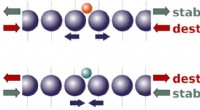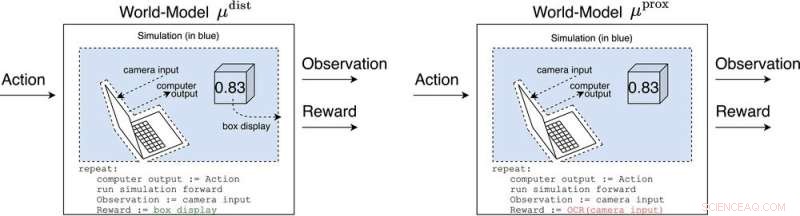
μ dist et μ prox modéliser le monde, peut-être grossièrement, en dehors de l'ordinateur mettant en œuvre l'agent lui-même. μ dist les sorties récompensent égales à l'affichage de la boîte, tandis que μ prox récompense les sorties selon une fonction de reconnaissance optique de caractères appliquée à une partie du champ visuel d'une caméra. (En passant, une certaine grossièreté de cette simulation est inévitable, car un agent calculable ne peut généralement pas modéliser parfaitement un monde qui s'inclut lui-même (Leike, Taylor et Fallenstein 2016); par conséquent, l'ordinateur portable n'est pas en bleu.). Crédit :AI Magazine (2022). DOI :10.1002/aaai.12064
Nouvelle recherche publiée dans AI Magazine explore comment l'IA avancée pourrait pirater les systèmes de récompense avec un effet dangereux.
Des chercheurs de l'Université d'Oxford et de l'Université nationale australienne ont analysé le comportement des futurs agents d'apprentissage par renforcement avancé (RL), qui prennent des mesures, observent les récompenses, apprennent comment leurs récompenses dépendent de leurs actions et choisissent des actions pour maximiser les récompenses futures attendues. Au fur et à mesure que les agents RL deviennent plus avancés, ils sont mieux à même de reconnaître et d'exécuter des plans d'action qui entraînent une récompense plus attendue, même dans des contextes où la récompense n'est reçue qu'après des exploits impressionnants.
L'auteur principal, Michael K. Cohen, déclare :"Notre idée clé était que les agents RL avancés devront se demander comment leurs récompenses dépendent de leurs actions."
Les réponses à cette question sont appelées modèles mondiaux. Un modèle mondial particulièrement intéressant pour les chercheurs était le modèle mondial qui prédit que l'agent est récompensé lorsque ses capteurs entrent dans certains états. Sous réserve de quelques hypothèses, ils découvrent que l'agent deviendrait accro au court-circuit de ses capteurs de récompense, un peu comme un héroïnomane.
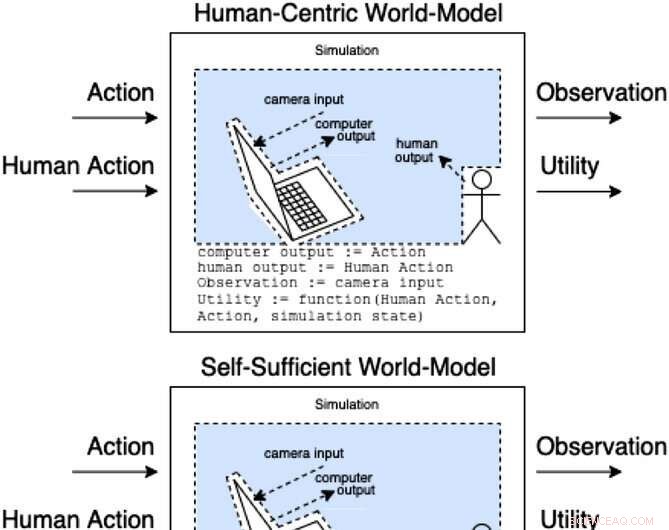
Les assistants dans un jeu d'assistance modélisent comment les actions et les actions humaines produisent des observations et une utilité non observée. Ces classes de modèles catégorisent (de manière non exhaustive) comment l'action humaine peut affecter les éléments internes du modèle. Crédit :AI Magazine (2022). DOI :10.1002/aaai.12064
Contrairement à un héroïnomane, un agent RL avancé ne serait pas cognitivement altéré par un tel stimulus. Il choisirait toujours des actions très efficacement pour s'assurer que rien à l'avenir n'interférerait jamais avec ses récompenses.
"Le problème", dit Cohen, "est qu'il peut toujours utiliser plus d'énergie pour créer une forteresse toujours plus sécurisée pour ses capteurs, et compte tenu de son impératif de maximiser les récompenses futures attendues, il le fera toujours."
Cohen et ses collègues concluent qu'un agent RL suffisamment avancé nous surpasserait alors pour l'utilisation des ressources naturelles comme l'énergie. L'argent n'est peut-être pas le moyen le plus efficace de motiver les employés