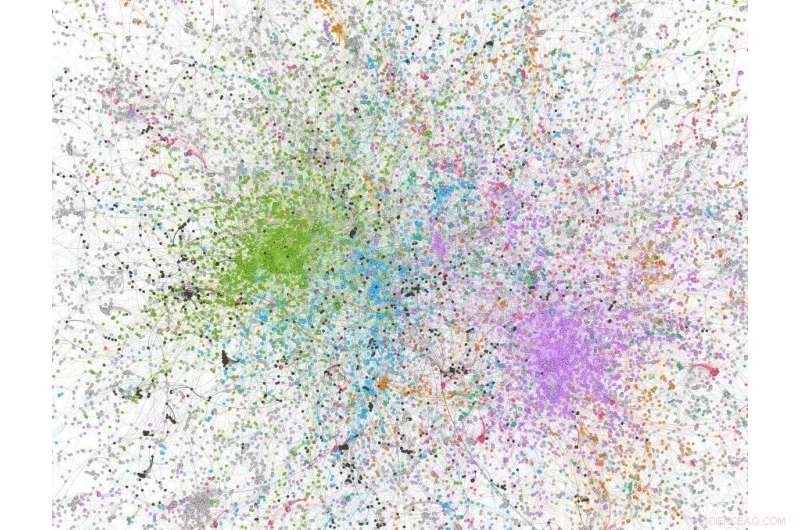
Chiffre d'analyse de réseau dérivé d'un échantillon de 100, 000 tweets avec 'covid' dans le tweet ; les nœuds colorés en vert sont des utilisateurs/organisations Twitter alt-right/fortement conservateurs. Crédit :Dhiraj Murthy, UT Austin
Parmi les innombrables façons dont les chercheurs luttent contre la propagation du coronavirus, étudier les Tweets n'est peut-être pas le premier qui me vient à l'esprit. Mais maintenant, comme lors des crises passées, puiser dans l'un des principaux services de messagerie en temps réel au monde peut aider à identifier de nouveaux points chauds pandémiques, mettre en évidence de nouveaux symptômes, ou interpréter comment les personnes et les communautés réagissent aux ordres de pratiquer la distanciation sociale.
L'équipe d'experts en science des données du Texas Advanced Computing Center (TACC) a facilité l'analyse des médias sociaux dans le passé, et a développé des outils d'apprentissage automatique pour mieux tirer les aiguilles des vastes meules de foin du Twitterverse.
A partir de mars, TACC a commencé à ingérer de grandes quantités de tweets quotidiennement - environ 40 millions de messages, dont un million sont uniques. En combinant leur collection avec des efforts similaires de groupes à UT Austin, l'Université de Californie du Sud, et George State University, ils ont étendu leur collection de tweets liés à COVID-19 jusqu'en janvier. (La semaine dernière, Twitter a annoncé qu'il publierait de nouveaux points de terminaison d'API dans sa propre collection de tweets liés à COVID-19 pour les développeurs et chercheurs approuvés.)
« Il y a un grand intérêt pour ce type de collections. C'est très utile en science des données, " a déclaré Weijia Xu, qui gère le groupe Scalable Computational Intelligence chez TACC.
Aujourd'hui, TACC a annoncé un nouveau référentiel GitHub où les chercheurs intéressés peuvent accéder à la fois à des pointeurs vers des données Twitter brutes liées à COVID-19 et à des analyses à grande échelle facilitées par les superordinateurs de TACC.
La première des analyses disponibles pour les chercheurs est un ensemble de n-grammes :des séquences contiguës de mots à partir d'un échantillon donné de tweets. Le premier 1, 000 un-, deux-, et des séquences de trois mots ont été assemblées pour chaque jour de la pandémie. Assembler ne serait-ce qu'un seul gramme à partir de plusieurs millions de tweets peut prendre jusqu'à une heure sur un ordinateur portable en raison de la quantité de traitement de données impliqué, mais peut être fait en quelques minutes sur les supercalculateurs de TACC.
L'équipe de recherche TACC, dirigé par Xu, a également travaillé sur des analyses de modélisation de sujets, identifier les termes qui apparaissent fréquemment en relation les uns avec les autres, mais pas nécessairement dans l'ordre. Ceux-ci seront ajoutés au référentiel GitHub dans les semaines à venir.
Les deux méthodes de regroupement peuvent être utiles pour identifier les tendances dans la façon dont la pandémie, et la réponse des gens à cela, évoluent.
Les futurs projets utilisant les données comprennent une base de données publique consultable; analyse d'entités :inspecter les tweets à la recherche d'entités connues telles que des personnalités ou des organisations publiques et renvoyer des informations sur ces entités ; et la détection d'événements :détection automatique de l'occurrence d'événements et leur catégorisation.
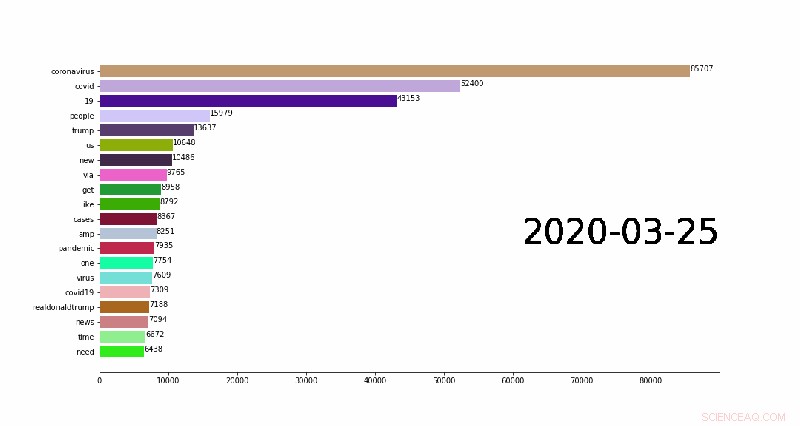
Une animation montrant les 20 meilleurs n-grammes quotidiens (mots courants dans les publications Twitter) changeant au fil du temps. Crédit :Weijia Xu, TACC
Ces efforts seront facilités par des outils développés au TACC, comme le projet Domain Information &Vocabulary Extraction, un effort financé par la National Science Foundation pour extraire des entités biologiques de publications et d'autres documents texte à l'aide de l'apprentissage automatique, qui a été adapté pour d'autres types d'extraction.
L'objectif principal de TACC—ici, comme dans la plupart des choses, est de faciliter la recherche des autres et les découvertes de pouvoir. « Nous sommes principalement intéressés à permettre aux gens d'accéder à des ensembles de données organisés et à les aider à faire des recherches, " dit Xu. " Nous collectons, nettoyer, et le traitement des données afin qu'elles soient prêtes à être utilisées par d'autres."
Des chercheurs de l'Université du Texas à Austin (UT Austin) sont parmi les premiers à exprimer leur intérêt pour l'utilisation des ensembles de données Twitter TACC COVID-19 pour des recherches ciblées.
"The TACC COVID-19 Twitter collection will be invaluable in enabling us to model communication patterns and topics that emerge across stages of the disease, " said Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."














