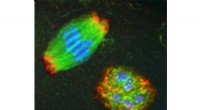
Des chercheurs du Smithsonian classent des feuilles d'herbier numérisées qui ont été colorées au mercure pour créer un ensemble de données de formation. Crédit :Paul B. Frandsen, Smithsonian
Des millions, sinon des milliards, des spécimens se trouvent dans les collections d'histoire naturelle du monde, mais la plupart d'entre eux n'ont pas été soigneusement étudiés, ou même regardé, en décennies. Tout en contenant des données critiques pour de nombreuses entreprises scientifiques, la plupart des objets sont tranquillement assis dans leurs propres petits cabinets de curiosité.
Ainsi, La numérisation de masse des collections d'histoire naturelle est devenue un objectif majeur des musées du monde entier. Ayant réuni de nombreux biologistes, conservateurs, bénévoles et citoyens scientifiques, de telles initiatives ont déjà généré de grands ensembles de données à partir de ces collections et ont fourni des informations sans précédent.
Maintenant, une étude, récemment publié en libre accès Journal de données sur la biodiversité , suggère que les dernières avancées en matière de numérisation et d'apprentissage automatique pourraient, ensemble, aider les conservateurs de musées dans leurs efforts pour prendre soin de cette incroyable ressource mondiale et en tirer des enseignements.
Une équipe de chercheurs du Smithsonian Department of Botany, Laboratoire de science des données, et le bureau du programme de numérisation ont récemment collaboré avec NVIDIA pour mener à bien un projet pilote utilisant des approches d'apprentissage en profondeur pour creuser dans des spécimens d'herbier numérisés.
Leur étude est parmi les premières à décrire l'utilisation de méthodes d'apprentissage en profondeur pour améliorer notre compréhension des échantillons de collection numérisés. C'est également le premier à démontrer qu'un réseau de neurones convolutifs profonds - un système informatique modelé sur l'activité des neurones dans le cerveau des animaux qui peut essentiellement apprendre par lui-même - peut efficacement différencier des plantes similaires avec une précision étonnante de près de 100 %.

L'Herbier national américain au Musée national d'histoire naturelle du Smithsonian à Washington, Crédit D.C. :Chip Clark, Smithsonian
Dans le journal, les scientifiques décrivent deux réseaux neuronaux différents qu'ils ont entraînés pour effectuer des tâches sur la partie numérisée (actuellement 1,2 million de spécimens) de l'Herbier national des États-Unis.
L'équipe a d'abord formé un filet pour reconnaître automatiquement les feuilles d'herbier qui avaient été colorées avec des cristaux de mercure, puisque le mercure était couramment utilisé par certains des premiers collectionneurs pour protéger les collections de plantes contre les dommages causés par les insectes. Le deuxième filet a été formé pour faire la distinction entre deux familles de plantes qui partagent une apparence superficielle étonnamment similaire.
Les réseaux neuronaux entraînés ont fonctionné avec une précision de 90% et 96% respectivement (ou 94% et 99% si les spécimens les plus difficiles ont été rejetés), confirmant que l'apprentissage en profondeur est une technologie utile et importante pour l'analyse future des collections numérisées des musées.

Les collections numérisées combinées à l'apprentissage en profondeur nous aideront à automatiser une tâche autrement humaine consistant à identifier un nombre inconnu de feuilles de spécimens colorées dans une collection de plus de 5 millions. Voir http://collections.si.edu. Crédit :Smithsonian Institution
« Les résultats peuvent être exploités à la fois pour améliorer la conservation et ouvrir de nouvelles voies de recherche, " concluent les scientifiques.
"Ce document de recherche est une merveilleuse preuve de concept. Nous savons maintenant que nous pouvons appliquer l'apprentissage automatique à des spécimens d'histoire naturelle numérisés pour résoudre des problèmes de conservation et d'identification. L'avenir utilisera ces outils combinés à de grands ensembles de données partagés pour tester des hypothèses fondamentales sur l'évolution et la distribution des plantes et des animaux, " dit le Dr Laurence J. Dorr, Président du Smithsonian Department of Botany et co-auteur de l'étude.