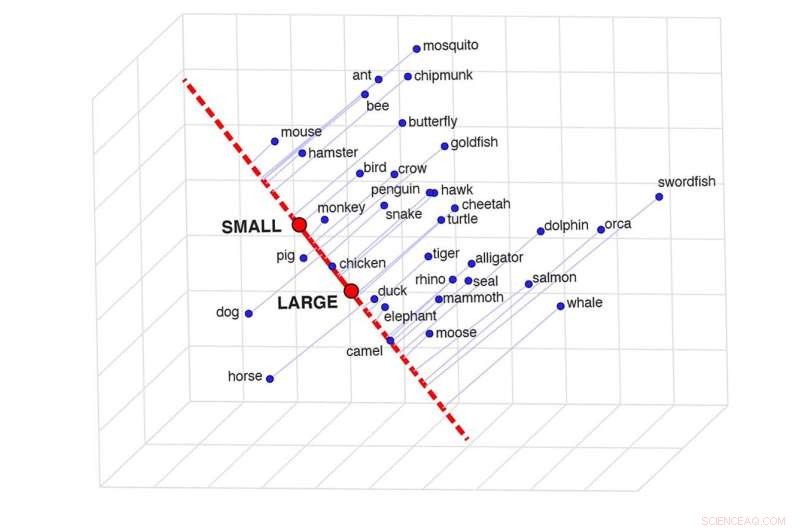
Une représentation de la projection sémantique, qui peut déterminer la similitude entre deux mots dans un contexte spécifique. Cette grille montre à quel point certains animaux sont similaires en fonction de leur taille. Crédit :Idan Blank/UCLA
Dans "De l'autre côté du miroir", Humpty Dumpty dit avec mépris :"Quand j'utilise un mot, cela signifie exactement ce que je veux qu'il signifie, ni plus ni moins." Alice répond:"La question est de savoir si vous pouvez faire en sorte que les mots signifient tant de choses différentes."
L'étude de la signification réelle des mots est ancienne. L'esprit humain doit analyser un réseau d'informations détaillées et flexibles et utiliser un bon sens sophistiqué pour percevoir leur signification.
Maintenant, un nouveau problème lié à la signification des mots est apparu :les scientifiques étudient si l'intelligence artificielle peut imiter l'esprit humain pour comprendre les mots comme les gens le font. Une nouvelle étude menée par des chercheurs de l'UCLA, du MIT et des National Institutes of Health aborde cette question.
L'article, publié dans la revue Nature Human Behaviour , rapporte que les systèmes d'intelligence artificielle peuvent en effet apprendre des significations de mots très compliquées, et les scientifiques ont découvert une astuce simple pour extraire cette connaissance complexe. Ils ont découvert que le système d'IA qu'ils ont étudié représente la signification des mots d'une manière fortement corrélée au jugement humain.
Le système d'IA étudié par les auteurs a été fréquemment utilisé au cours de la dernière décennie pour étudier le sens des mots. Il apprend à comprendre le sens des mots en « lisant » des quantités astronomiques de contenu sur Internet, comprenant des dizaines de milliards de mots.
Lorsque des mots apparaissent fréquemment ensemble - "table" et "chaise", par exemple - le système apprend que leurs significations sont liées. Et si des paires de mots apparaissent très rarement ensemble, comme "table" et "planète", il apprend qu'ils ont des significations très différentes.
Cette approche semble être un point de départ logique, mais considérez à quel point les humains comprendraient le monde si la seule façon de comprendre le sens était de compter la fréquence à laquelle les mots se produisent les uns à côté des autres, sans aucune capacité à interagir avec les autres et notre environnement.
Idan Blank, professeur adjoint de psychologie et de linguistique à l'UCLA et co-auteur principal de l'étude, a déclaré que les chercheurs ont cherché à savoir ce que le système sait des mots qu'il apprend et quel type de "bon sens" il possède. P>
Avant le début de la recherche, a déclaré Blank, le système semblait avoir une limitation majeure :"En ce qui concerne le système, tous les deux mots n'ont qu'une seule valeur numérique qui représente à quel point ils sont similaires."
En revanche, la connaissance humaine est beaucoup plus détaillée et complexe.
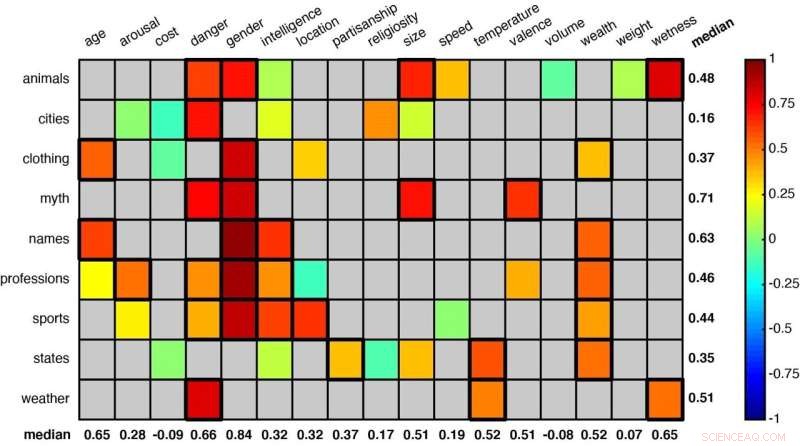
Une grille représentant certaines des catégories de mots analysées par les chercheurs. Les associations statistiquement significatives (comme « animaux » et « danger » et « animaux » et « sexe » dans la première ligne) sont indiquées par des carrés avec une bordure plus épaisse. Crédit :Idan Blank/UCLA
"Considérez notre connaissance des dauphins et des alligators", a déclaré Blank. "Lorsque nous comparons les deux sur une échelle de taille, de "petit" à "grand", ils sont relativement similaires. En termes d'intelligence, ils sont quelque peu différents. En termes de danger qu'ils représentent pour nous, à une échelle de « sûr » à « dangereux », ils diffèrent considérablement. La signification d'un mot dépend donc du contexte.
"Nous voulions demander si ce système connaît réellement ces différences subtiles, si son idée de similitude est flexible de la même manière qu'elle l'est pour les humains."
Pour le savoir, les auteurs ont développé une technique qu'ils appellent "projection sémantique". On peut tracer une ligne entre les représentations du modèle des mots "grand" et "petit", par exemple, et voir où les représentations des différents animaux se situent sur cette ligne.
En utilisant cette méthode, les scientifiques ont étudié 52 groupes de mots pour voir si le système pouvait apprendre à trier les significations, comme juger les animaux en fonction de leur taille ou de leur dangerosité pour les humains, ou classer les États américains en fonction de la météo ou de la richesse globale.
Parmi les autres groupes de mots figuraient des termes liés aux vêtements, aux professions, aux sports, aux créatures mythologiques et aux prénoms. Chaque catégorie a été associée à plusieurs contextes ou dimensions :taille, danger, intelligence, âge et vitesse, par exemple.
Les chercheurs ont constaté que, à travers ces nombreux objets et contextes, leur méthode s'est avérée très similaire à l'intuition humaine. (Pour faire cette comparaison, les chercheurs ont également demandé à des cohortes de 25 personnes chacune de faire des évaluations similaires sur chacun des 52 groupes de mots.)
Remarquablement, le système a appris à percevoir que les noms "Betty" et "George" sont similaires en termes d'être relativement "vieux", mais qu'ils représentaient des sexes différents. Et que "l'haltérophilie" et "l'escrime" sont similaires dans la mesure où les deux se déroulent généralement à l'intérieur, mais diffèrent en termes de niveau d'intelligence requis.
"C'est une méthode magnifiquement simple et complètement intuitive", a déclaré Blank. "La ligne entre 'grand' et 'petit' est comme une échelle mentale, et nous plaçons les animaux sur cette échelle."
Blank a déclaré qu'il ne s'attendait pas à ce que la technique fonctionne, mais qu'il a été ravi lorsqu'elle l'a fait.
"Il s'avère que ce système d'apprentissage automatique est beaucoup plus intelligent que nous ne le pensions; il contient des formes de connaissances très complexes, et ces connaissances sont organisées dans une structure très intuitive", a-t-il déclaré. "Juste en gardant une trace des mots qui coexistent dans le langage, vous pouvez en apprendre beaucoup sur le monde."
Les co-auteurs de l'étude sont Evelina Fedorenko, neuroscientifique cognitive du MIT, Gabriel Grand, étudiant diplômé du MIT, et Francisco Pereira, qui dirige l'équipe d'apprentissage automatique à l'Institut national de la santé mentale des National Institutes of Health.