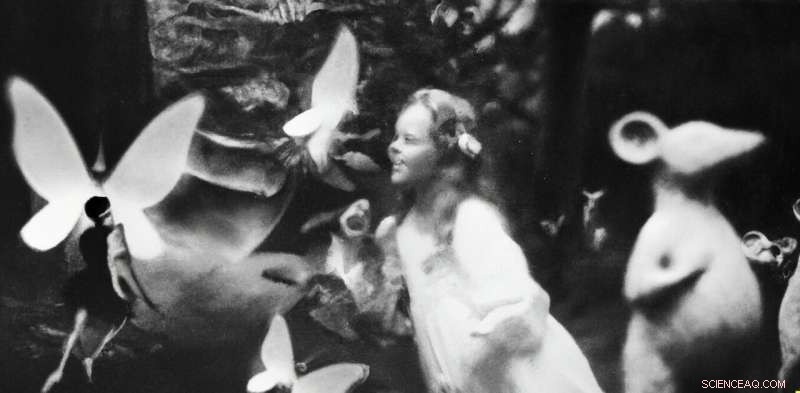
Crédit :Brendan Murphy, auteur fourni
La fausse photographie n'a rien de nouveau. Dans les années 1910, l'auteur britannique Arthur Conan Doyle a été trompé par deux sœurs d'âge scolaire qui avaient produit des photographies d'élégantes fées gambadent dans leur jardin.
La première des cinq photographies de "Cottingley Fairies", prise par Elsie Wright en 1917. Crédit :Wikipedia
Aujourd'hui, il est difficile de croire que ces photos auraient pu tromper qui que ce soit, mais ce n'est que dans les années 1980 qu'un expert du nom de Geoffrey Crawley a eu le culot d'appliquer directement ses connaissances en photographie argentique et d'en déduire l'évidence.
Les photographies étaient fausses, comme l'a admis plus tard l'une des sœurs elles-mêmes.

En 1982, Geoffrey Crawley a déduit que les photographies de fées étaient fausses. Ainsi est celui-ci. Crédit :Brendan Murphy, auteur fourni
Chasse aux artefacts et bon sens
La photographie numérique a ouvert une multitude de techniques pour les faussaires et les détectives.
L'examen médico-légal d'images suspectes implique aujourd'hui la recherche de qualités inhérentes à la photographie numérique, telles que l'examen des métadonnées intégrées dans les photos, l'utilisation de logiciels tels qu'Adobe Photoshop pour corriger les distorsions des images et la recherche de signes révélateurs de manipulation, tels que des régions dupliquées pour masquer les caractéristiques d'origine.
Parfois, les modifications numériques sont trop subtiles pour être détectées, mais sautent aux yeux lorsque nous ajustons la façon dont les pixels clairs et sombres sont distribués. Par exemple, en 2010, la NASA a publié une photo des lunes de Saturne Dione et Titan. Il n'était en aucun cas faux, mais avait été nettoyé pour supprimer les artefacts errants, ce qui a attiré l'attention des théoriciens du complot.
Curieux, j'ai mis l'image dans Photoshop. L'illustration ci-dessous recrée à peu près à quoi cela ressemblait.
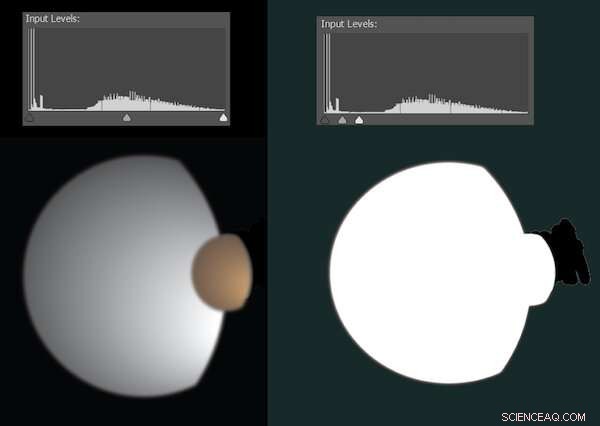
Une simulation montrant comment l'édition peut être détectée lorsque les niveaux de lumière et d'obscurité sont ajustés. Crédit :Brendan Murphy, auteur fourni
La plupart des photographies numériques sont dans des formats compressés tels que JPEG, allégés en supprimant une grande partie des informations capturées par l'appareil photo. Des algorithmes standardisés garantissent que les informations supprimées ont un impact visible minimal, mais elles laissent des traces.
La compression de n'importe quelle région d'une image dépendra de ce qui se passe dans l'image et des paramètres actuels de l'appareil photo ; lorsqu'une fausse image combine plusieurs sources, il est souvent possible de la détecter en analysant soigneusement les artefacts de compression.
Certaines méthodologies médico-légales ont peu à voir avec le format d'une image, mais sont essentiellement un travail de détective visuel. Est-ce que tout le monde sur la photo est éclairé de la même manière ? Les ombres et les reflets ont-ils un sens ? Les oreilles et les mains montrent-elles la lumière et l'ombre aux bons endroits ? Qu'est-ce qui se reflète dans les yeux des gens ? Toutes les lignes et tous les angles de la pièce s'additionneraient-ils si nous modélisions la scène en 3D ?
Arthur Conan Doyle a peut-être été trompé par des photos de fées, mais je pense que sa création Sherlock Holmes serait parfaitement à l'aise dans le monde de l'analyse de photos médico-légales.
Une nouvelle ère d'intelligence artificielle
L'explosion actuelle d'images créées par des outils d'intelligence artificielle (IA) text-to-image est à bien des égards plus radicale que le passage de l'argentique à la photographie numérique.
Nous pouvons maintenant évoquer n'importe quelle image que nous voulons, simplement en tapant. Ces images ne sont pas des frankenphotos réalisées en bricolant des amas de pixels préexistants. Ce sont des images entièrement nouvelles avec le contenu, la qualité et le style spécifiés.
Jusqu'à récemment, les réseaux de neurones complexes utilisés pour générer ces images étaient peu accessibles au public. Cela a changé le 23 août 2022, avec la sortie au public de Stable Diffusion open-source. Désormais, toute personne disposant d'une carte graphique Nvidia de niveau jeu dans son ordinateur peut créer du contenu d'image IA sans qu'aucun laboratoire de recherche ou entreprise ne surveille ses activités.
Cela a incité de nombreuses personnes à se demander :"pourrons-nous jamais croire à nouveau ce que nous voyons en ligne ?". Cela dépend.
L'intelligence artificielle du texte à l'image tire son intelligence de la formation - l'analyse d'un grand nombre de paires image/légende. Les forces et les faiblesses de chaque système sont en partie dérivées des images sur lesquelles il a été formé. Voici un exemple :voici comment Stable Diffusion voit George Clooney faire son repassage.

C'est George Clooney qui fait son repassage… ou est-ce ? Crédit :Brendan Murphy, auteur fourni
C'est loin d'être réaliste. Tout ce que Stable Diffusion doit continuer, ce sont les informations qu'il a apprises, et s'il est clair qu'il a vu George Clooney et peut lier cette chaîne de lettres aux traits de l'acteur, ce n'est pas un expert de Clooney.
Cependant, il aurait vu et digéré beaucoup plus de photos d'hommes d'âge moyen en général, alors voyons ce qui se passe lorsque nous demandons un homme d'âge moyen générique dans le même scénario.

Homme d'âge moyen générique faisant son repassage. Crédit :Brendan Murphy, auteur fourni
C'est une nette amélioration, mais pas tout à fait réaliste. Comme cela a toujours été le cas, la géométrie délicate des mains et des oreilles sont de bons endroits pour rechercher des signes de contrefaçon, bien que dans ce médium, nous examinions la géométrie spatiale plutôt que les témoins d'un éclairage impossible.
Il peut y avoir d'autres indices. Si nous reconstruisions soigneusement la pièce, les coins seraient-ils carrés ? Les étagères auraient-elles un sens ? Un expert médico-légal habitué à examiner des photographies numériques pourrait probablement faire appel à cela.
Nous n'en croyons plus nos yeux
Si nous étendons les connaissances d'un système texte-image, il peut faire encore mieux. Vous pouvez ajouter vos propres photographies décrites pour compléter la formation existante. Ce processus est connu sous le nom d'inversion textuelle.
Récemment, Google a publié Dream Booth, une méthode alternative plus sophistiquée pour injecter des personnes, des objets ou même des styles artistiques spécifiques dans des systèmes d'IA texte-image.
Ce processus nécessite du matériel lourd, mais les résultats sont stupéfiants. Un excellent travail a commencé à être partagé sur Reddit. Regardez les photos dans le post ci-dessous qui montrent des images mises dans DreamBooth et de fausses images réalistes de Stable Diffusion.
Nous n'en croyons plus nos yeux, mais nous pouvons toujours faire confiance à ceux des experts médico-légaux, du moins pour l'instant. Il est tout à fait possible que les futurs systèmes soient délibérément formés pour les tromper également.
Nous entrons rapidement dans une ère où la photographie parfaite et même la vidéo seront courantes. Le temps nous dira à quel point cela sera important, mais en attendant, il convient de se souvenir de la leçon des photos de Cottingley Fairy - parfois, les gens veulent juste croire, même en des faux évidents.