Les chercheurs ont utilisé l'apprentissage automatique pour créer le premier étude axée sur les données pour éclairer comment la culture affecte le sens des mots. Crédit :Peinture de la Tour de Babel de Pieter Bruegel l'Ancien, Kunsthistorisches Museum Wien, Vienne, L'Autriche
Qu'entendons-nous par le mot beau ? Cela dépend non seulement de qui vous demandez, mais dans quelle langue vous leur demandez. Selon une analyse d'apprentissage automatique de dizaines de langues menée à l'Université de Princeton, le sens des mots ne renvoie pas nécessairement à un intrinsèque, constante essentielle. Au lieu, il est fortement façonné par la culture, histoire et géographie. Ce constat est vrai même pour certains concepts qui semblent universels, comme les émotions, caractéristiques du paysage et parties du corps.
"Même pour les mots de tous les jours qui, selon vous, signifient la même chose pour tout le monde, il y a toute cette variabilité là-bas, " dit William Thompson, chercheur postdoctoral en informatique à l'Université de Princeton, et auteur principal des conclusions, Publié dans Nature Comportement Humain 10 août. "Nous avons fourni la première preuve fondée sur des données que la façon dont nous interprétons le monde à travers les mots fait partie de notre héritage culturel."
La langue est le prisme à travers lequel nous conceptualisons et comprenons le monde, et les linguistes et les anthropologues ont longtemps cherché à démêler les forces complexes qui façonnent ces systèmes de communication critiques. Mais les études qui tentent de répondre à ces questions peuvent être difficiles à mener et prendre du temps, impliquant souvent de longs, entretiens minutieux avec des locuteurs bilingues qui évaluent la qualité des traductions. « Cela peut prendre des années et des années pour documenter une paire de langues spécifique et les différences entre elles, " a déclaré Thompson. " Mais des modèles d'apprentissage automatique ont récemment émergé qui nous permettent de poser ces questions avec un nouveau niveau de précision. "
Dans leur nouveau papier, Thompson et ses collègues Seán Roberts de l'Université de Bristol, ROYAUME-UNI., et Gary Lupyan de l'Université du Wisconsin, Madison, a exploité la puissance de ces modèles pour analyser plus de 1, 000 mots dans 41 langues.
Au lieu d'essayer de définir les mots, la méthode à grande échelle utilise le concept « d'associations sémantiques, " ou simplement des mots qui ont une relation significative les uns avec les autres, que les linguistes trouvent être l'une des meilleures façons de définir un mot et de le comparer à un autre. Associés sémantiques de « beau, " par exemple, inclure "coloré, " "amour, " "précieux" et "délicat".
Les chercheurs ont construit un algorithme qui a examiné les réseaux de neurones formés sur différentes langues pour comparer des millions d'associations sémantiques. L'algorithme a traduit les associés sémantiques d'un mot particulier dans une autre langue, puis répétez le processus dans l'autre sens. Par exemple, l'algorithme a traduit les associés sémantiques de « beautiful » en français, puis a traduit les associés sémantiques de beau en anglais. Le score de similarité final de l'algorithme pour la signification d'un mot est venu de la quantification de l'alignement de la sémantique dans les deux sens de la traduction.
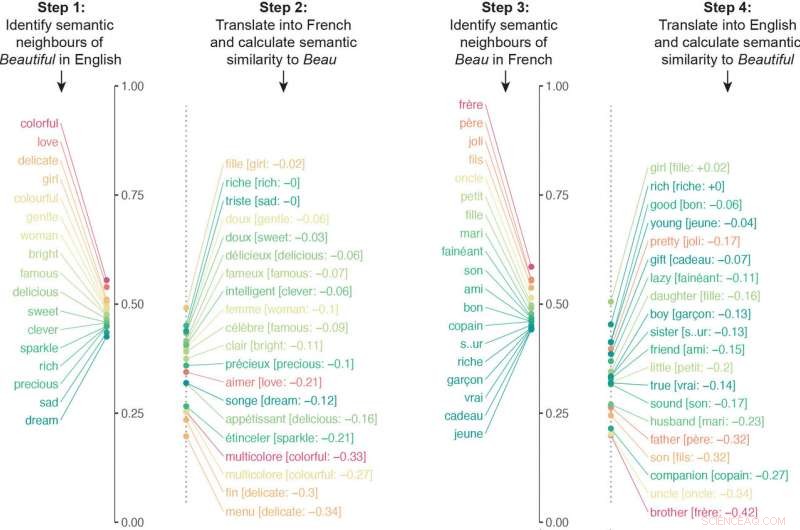
L'algorithme a traduit les associés sémantiques d'un mot particulier dans une autre langue, puis répétez le processus dans l'autre sens. Dans cet exemple, les voisins sémantiques de « beau » ont été traduits en français puis les voisins sémantiques de « beau » ont été traduits en anglais. Les listes respectives étaient substantiellement différentes en raison de différentes associations culturelles. Image reproduite avec l'aimable autorisation des chercheurs. Crédit :Université de Princeton
« Une façon de voir ce que nous avons fait est de quantifier, à partir de données, quels mots sont les plus traduisibles, ", a déclaré Thompson.
Les résultats ont révélé qu'il existe des mots presque universellement traduisibles, principalement ceux qui font référence à des nombres, les professions, quantités, dates du calendrier et parenté. Beaucoup d'autres types de mots, cependant, y compris ceux qui se référaient aux animaux, nourriture et émotions, étaient beaucoup moins bien assortis dans le sens.
Dans une dernière étape, les chercheurs ont appliqué un autre algorithme qui comparait à quel point les cultures qui ont produit les deux langues sont similaires, basé sur un ensemble de données anthropologiques comparant des choses comme les pratiques matrimoniales, systèmes juridiques et organisation politique des locuteurs d'une langue donnée.
Les chercheurs ont découvert que leur algorithme pouvait prédire correctement avec quelle facilité deux langues pouvaient être traduites en fonction de la similitude des deux cultures qui les parlent. Cela montre que la variabilité du sens des mots n'est pas seulement aléatoire. La culture joue un rôle important dans la formation des langues - une hypothèse que la théorie prédit depuis longtemps, mais que les chercheurs manquaient de données quantitatives à l'appui.
"C'est un article extrêmement agréable qui fournit une quantification de principe aux problèmes qui ont été au cœur de l'étude de la sémantique lexicale, " a déclaré Damian Blasi, un langagier à l'Université Harvard, qui n'était pas impliqué dans la nouvelle recherche. Bien que l'article ne fournisse pas de réponse définitive à toutes les forces qui façonnent les différences de sens des mots, les méthodes établies par les auteurs sont solides, Blasi a dit, et l'utilisation de plusieurs, sources de données diverses « est un changement positif dans un domaine qui a systématiquement ignoré le rôle de la culture en faveur des universaux mentaux ou cognitifs ».
Thompson a convenu que les découvertes de lui et de ses collègues mettent l'accent sur la valeur de "la conservation d'ensembles de données improbables qui ne sont normalement pas vus dans les mêmes circonstances". Les algorithmes d'apprentissage automatique que lui et ses collègues ont utilisés ont été initialement formés par des informaticiens, tandis que les ensembles de données qu'ils ont alimentés dans les modèles à analyser ont été créés par des anthropologues du 20e siècle ainsi que par des études linguistiques et psychologiques plus récentes. Comme l'a dit Thompson, "Derrière ces nouvelles méthodes fantaisistes, il y a toute une histoire de personnes dans de multiples domaines qui collectent des données que nous rassemblons et examinons d'une toute nouvelle manière."