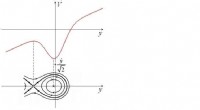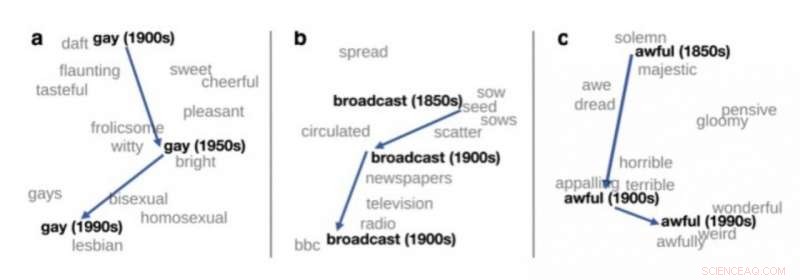
Vue en deux dimensions du changement de sens de trois mots anglais, extrait de Hamilton et al. (2016). Crédit :upf
La sémantique distributionnelle obtient des représentations du sens des mots en traitant des milliers de textes et en extrayant des généralisations à l'aide d'algorithmes de calcul. Malgré la popularité de la sémantique distributionnelle dans des domaines tels que la linguistique informatique et les sciences cognitives, son impact sur la linguistique théorique a été jusqu'à présent très limité.
Recherche par Gemma Boleda, chef du groupe de recherche Computational Linguistics and Language Theory (COLT) et enseignant-chercheur ICREA au Département de traduction et sciences du langage de l'UPF, publié dans la revue Revue annuelle de linguistique , fournit une revue critique des nombreuses études disponibles sur la sémantique distributionnelle, mettant particulièrement l'accent sur les résultats pertinents pour la linguistique théorique. Plus précisément, il y a trois domaines :le changement sémantique, polysémie et composition, et l'interface grammaire-sémantique.
La recherche de Gemma Boleda cherche à relier les approches théoriques et informatiques pour faire progresser la connaissance collective du fonctionnement du langage. L'une des méthodes qu'elle a beaucoup étudiées est la sémantique distributionnelle, qui permet d'obtenir automatiquement des représentations de mots. Il a été démontré que ces représentations reflètent des propriétés linguistiques importantes, comme la similarité de deux mots :une personne vous dira que « chien » et « chiot » sont très similaires, et pourtant « chien » et « démocratie » ne se ressemblent guère; la sémantique distributionnelle dira la même chose, grâce au fait qu'il induit des propriétés linguistiques basées sur des textes écrits par des personnes. Par conséquent, la sémantique distributionnelle fournit des représentations radicalement empiriques.
La sémantique distributionnelle permet d'analyser l'usage des mots et l'évolution de leur sens
La sémantique distributionnelle fournit un cadre complémentaire à d'autres, méthodes plus traditionnelles, non seulement parce qu'elle est radicalement empirique mais aussi parce qu'elle fournit des représentations multidimensionnelles :deux mots peuvent être assimilés sur une dimension de sens (« pizza » et « pâtes » sont des aliments), ou sur un autre ("pizza" et "roue" sont ronds). Pour représenter tous les aspects du sens, des représentations multidimensionnelles sont nécessaires. La sémantique distributionnelle peut capturer les utilisations courantes de deux mots, ainsi que leurs facteurs de différenciation.
L'une des applications importantes de la sémantique distributionnelle en linguistique théorique est la détection des changements de sens. Si des données linguistiques de différentes périodes sont traitées, comme des livres en anglais de 1900, 1950 et 1990, la sémantique distributionnelle peut être utilisée pour détecter automatiquement le changement de sens de certains mots. Par exemple, le mot "gay" en anglais au début du siècle dernier signifiait "heureux" et a été de plus en plus utilisé pour signifier "homosexuel".
Aspects de la recherche en sémantique distributionnelle qui contribuent à la théorie du langage
A partir de l'analyse des œuvres étudiées, Boleda conclut qu'il existe des preuves suffisantes pour que les résultats solides de la sémantique distributionnelle soient directement importés dans la recherche en linguistique théorique.
« Il existe au moins quatre aspects de la recherche en sémantique distributionnelle qui peuvent contribuer à la théorie du langage. Le premier aspect est exploratoire :les représentations distributionnelles peuvent être utilisées pour explorer des données à grande échelle, par exemple en examinant la similitude des mots. La seconde est comme un outil pour identifier des cas spécifiques de phénomènes linguistiques. Par exemple, on peut identifier des mots dont le sens a changé en comparant les représentations obtenues à partir de textes de différentes époques. Le troisième est un banc d'essai :évaluer différentes hypothèses linguistiques en termes distributionnels. Le quatrième et le plus difficile est la découverte de nouveaux phénomènes linguistiques ou de tendances théoriques pertinentes dans les données, " explique l'auteur dans son ouvrage.