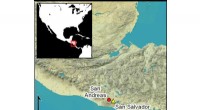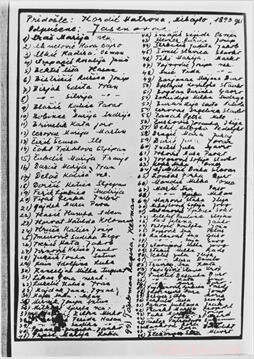
L'un des plus de 7, 000 listes de noms de camps de concentration au US Holocaust Memorial Museum. Celui-ci est une liste manuscrite de femmes serbes et croates qui ont été déportées vers le camp de concentration de Jasenovac. Crédit : Musée mémorial de l'Holocauste des États-Unis
Melkior Ornik, membre de la faculté de génie aérospatial, est également mathématicien, un passionné d'histoire, et un fervent partisan de l'intégrité lorsqu'il s'agit d'utiliser la science dure dans les discussions publiques. Donc, lorsqu'une histoire est apparue dans son fil d'actualité à propos d'une paire de chercheurs qui ont développé une méthode statistique pour analyser des ensembles de données et l'ont utilisée pour prétendument réfuter le nombre de victimes de l'Holocauste dans un camp de concentration en Croatie, cela a naturellement attiré son attention.
Ornik est professeur au Département de génie aérospatial de l'Université de l'Illinois à Urbana-Champaign. Il a ensuite étudié la recherche en profondeur et a utilisé la méthode pour réanalyser les mêmes données du United States Holocaust Memorial Museum. Puis il a écrit un article de réfutation démystifiant les découvertes des chercheurs.
La réfutation d'Ornik est publiée dans le même journal que l'article original. Il a déclaré que l'éditeur lui avait demandé d'inclure une liste de réponses à certaines des questions potentielles que d'autres scientifiques pourraient se poser lorsqu'ils liraient son article. Quelques semaines plus tard, le journal a placé une note sur l'article original indiquant qu'ils n'approuvent pas ou ne partagent pas les points de vue des auteurs, et recommandé la lecture de l'article d'Ornik.
"En tant que scientifiques, en tant qu'ingénieurs, Je pense qu'il est de notre devoir de corriger la science imparfaite et défectueuse, " a déclaré Ornik. " Il y a tellement d'efforts pour amener le public et les décideurs à croire en la science, que lorsqu'un expert en mathématiques dit qu'il a la preuve, cela donne du crédit à l'argument. Mais lorsque leurs affirmations sont manifestement fausses, ce n'est pas bon pour la science et ce n'est pas bon pour la société. C'est pourquoi il est particulièrement important que les scientifiques contestent les fausses découvertes lorsque nous les découvrons. »
Selon Ornik, certaines personnes promeuvent l'idée que les camps de concentration n'existaient pas ou n'étaient pas utilisés pour tuer des gens, ou que le nombre de victimes actuellement largement accepté a été considérablement gonflé. La plupart des historiens ne prennent pas les affirmations au sérieux à la lumière des vastes données et preuves disponibles.
« Pour les auteurs de l'article original, prétendre qu'ils ont trouvé une preuve mathématique que la liste des victimes de ce camp a été fabriquée a des implications historiques évidentes, " dit Ornik. " Je pense, dans une certaine mesure le mal est déjà fait, mais j'ai ressenti le besoin d'enregistrer les hypothèses, inexactitudes, et l'utilisation abusive des données brutes du musée que j'ai trouvées dans la recherche originale."
L'article auquel Ornik a répondu présente une nouvelle méthode pour identifier les anomalies sur un ensemble d'histogrammes. Ornik a déclaré qu'il ne contestait pas les mérites de la méthode présentée dans l'article original, juste son application au camp de concentration de Jasenovac.
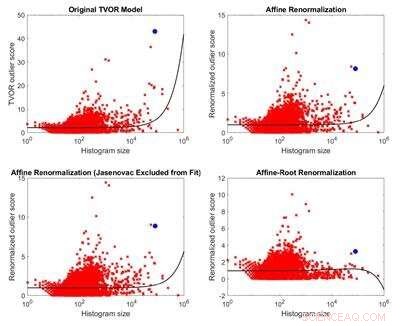
Comparaison du modèle original d'identification des valeurs aberrantes et de trois modèles dérivés de celui-ci. En raison de l'inapplicabilité de ses hypothèses à l'ensemble de données considéré, le modèle original n'a aucun fondement théorique. Trois modèles alternatifs sont moins biaisés en termes de taille que le modèle original et produisent des résultats opposés. Crédit :Melkior Ornik
Ornik s'est méfié des conclusions de l'article parce que les chercheurs ont laissé entendre dans un cas qu'une liste plus petite avait naturellement un score aberrant plus petit, mais ils ont comparé les scores de toutes les tailles de listes de victimes pour affirmer que celui lié à Jasenovac, l'un des plus grands, était problématique.
"J'ai commencé à chercher s'il y avait une sorte de biais pour la taille et s'ils étaient en fait plus susceptibles d'attribuer ou non le drapeau d'être problématique à une plus grande liste. Et il s'avère, malgré les affirmations des auteurs, ils étaient, " a déclaré Ornik. " Les listes les plus grandes sont plus susceptibles d'être calculées pour être problématiques que les listes plus petites lorsque leur méthode est appliquée aux données. "
Ornik, qui utilise couramment des analyses statistiques similaires dans les applications aérospatiales, expliqué une autre raison pour laquelle leur argument statistique ne fonctionne pas.
« Quand vous regardez les données, une collection de n'importe quoi, et vous voulez découvrir une valeur aberrante - quelque chose de différent - vous devez supposer que toutes les données proviennent de la même source, la même répartition. Faites une liste des victimes par année de naissance. Cela donnerait un graphique de l'âge de chaque personne. Disons que 10 pour cent ont plus de 70 ans. Maintenant, cette distribution ne serait pas vraie pour une liste d'enfants déportés, par exemple, parce que cette liste, par définition, est structurellement différent. Elle est également différente d'une liste de tous ceux qui ont une carte d'identité. Les cartes d'identité ne sont délivrées qu'aux personnes qui ne sont pas des enfants. Encore, les listes avec lesquelles ces chercheurs ont travaillé proviennent d'une multitude de sources et comprennent des listes d'enfants, listes de personnes qui se marient, listes de prisonniers de guerre, choses qui, par définition, ne peuvent pas provenir de la même distribution.
Une autre erreur majeure dans le papier original, Ornik a dit, est que certaines listes en double ont été traitées comme deux listes distinctes. Cela signifiait qu'environ 67 pour cent de l'ensemble de leur base de données étaient en fait des sous-listes de la plus grande liste.
"Le 7, Plus de 000 listes publiées en ligne par le Musée de l'Holocauste ne sont pas conservées, " dit Ornik. " Par exemple, il y a deux listes qui contiennent exactement les mêmes données; l'un est en cyrillique et l'autre utilise l'alphabet latin. Mais ils les ont traités comme deux listes distinctes. Il existe d'autres listes qui contiennent le même nom, mais il n'y a aucun moyen de savoir s'il s'agit de la même personne ou de deux personnes différentes nées le même jour avec des noms identiques. Ils auraient pu supprimer les erreurs très flagrantes dans lesquelles une liste est clairement dupliquée mais le reste, vous auriez besoin d'accéder aux données historiques d'origine."
Le papier original et le papier d'Ornik, "Commentez sur 'TVOR:Trouver des valeurs aberrantes de variation totale discrète parmi les histogrammes, '" sont publiés dans Accès IEEE .