
Crédit :CC0 Domaine Public
Le 3 novembre, 2020 - et pendant de nombreux jours après - des millions de personnes ont gardé un œil attentif sur les modèles de prédiction de l'élection présidentielle utilisés par divers organes de presse. Avec des enjeux si élevés en jeu, chaque tic d'un décompte et chaque secousse d'un graphique pourraient envoyer des ondes de choc de surinterprétation.
Un problème avec les décomptes bruts de l'élection présidentielle est qu'ils créent un faux récit selon lequel les résultats finaux se développent toujours de manière drastique. En réalité, le soir des élections, il n'y a pas de "rattrapage par derrière" ou de "perte d'avance" car les suffrages sont déjà exprimés; le gagnant a déjà gagné, nous ne le savons tout simplement pas encore. Plus qu'être simplement imprécis, ces descriptions fascinantes du processus de vote peuvent rendre les résultats excessivement suspects ou surprenants.
"Les modèles prédictifs sont utilisés pour prendre des décisions qui peuvent avoir d'énormes conséquences sur la vie des gens, " a déclaré Emmanuel Candès, la chaire Barnum-Simons en mathématiques et statistiques à la Faculté des sciences humaines de l'Université de Stanford. "Il est extrêmement important de comprendre l'incertitude de ces prédictions, afin que les gens ne prennent pas de décisions basées sur de fausses croyances."
Une telle incertitude était exactement ce Le Washington Post Le data scientist Lenny Bronner visait à mettre en évidence dans un nouveau modèle de prédiction qu'il a commencé à développer pour les élections locales de Virginie en 2019 et affiné pour les élections présidentielles, avec l'aide de John Cherian, un doctorat en cours. étudiant en statistique à Stanford que Bronner connaissait de ses études de premier cycle.
"Le modèle visait vraiment à ajouter du contexte aux résultats qui étaient affichés, " a déclaré Bronner. "Il ne s'agissait pas de prédire l'élection. Il s'agissait de dire aux lecteurs que les résultats qu'ils voyaient ne reflétaient pas l'endroit où nous pensions que les élections allaient se terminer. »
Ce modèle est la première application dans le monde réel d'une technique statistique existante développée à Stanford par Candès, ancien chercheur postdoctoral Yaniv Romano et ancien étudiant diplômé Evan Patterson. La technique est applicable à une variété de problèmes et, comme dans le modèle de prédication de la poste, pourrait aider à accroître l'importance de l'incertitude honnête dans les prévisions. Alors que la poste continue d'affiner son modèle pour les futures élections, Candès applique ailleurs la technique sous-jacente, y compris aux données sur COVID-19.
Éviter les suppositions
Pour créer cette technique statistique, Candes, Romano et Evan Patterson ont combiné deux domaines de recherche - la régression quantile et la prédiction conforme - pour créer ce que Candès a appelé « le plus informatif, gamme bien calibrée de valeurs prédites que je sais construire."
Alors que la plupart des modèles de prédiction tentent de prévoir une valeur unique, souvent la moyenne (moyenne) d'un ensemble de données, la régression quantile estime une gamme de résultats plausibles. Par exemple, une personne peut vouloir trouver le 90e quantile, qui est le seuil en dessous duquel la valeur observée devrait chuter 90 pour cent du temps. Lorsqu'il est ajouté à la régression quantile, la prédiction conforme - développée par l'informaticien Vladimir Vovk - calibre les quantiles estimés afin qu'ils soient valides en dehors d'un échantillon, comme pour des données inédites. Pour le modèle électoral du Post, cela signifiait utiliser les résultats des votes de zones démographiquement similaires pour aider à calibrer les prédictions sur les votes qui étaient exceptionnels.
La particularité de cette technique est qu'elle commence par des hypothèses minimales intégrées aux équations. Pour que cela fonctionne, cependant, il doit commencer par un échantillon représentatif de données. C'est un problème pour le soir des élections, car le nombre de votes initial (généralement de petites communautés avec plus de votes en personne) reflète rarement le résultat final.
Sans accès à un échantillon représentatif des votes actuels, Bronner et Cherian ont dû ajouter une hypothèse. Ils ont calibré leur modèle en utilisant les décomptes des voix des élections présidentielles de 2016 de sorte que lorsqu'une région a déclaré 100 pour cent de ses votes, le modèle de la poste supposerait que tout changement entre les votes de cette région en 2020 et ses votes en 2016 serait également reflété dans des comtés similaires. (Le modèle s'ajusterait alors davantage, réduisant ainsi l'influence de l'hypothèse, car davantage de régions ont déclaré 100 pour cent de leurs votes.) Pour vérifier la validité de cette méthode, ils ont testé le modèle à chaque élection présidentielle, à partir de 1992, et a constaté que ses prédictions correspondaient étroitement aux résultats du monde réel.
"Ce qui est bien avec l'approche d'Emmanuel à ce sujet, c'est que les barres d'erreur autour de nos prédictions sont beaucoup plus réalistes et nous pouvons maintenir des hypothèses minimales, " dit Cherian.
Visualiser l'incertitude
En action, la visualisation du modèle vivant de la poste a été minutieusement conçue pour afficher en évidence ces barres d'erreur et l'incertitude qu'elles représentaient. Le Post a exécuté le modèle pour prévoir l'éventail des résultats électoraux probables dans différents États et types de comtés; les comtés ont été classés en fonction de leurs caractéristiques démographiques. Dans tous les cas, chaque candidat avait sa propre barre horizontale qui s'est remplie en bleu pour Joe Biden, rouge pour Donald Trump—pour montrer les votes connus. Puis, le reste de la barre contenait un gradient qui représentait les résultats les plus probables pour les votes en suspens, selon le modèle. La zone la plus sombre du dégradé était le résultat le plus probable.
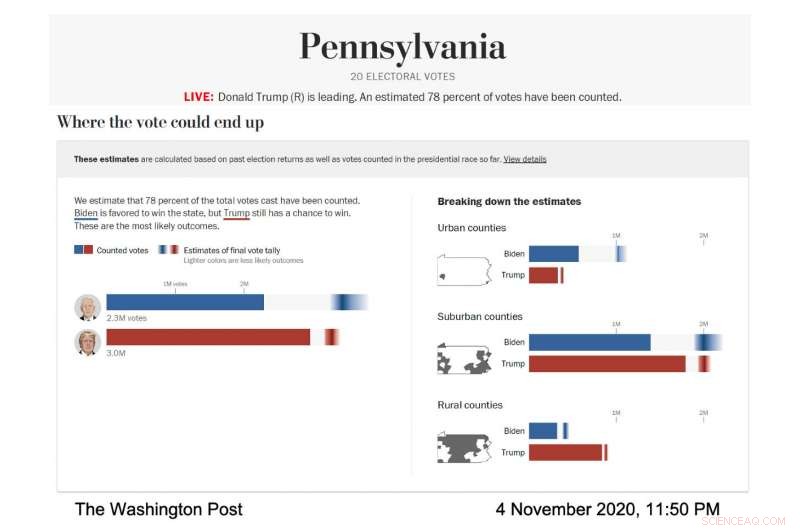
Capture d'écran du modèle électoral du Washington Post, montrant la prédiction de vote pour la Pennsylvanie le 4 novembre, 2020. (Crédit image :avec l'aimable autorisation du Washington Post)
"Nous avons parlé aux chercheurs de la visualisation de l'incertitude et nous avons appris que si vous donnez à quelqu'un une prédiction moyenne et que vous lui dites ensuite combien d'incertitude est impliquée, ils ont tendance à ignorer l'incertitude, " a déclaré Bronner. " Nous avons donc fait une visualisation qui est très " incertaine en avant ". Nous voulions montrer, c'est l'incertitude et nous n'allons même pas vous dire quelle est notre prédiction moyenne."
Alors que la nuit des élections avançait, la partie la plus sombre du gradient de Biden dans la visualisation du vote total était plus à droite de la barre, ce qui signifiait que le modèle prédisait qu'il finirait avec plus de votes. Son gradient était également plus large et s'étendait de manière asymétrique vers le côté du vote le plus élevé de la barre, ce qui signifie que le modèle a prédit qu'il y avait de nombreux scénarios, avec des cotes décentes, où il gagnerait plus de voix que le nombre le plus probable.
« Le soir des élections, nous avons remarqué que les barres d'erreur étaient très courtes du côté gauche de la barre de Biden et très longues du côté droit, " a déclaré Cherian. " C'était parce que Biden avait beaucoup d'avantages pour potentiellement surpasser notre projection de manière substantielle et il n'avait pas beaucoup d'inconvénients. " Cette prédiction asymétrique était une conséquence de l'approche de modélisation particulière utilisée par Cherian et Bronner Étant donné que les prévisions du modèle ont été calibrées à l'aide des résultats de comtés démographiquement similaires qui avaient fini de déclarer leurs votes, il est devenu clair que Biden avait de bonnes chances de surpasser de manière significative le vote démocrate de 2016 dans les comtés de banlieue, alors qu'il était extrêmement improbable qu'il fasse pire.
Bien sûr, alors que le dépouillement se dirigeait vers l'arrivée, les gradients se sont rétrécis et les prédictions incertaines du Post semblaient de plus en plus certaines - une situation angoissante pour les scientifiques des données soucieux d'exagérer des conclusions aussi importantes.
"J'étais particulièrement inquiet que la course se résume à un seul état, et nous aurions une prédiction sur notre page pour les jours qui finiraient par ne pas se réaliser, " a déclaré Bronner.
Et cette inquiétude était bien fondée car le modèle prédisait fortement et obstinément une victoire de Biden pendant plusieurs jours alors que le décompte final des votes ne venait d'aucun État, but three:Wisconsin, Michigan and Pennsylvania.
"He ended up winning those states, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, after all, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. En réalité, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, cependant, is that the conclusions suffer if there isn't enough data. Par exemple, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, bien que, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."














