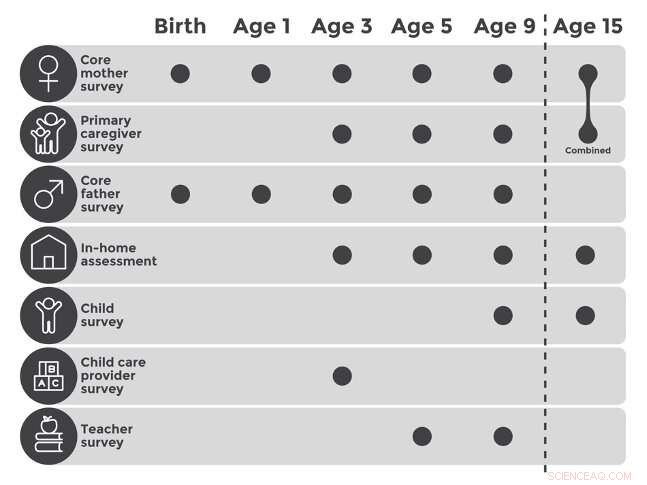
L'étude Fragile Families a recueilli des informations sur les enfants à la naissance et âgés de 1 an. 3, 5, 9 et 15. Cette information a été recueillie à travers une variété d'enquêtes, à gauche de ces âges dans le tableau ci-dessus. Le Fragile Families Challenge a utilisé les données des vagues 1 à 5 pour prédire les résultats de la vague six. Crédit :Matthew Salganik et al. 2020, université de Princeton
Les techniques d'apprentissage automatique utilisées par les scientifiques pour prédire les résultats de grands ensembles de données peuvent être insuffisantes lorsqu'il s'agit de projeter les résultats de la vie des gens, selon une étude de masse menée par des chercheurs de l'Université de Princeton en collaboration avec des chercheurs de nombreuses institutions, dont Virginia Tech.
Cette collaboration de masse, appelé le Fragile Families Challenge, représente une cohorte de scientifiques qui construisent des modèles statistiques et d'apprentissage automatique pour prédire et mesurer les résultats de la vie des enfants, parents, et les ménages à travers les États-Unis.
Publié par 112 co-auteurs dans le Actes de l'Académie nationale des sciences , les résultats suggèrent que les sociologues et les scientifiques des données doivent faire preuve de prudence lors de l'utilisation de la modélisation prédictive, surtout dans le système de justice pénale et les programmes sociaux.
Même après avoir utilisé une modélisation de pointe et un ensemble de données de haute qualité contenant 13, 000 points de données pour plus de 4, 000 familles, les meilleurs modèles prédictifs d'IA n'étaient pas très précis.
Brian J. Goode, un chercheur du Fralin Life Sciences Institute de Virginia Tech, faisait partie des spécialistes des données et des sciences sociales qui ont participé au Fragile Families Challenge.
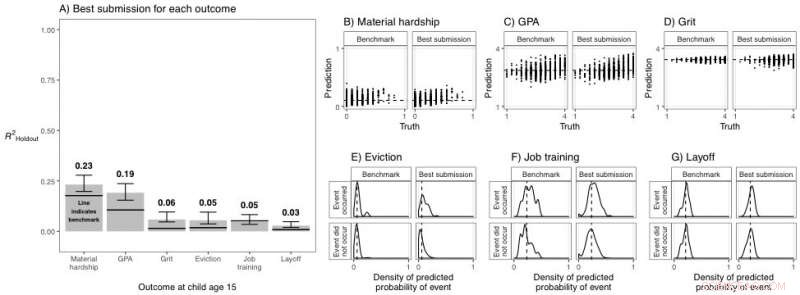
La figure A montre la différence entre les meilleures soumissions pour chaque résultat par rapport au modèle de référence. La figure B-G a comparé les prédictions et la vérité pour chaque résultat. Crédit :Matthew Salganik et al. 2020, université de Princeton
"C'est un effort pour essayer de capturer les complexités et les subtilités qui composent le tissu d'une vie humaine dans les données et les modèles. Mais, il est obligatoire de passer à l'étape suivante et de contextualiser les modèles en termes de comment ils vont être appliqués afin de mieux raisonner sur les incertitudes attendues et les limites d'une prédiction. C'est un problème très difficile à résoudre, et je pense que le Fragile Families Challenge montre que nous avons besoin de plus de soutien à la recherche dans ce domaine, d'autant plus que l'apprentissage automatique a un plus grand impact sur notre vie quotidienne, " a déclaré Goode. La modélisation de Goode a été menée par le Discovery Analytics Center de Virginia Tech. Là, il a fait équipe avec le directeur du Discovery Analytics Center et le Thomas L. Phillips Professor of Engineering, Naren Ramakrishnan, et Debanjan Datta, un doctorat étudiant au département d'informatique de la faculté d'ingénierie, qui ont joué un rôle déterminant dans la collecte et l'analyse des données.
L'équipe de Virginia Tech a également publié des recherches dans un numéro spécial de Socius, une nouvelle revue en libre accès de l'American Sociological Association. Afin de soutenir des recherches supplémentaires dans ce domaine, toutes les soumissions au Challenge—code, prédictions et explications narratives—sont accessibles au public.
"L'étude nous montre aussi que nous avons tant à apprendre, et les collaborations de masse comme celle-ci sont extrêmement importantes pour la communauté de la recherche, " a déclaré le co-auteur principal de l'étude PNAS Matt Salganik, professeur de sociologie à Princeton et directeur par intérim du Center for Information Technology Policy, basé à la Woodrow Wilson School of Public and International Affairs de Princeton.
Le projet a été inspiré par Wikipédia, l'une des premières collaborations de masse au monde, qui a été créé en 2001 comme une encyclopédie partagée. Salganik s'est demandé quels autres problèmes scientifiques pourraient être résolus grâce à une nouvelle forme de collaboration, et c'est alors qu'il s'associe à Sara McLanahan, le professeur William S. Tod de sociologie et d'affaires publiques à Princeton, ainsi que les étudiants diplômés de Princeton Ian Lundberg et Alex Kindel, tous deux au département de sociologie.
McLanahan est chercheur principal de la Fragile Families and Child Wellbeing Study basée à Princeton et à l'Université de Columbia, qui a étudié une cohorte d'environ 5, 000 enfants nés dans les grandes villes américaines entre 1998 et 2000, avec un suréchantillonnage d'enfants nés de parents non mariés. L'étude longitudinale a été conçue pour comprendre la vie des enfants nés dans des familles non mariées.
A travers des enquêtes recueillies en six vagues (à la naissance de l'enfant puis à l'âge de 1 an, 3, 5, 9, et 15), l'étude a capturé des millions de points de données sur les enfants et leurs familles. Une autre vague sera capturée à 22 ans.
Au moment où les chercheurs ont conçu le défi, les données à partir de l'âge de 15 ans (que les chercheurs appellent dans le document les « données à retenir) n'avaient pas encore été rendues publiques. Cela a donné l'occasion de demander à d'autres scientifiques de prédire les résultats de la vie des personnes participant à l'étude grâce à une collaboration de masse.

160 équipes de recherche de données et de spécialistes des sciences sociales ont construit des modèles statistiques et d'apprentissage automatique pour prédire mesurer six résultats de vie pour les enfants, parents, et les ménages. Même après avoir utilisé une modélisation de pointe et un ensemble de données de haute qualité contenant 13, 000 points de données sur plus de 4, 000 familles, les meilleurs modèles prédictifs d'IA n'étaient pas très précis. Crédit :Egan Jimenez, université de Princeton
Les co-organisateurs ont reçu 457 candidatures de 68 institutions du monde entier, y compris de plusieurs équipes basées à Princeton. En utilisant les données des familles fragiles, les participants ont été invités à prédire un ou plusieurs des six résultats de la vie à l'âge de 15 ans. Ceux-ci comprenaient la moyenne pondérée cumulative (MPC) des enfants; grain d'enfant; expulsion du ménage; difficultés matérielles ménagères; mise à pied de l'aidant principal; et la participation de l'aidant principal à la formation professionnelle.
Le challenge était basé sur la méthode des tâches communes, un design de recherche fréquemment utilisé en informatique mais pas en sciences sociales. Cette méthode libère certaines mais pas toutes les données, permettant aux gens d'utiliser la technique qu'ils veulent pour déterminer les résultats. L'objectif est de prédire avec précision les données de rétention, peu importe à quel point une technique sophistiquée est nécessaire pour y arriver.
L'équipe sollicite actuellement des subventions pour poursuivre ses recherches dans ce domaine.
Le papier, « Mesurer la prévisibilité des résultats de la vie avec une collaboration scientifique de masse, " a été publié le 30 mars par PNAS .