Crédit :Université RUDN
Des mathématiciens de l'Université RUDN et de l'Université libre de Berlin ont proposé une nouvelle approche pour étudier les distributions de probabilité des données observées à l'aide de réseaux de neurones artificiels. La nouvelle approche fonctionne mieux avec les valeurs aberrantes, c'est à dire., des objets de données d'entrée qui s'écartent considérablement de l'échantillon global. L'article a été publié dans la revue Intelligence artificielle .
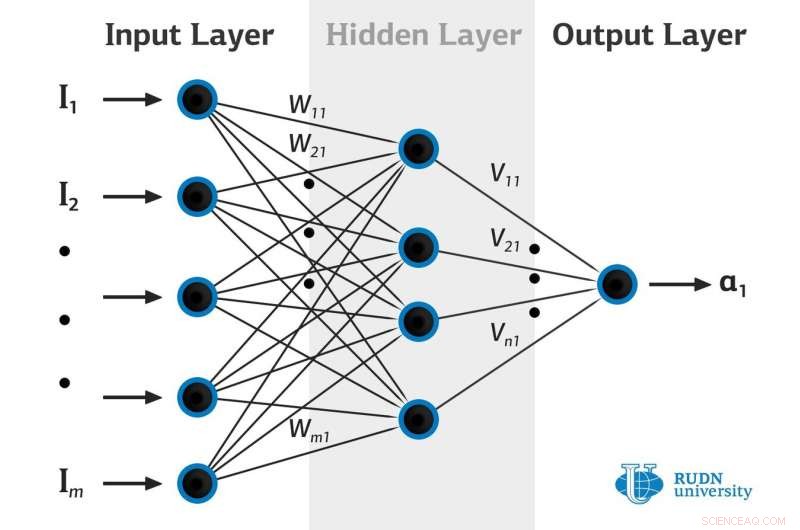
La restauration de la distribution de probabilité des données observées par les réseaux de neurones artificiels est la partie la plus importante de l'apprentissage automatique. La distribution de probabilité permet non seulement de prédire le comportement du système étudié, mais aussi de quantifier l'incertitude avec laquelle les prévisions sont faites. La principale difficulté est que, comme règle, seules les données sont observées, mais leurs distributions exactes de probabilité ne sont pas disponibles. Pour résoudre ce problème, Bayésienne et d'autres méthodes approximatives similaires sont utilisées. Mais leur utilisation augmente la complexité d'un réseau de neurones et rend donc son apprentissage plus compliqué.
Les mathématiciens de l'Université RUDN et de l'Université libre de Berlin ont utilisé des poids déterministes dans les réseaux de neurones, ce qui permettrait de surmonter les limites des méthodes bayésiennes. Ils ont développé une formule qui permet d'estimer correctement la variance de la distribution des données observées. Le modèle proposé a été testé sur différentes données :synthétiques et réelles; sur les données contenant des valeurs aberrantes et sur les données dont les valeurs aberrantes ont été supprimées. La nouvelle méthode permet de restaurer les distributions de probabilité avec une précision jusqu'alors impossible à atteindre.
Les mathématiciens de l'Université RUDN et de l'Université libre de Berlin ont utilisé des poids déterministes pour les réseaux de neurones et ont utilisé les sorties des réseaux pour coder la distribution des variables latentes pour la distribution marginale souhaitée. Une analyse de la dynamique d'apprentissage de tels réseaux leur a permis d'obtenir une formule qui estime correctement la variance des données observées, malgré la présence de valeurs aberrantes dans les données. Le modèle proposé a été testé sur différentes données :synthétiques et réelles. La nouvelle méthode permet de restaurer les distributions de probabilité avec une plus grande précision par rapport aux autres méthodes modernes. La précision a été évaluée à l'aide de la méthode AUC (l'aire sous la courbe est l'aire sous le graphique qui permet d'évaluer l'erreur quadratique moyenne des prédictions en fonction de la taille de l'échantillon estimée par le réseau comme "fiable" ; plus le score AUC est élevé, meilleures sont les prédictions).