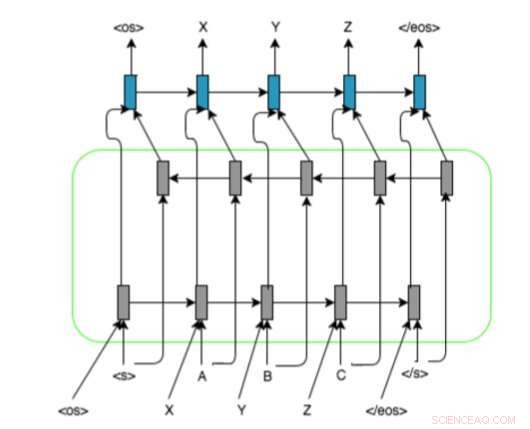
L'architecture de modèle basée sur RNN des chercheurs avec LSTM bidirectionnel encodeur-décodeur et représentation d'alignement sur les séquences d'entrée. Ils utilisent et , , et des marqueurs pour remplir les séquences graphème/phonème à une longueur fixe. Crédit :Ngoc Tan Le et al.
Une équipe de chercheurs de l'Université du Québec à Montréal et de l'Université nationale du Vietnam Ho Chi Minh (VNU-HCM) a récemment développé une approche de translittération automatique basée sur les réseaux de neurones récurrents (RNN). La translittération implique la traduction phonétique de mots dans une langue source donnée (par exemple le français) en mots équivalents dans une langue cible (par exemple le vietnamien).
Par translittération, un mot individuel est transformé en un mot phonétiquement équivalent dans un autre système d'écriture. Cette transformation repose généralement sur un vaste ensemble de règles définies par les linguistes, qui déterminent comment les phonèmes sont alignés, considérant l'origine d'un mot et le système phonologique de la langue cible.
Dans les années récentes, les chercheurs ont développé plusieurs approches d'apprentissage en profondeur pour la traduction automatique, qui se sont avérées être une alternative intéressante aux approches statistiques existantes. Ces résultats prometteurs ont motivé l'équipe de chercheurs de l'Université du Québec à Montréal et de VNU-HCM à développer une approche d'apprentissage en profondeur pour la translittération automatique.
Leur approche utilise des réseaux de neurones récurrents (RNN), car ils se sont avérés particulièrement utiles pour traiter des problèmes similaires. Les chercheurs ont observé que la plupart des méthodes de pointe graphème-phonème étaient principalement basées sur l'utilisation de mappages graphème-phonème, tandis que les RNN ne nécessitent aucune information d'alignement.
« Les modèles graphème-phonème sont des composants clés des systèmes de reconnaissance vocale automatique et de synthèse vocale, " les chercheurs ont expliqué dans leur article, qui a été publié sur ACM Digital Library. "Avec des paires de langues à faibles ressources qui n'ont pas de lexiques de prononciation disponibles et bien développés, les modèles graphème-phonème sont particulièrement utiles. Ces modèles sont basés sur des alignements initiaux entre la source du graphème et les séquences cibles du phonème."
Dans leur étude, les chercheurs ont introduit une nouvelle méthode pour réaliser une translittération par machine à faibles ressources, qui utilise des modèles basés sur RNN et des informations d'alignement pour les séquences d'entrée. Étant donné un mot dans une langue donnée qui n'est pas présent dans le dictionnaire de prononciation bilingue, leur système peut prédire automatiquement sa représentation phonémique dans la langue cible.
« Inspiré par les méthodes de traduction récurrentes basées sur les réseaux de neurones de séquence à séquence, la recherche actuelle présente une approche qui applique une représentation d'alignement pour des séquences d'entrée et des inclusions source et cible pré-entraînées pour surmonter le problème de translittération pour une paire de langues à faibles ressources, " expliquent les chercheurs dans leur article.
Cette nouvelle approche combine plusieurs techniques d'apprentissage en profondeur et de réseaux de neurones, y compris les encodeurs-décodeurs, mécanismes d'attention, représentation d'alignement pour les séquences d'entrée et les incorporations source et cible pré-entraînées. Les chercheurs ont évalué leur méthode dans une tâche de translittération impliquant des paires de langues français-vietnamien à faibles ressources, obtenir des résultats très prometteurs.
"L'évaluation et les expérimentations impliquant le français et le vietnamien ont montré qu'avec seulement un petit dictionnaire de prononciation bilingue disponible pour l'apprentissage des modèles de translittération, des résultats prometteurs ont été obtenus, ", ont écrit les chercheurs.
Selon les chercheurs, leur étude a été parmi les premières à analyser la langue vietnamienne dans une tâche de translittération à l'aide de RNN. Leur méthode a obtenu des résultats remarquables, surpassant les autres approches de pointe basées sur les statistiques et les séquences multijointes.
Le nouveau système conçu par les chercheurs peut apprendre efficacement et automatiquement les régularités linguistiques à partir de petits dictionnaires de prononciation bilingues. Bien que leur étude l'ait spécifiquement appliqué aux tâches de translittération français-vietnamien, elle pourrait également être étendue à toute autre paire de langues à faibles ressources pour lesquelles un dictionnaire de prononciation bilingue est disponible.
« Dans les travaux futurs, nous avons l'intention de tester notre approche proposée avec un plus grand dictionnaire de prononciation bilingue ainsi que d'étudier d'autres approches, tels que semi-supervisé ou non-supervisé, ", ont écrit les chercheurs dans leur article. "Nous avons également l'intention d'étudier l'apprentissage par transfert à l'aide d'autres tâches ou langages de la PNL dans des environnements à faibles ressources."
© 2019 Réseau Science X