsi à sa manière au modèle global. Dans leur étude, les chercheurs ont analysé les informations codées par ces têtes individuelles, en se concentrant à la fois sur sa quantité et sa qualité.
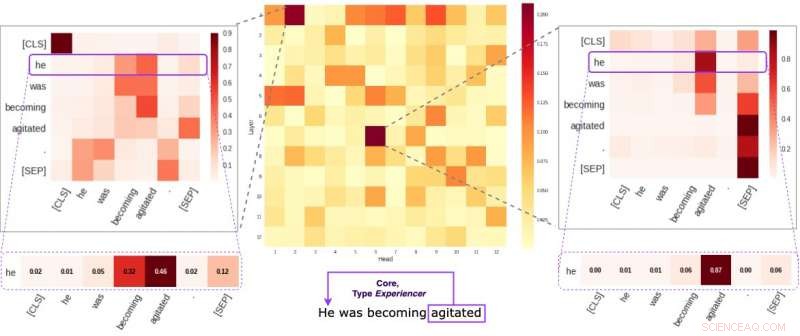
Chaque cellule de la figure du milieu reflète la façon dont les chefs individuels prêtent attention aux liens sémantiques de base dans une phrase donnée (en moyenne). Nous avons identifié deux têtes spécifiques qui ont tendance à coder davantage l'information sémantique que les autres. Les deux images sur les côtés montrent comment ces deux têtes attribuent des poids à des mots individuels dans une phrase aléatoire de notre ensemble de données. Crédit :Kovaleva et al.
"Notre méthodologie s'est concentrée sur l'examen des têtes individuelles et les modèles d'attention qu'elles ont produits, " les chercheurs ont expliqué. " Essentiellement, nous essayions de répondre à la question :"Quand BERT encode un seul mot d'une phrase, fait-il attention aux autres mots d'une manière significative pour les humains ? »
Les chercheurs ont réalisé une série d'expériences en utilisant à la fois des modèles BERT pré-entraînés et affinés. Cela leur a permis de recueillir de nombreuses observations intéressantes liées au mécanisme d'auto-attention qui est au cœur des architectures basées sur BERT. Par exemple, ils ont observé qu'un ensemble limité de schémas d'attention est souvent répété dans différentes têtes, ce qui suggère que les modèles BERT sont sur-paramétrés.
"Nous avons constaté que BERT a tendance à être sur-paramétré, et il y a beaucoup de redondance dans les informations qu'il encode, ", ont déclaré les chercheurs. "Cela signifie que l'empreinte de calcul de la formation d'un modèle aussi grand n'est pas bien justifiée."
Une autre découverte intéressante recueillie par l'équipe de chercheurs de l'Université du Massachusetts Lowell est que, selon la tâche abordée par un modèle BERT, éteindre au hasard certaines de ses têtes peut conduire à une amélioration, plutôt qu'un déclin, en performances. En outre, les chercheurs n'ont identifié aucun modèle linguistique particulièrement important pour déterminer les performances du BERT dans les tâches en aval.
« Rendre le deep learning interprétable est important à la fois pour la recherche fondamentale et appliquée, et nous continuerons à travailler dans ce sens, ", ont déclaré les chercheurs. "De nouveaux modèles basés sur BERT ont récemment été publiés, et nous prévoyons d'étendre notre méthodologie pour les étudier également."
© 2019 Réseau Science X














