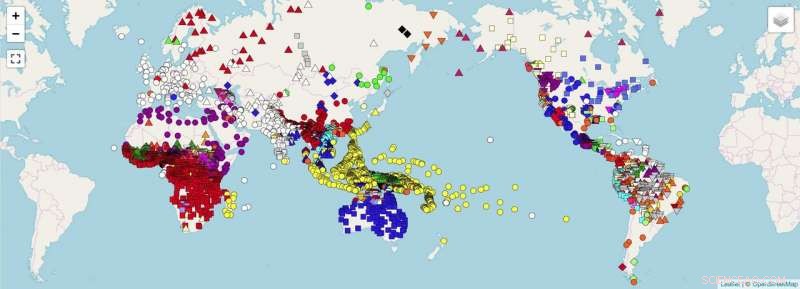
Une carte du monde montrant des points de données, pour lesquels les chercheurs prévoient de recueillir des données unifiées (par exemple, données directement comparables) en utilisant les directives données dans le document. Crédit :OpenStreetMap. Forkel et al. 2018. Formats de données interlinguistiques, faire progresser le partage et la réutilisation des données en linguistique comparée. Données scientifiques .
Une équipe internationale de chercheurs, membres de la Cross-Linguistic Data Formats Initiative (CLDF) dirigée par le Max Planck Institute for the Science of Human History, a proposé de nouvelles lignes directrices sur les formats de données interlinguistiques afin de faciliter le partage et les comparaisons de données entre le nombre croissant de grandes bases de données linguistiques dans le monde. Ce format fournit un progiciel, une ontologie de base et des exemples d'utilisation.
Il existe un nombre croissant de bases de données linguistiques dans le monde, ouvrant la possibilité d'un vaste réseau d'études comparatives potentielles. Cependant, ces bases de données sont généralement créées indépendamment les unes des autres, et ont souvent un objectif unique et étroit. Cela signifie que les formats utilisés pour l'encodage des données sont souvent différents, créant des difficultés dans la comparaison des données entre les bases de données.
La Cross-Linguistic Data Formats Initiative (CLDF) est un effort pour résoudre ces problèmes. Dans un article publié en Données scientifiques , le CLDF propose des orientations pour un format standardisé des bases de données linguistiques, et fournit également un progiciel, une ontologie de base et des exemples d'utilisation des meilleures pratiques. Le but de cet effort est de faciliter le partage et la réutilisation des données en linguistique comparée.
Le CLDF fournit un modèle de données sous-jacent à ses recommandations qui se veut simple, pourtant expressif, et est basé sur le modèle de données précédemment développé pour le projet Cross-Linguistic Data. Ce modèle comporte quatre entités principales :(a) les langues; (b) paramètres; (c) valeurs; et (d) sources. Dans le modèle, chaque valeur est liée à un paramètre et à une langue, et peut être basé sur plusieurs sources. Il y a en plus des références pour les sources, et les références peuvent aussi avoir des contextes (qui, par exemple, pour les références imprimées seraient les numéros de page).
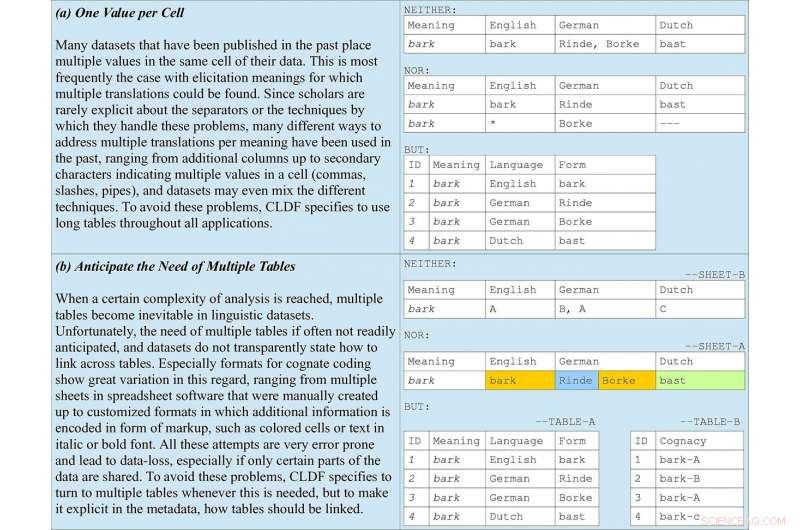
Règles de base de codage des données incluses dans les lignes directrices, en prenant comme exemple le codage apparenté dans les listes de mots. (a) illustre pourquoi les tableaux longs doivent être privilégiés dans toutes les applications. (b) souligne l'importance d'anticiper plusieurs tableaux ainsi que des métadonnées indiquant comment ils doivent être liés. Crédit :Forkel et al. 2018. Formats de données interlinguistiques, faire progresser le partage et la réutilisation des données en linguistique comparée. Données scientifiques .
Le modèle de données CLDF est un format de package dans lequel un ensemble de données serait constitué d'un ensemble de fichiers de données contenant des tableaux, et un fichier descriptif qui définit les relations entre les tables. Chaque type de données linguistiques aurait un module CLDF et des composants supplémentaires, quels seraient les aspects des données du module qui se reproduisent dans plusieurs types de données. Les modules CLDF contiendraient également des termes de l'ontologie CLDF. L'ontologie est une liste de vocabulaire qui représente des objets et des propriétés avec une sémantique bien connue en linguistique comparée. Cela permet aux utilisateurs de référencer ces termes de manière uniforme.
Un progiciel pour permettre la validation et la manipulation
Les spécifications CLDF utilisent des formats de fichiers courants, tels que CSV, JSON et BibTeX—qui sont largement pris en charge, dans le but que ces fichiers puissent être facilement lus et écrits sur de nombreuses plateformes. Plus important encore, le format standardisé permettra aux chercheurs sans compétences en programmation d'accéder et de manipuler les données avec des outils préexistants, pour éviter de restreindre le package aux seuls chercheurs ayant des compétences en programmation suffisantes pour créer leurs propres outils. Pour faciliter cela, le CLDF a créé un référentiel "cookbook" pour les scripts à utiliser avec les spécifications CLDF.
« Nous voulons apporter l'accès à ces données et la possibilité de les comparer à un maximum de chercheurs, " dit Johann-Mattis List de l'Institut Max Planck pour la science de l'histoire humaine. Robert Forkel, l'un des moteurs de l'initiative CLDF, note également que le format CLDF ne se limite pas aux seules données linguistiques, mais peut aussi intégrer des bases de données culturelles et géographiques, par exemple. « CLDF peut faciliter considérablement le test des questions concernant l'interaction entre linguistique, culturel, et les facteurs environnementaux dans l'évolution linguistique et culturelle.