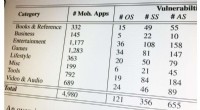
Quelles sont les bases de données secondaires?
Les bases de données secondaires sont des collections d'informations pré-calculées dérivées de sources de données biologiques primaires. Ils sont conçus pour fournir des informations et faciliter des analyses qui seraient difficiles ou qui prendront du temps à obtenir directement à partir de données brutes.
Caractéristiques clés:
* dérivé des données primaires: Ils sont construits par le traitement et l'intégration des données des bases de données primaires (par exemple, les bases de données de séquence comme GenBank).
* organisé et structuré: Les informations sont organisées en catégories et formats spécifiques, ce qui facilite la recherche et l'analyse.
* Informations sur la valeur ajoutée: Ils offrent des annotations, des prédictions et des interprétations basées sur les données primaires, fournissant des informations plus profondes.
Exemples de bases de données secondaires:
Voici une sélection de bases de données secondaires, classées par leur objectif:
* Analyse de séquence et annotation:
* Uniprot: Séquence des protéines et informations fonctionnelles.
* Interpro: Familles de protéines, domaines et sites fonctionnels.
* Go (Gene Ontology): Classification hiérarchique de la fonction des gènes.
* kegg: Voies métaboliques et fonctions des gènes.
* pfam: Familles de protéines.
* Expression du génome et des gènes:
* Ensembl: Assemblages du génome, annotations des gènes et données d'expression génique.
* Navigateur du génome UCSC: Visualisation et exploration des données génomiques.
* geo (omnibus d'expression du gène): Référentiel de données de séquençage ADN et ARN.
* ArrayExpress: Référentiel de données de puces à ADN.
* Interactions et réseaux protéine-protéine:
* chaîne: Interactions et réseaux protéiques-protéine.
* biogride: Interactions protéine-protéine et interactions génétiques.
* Découverte de médicaments et identification cible:
* Drugbank: Base de données complète des informations sur les médicaments.
* chembl: Les molécules de type médicament et leurs activités biologiques.
* PubChem: Structures chimiques et activités biologiques.
* génomique et évolution comparative:
* NCBI Taxonomy Browser: Classification hiérarchique des organismes.
* Phylotree: Arbres phylogénétiques des organismes.
* TreeBase: Référentiel d'arbres phylogénétiques.
Avantages des bases de données secondaires:
* Sage de temps: Ils fournissent des informations prétraitées et organisées, faisant gagner du temps et des efforts aux chercheurs.
* Analyse améliorée: Les annotations, les prédictions et les relations facilitent les analyses et la compréhension plus profondes.
* Intégration de diverses données: Les bases de données secondaires intègrent souvent des informations provenant de plusieurs sources, fournissant une vue complète.
* Formats standardisés: Les données sont généralement présentées dans des formats standardisés, favorisant la cohérence et la compatibilité.
Choisir la bonne base de données:
Le choix de la base de données secondaire dépend de votre question de recherche et de votre type de données spécifiques. Considérez ce qui suit:
* Type de données: Séquences protéiques, données génomiques, expression des gènes, etc.
* Scope: Organismes spécifiques, voies, maladies ou domaines biologiques plus larges.
* Informations nécessaires: Annotations, prédictions, interactions, etc.
* Qualité et fiabilité des données: Assurez-vous que la base de données est bien entretenue et fournit des informations précises.
en résumé:
Les bases de données secondaires sont essentielles pour la recherche bioinformatique. Ils fournissent des informations, des annotations et des idées pré-rémunérées précieuses, facilitant une analyse et une compréhension efficaces des données. Choisissez la bonne base de données en fonction de vos besoins de recherche et tirez parti de son potentiel de découvertes significatives.