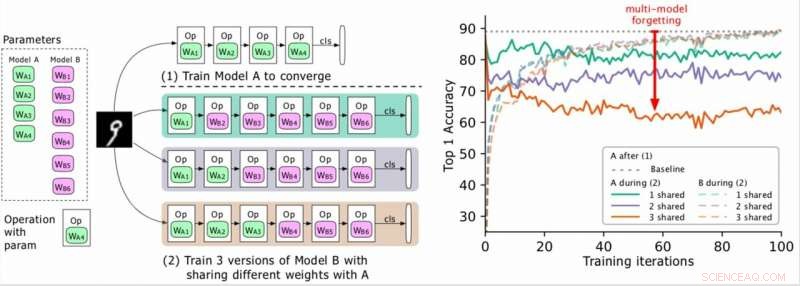
(À gauche) Deux modèles à entraîner (A, B), où les paramètres de A sont en vert et B en violet, et B partage certains paramètres avec A (indiqué en vert pendant la phase 2). Les chercheurs entraînent d'abord A à la convergence, puis entraînent B. (À droite) Précision du modèle A au fur et à mesure que l'entraînement de B progresse. Les différentes couleurs correspondent à différents nombres de couches partagées. La précision de A diminue considérablement, surtout lorsque plusieurs couches sont partagées, et les chercheurs qualifient la goutte (la flèche rouge) d'oubli multi-modèle. Crédit :Benyahia, Yu et al.
Dans les années récentes, les chercheurs ont développé des réseaux de neurones profonds qui peuvent effectuer une variété de tâches, y compris les tâches de reconnaissance visuelle et de traitement du langage naturel (NLP). Bien que bon nombre de ces modèles aient obtenu des résultats remarquables, ils ne fonctionnent généralement bien que sur une tâche particulière en raison de ce que l'on appelle «l'oubli catastrophique».
Essentiellement, l'oubli catastrophique signifie que lorsqu'un modèle qui a été initialement formé sur la tâche A est ensuite formé sur la tâche B, ses performances sur la tâche A diminueront considérablement. Dans un article prépublié sur arXiv, des chercheurs de Swisscom et de l'EPFL ont identifié un nouveau type d'oubli et proposé une nouvelle approche qui pourrait aider à le surmonter via une perte de plasticité pondérale statistiquement justifiée.
« Quand nous avons commencé à travailler sur notre projet, la conception automatique d'architectures neuronales était coûteuse en temps de calcul et irréalisable pour la plupart des entreprises, " Yassine Benyahia et Kaicheng Yu, les chercheurs principaux de l'étude, a dit TechXplore par e-mail. « L'objectif initial de notre étude était d'identifier de nouvelles méthodes pour réduire cette dépense. Lorsque le projet a démarré, un article de Google prétendait avoir considérablement réduit le temps et les ressources nécessaires pour créer des architectures neuronales à l'aide d'une nouvelle méthode appelée partage de poids. Cela a rendu l'autoML réalisable pour les chercheurs sans énormes clusters de GPU, nous encourageant à étudier ce sujet plus en profondeur.
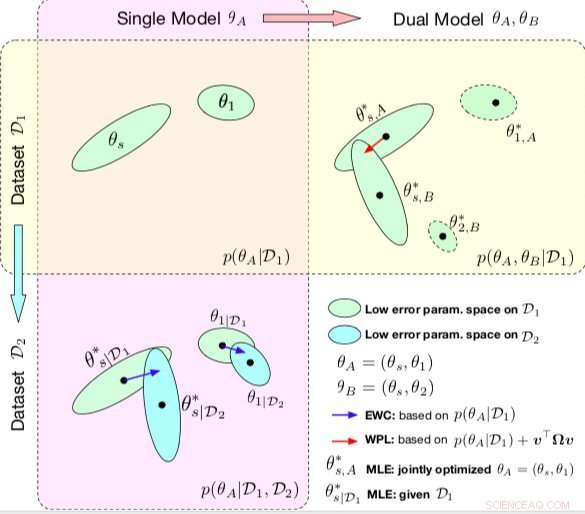
Comparaison entre CEE et WPL. Les ellipses dans chaque sous-parcelle représentent des régions de paramètres correspondant à une faible erreur. (En haut à gauche) Les deux méthodes commencent par un seul modèle, avec les paramètres θA ={θs, 1}, entraînés sur un seul jeu de données D1. (En bas à gauche) EWC régularise tous les paramètres basés sur p(θA|D1) pour entraîner le même modèle initial sur un nouveau jeu de données D2. (En haut à droite) Par contre, WPL utilise le jeu de données initial D1 et régularise uniquement les paramètres partagés θs en fonction à la fois de p(θA|D1) et de v>Ωv, tandis que les paramètres θ2 peuvent se déplacer librement. Crédit :Benyahia, Yu et al.
Au cours de leurs recherches sur les modèles basés sur les réseaux de neurones, Benyahia, Yu et leurs collègues ont remarqué un problème avec le partage du poids. Lorsqu'ils ont entraîné deux modèles (par exemple A et B) de manière séquentielle, les performances du modèle A ont diminué, tandis que les performances du modèle B ont augmenté, ou vice versa. Ils ont montré que ce phénomène, qu'ils appelaient "l'oubli multi-modèles, " peut entraver les performances de plusieurs approches auto-mL, y compris la recherche efficace d'architecture neuronale (ENAS) de Google.
"Nous avons réalisé que le partage du poids provoquait un impact négatif des modèles les uns sur les autres, ce qui rendait le processus de recherche d'architecture plus aléatoire, " Benyahia et Yu ont expliqué. " Nous avions aussi nos réserves sur la recherche d'architecture, où seuls les résultats finaux sont mis en lumière et où il n'y a pas de bon cadre pour évaluer la qualité de la recherche d'architecture de manière équitable. Notre approche pourrait aider à résoudre ce problème d'oubli, car il est lié à une méthode de base sur laquelle s'appuient presque tous les articles récents sur l'autoML, et nous considérons qu'un tel impact est énorme pour la communauté."
Dans leur étude, les chercheurs ont modélisé mathématiquement l'oubli multi-modèle et en ont déduit une nouvelle perte, appelé perte de plasticité pondérale. Cette perte pourrait réduire considérablement l'oubli multi-modèle en régularisant l'apprentissage des paramètres partagés d'un modèle en fonction de leur importance pour les modèles précédents.
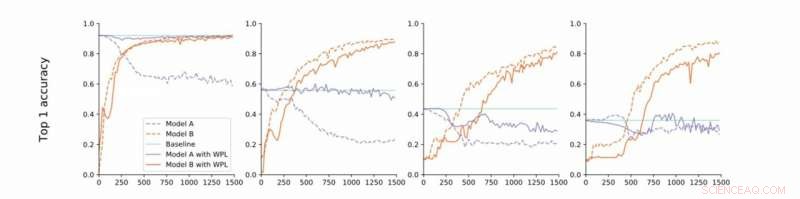
De la convergence stricte à la convergence lâche. Les chercheurs mènent des expériences sur MNIST avec les modèles A et B avec des paramètres partagés et rapportent la précision du modèle A avant d'entraîner le modèle B (référence, vert) et la précision des modèles A et B lors de l'entraînement du modèle B avec (orange) ou sans (bleu) WPL. En (a) ils montrent les résultats pour la convergence stricte :A est initialement entraîné à la convergence. Ils relâchent ensuite cette hypothèse et entraînent A à environ 55% (b), 43% (c), et 38% (d) de sa précision optimale. WPL est très efficace lorsque A est entraîné à au moins 40 % d'optimalité ; au dessous de, les informations de Fisher deviennent trop imprécises pour fournir des poids d'importance fiables. Ainsi WPL contribue à réduire l'oubli multi-modèle, même lorsque les poids ne sont pas optimaux. WPL réduit l'oubli jusqu'à 99,99% pour (a) et (b), et jusqu'à 2 % pour (c). Crédit :Benyahia, Yu et al.
"Essentiellement, en raison de la sur-paramétrisation des réseaux de neurones, notre perte diminue d'abord les paramètres qui sont « moins importants » pour la perte finale, et garde les plus importants inchangés, " Benyahia et Yu ont déclaré. " Les performances du modèle A ne sont donc pas affectées, tandis que les performances du modèle B ne cessent d'augmenter. Sur de petits ensembles de données, notre modèle peut réduire l'oubli jusqu'à 99%, et sur les méthodes autoML, jusqu'à 80 pour cent au milieu de la formation."
Dans une série d'essais, les chercheurs ont démontré l'efficacité de leur approche pour diminuer l'oubli multi-modèle, à la fois dans les cas où deux modèles sont entraînés séquentiellement et pour la recherche d'architecture neuronale. Leurs résultats suggèrent que l'ajout de la plasticité du poids dans la recherche d'architecture neuronale peut améliorer considérablement les performances de plusieurs modèles sur les tâches de PNL et de vision par ordinateur.
L'étude menée par Benyahia, Yu et leurs collègues mettent en lumière la question de l'oubli catastrophique, en particulier celui qui se produit lorsque plusieurs modèles sont entraînés séquentiellement. Après avoir modélisé mathématiquement ce problème, les chercheurs ont introduit une solution qui pourrait le surmonter, ou au moins réduire drastiquement son impact.
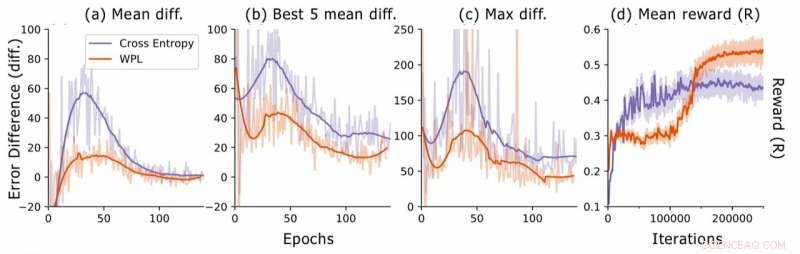
Différence d'erreur lors de la recherche d'architecture neuronale. Pour chaque architecture, les chercheurs calculent les différences d'erreur RNN err2−err1, où err1 est l'erreur juste après la formation de cette architecture et err2 celle après que toutes les architectures aient été formées à l'époque actuelle. Ils tracent (a) la différence moyenne sur tous les modèles échantillonnés, (b) la différence moyenne sur les 5 modèles avec le plus faible err1, et (c) la différence maximale sur tous les modèles. En (d), ils tracent la récompense moyenne des architectures échantillonnées en fonction des itérations d'apprentissage. Bien que le WPL entraîne initialement des récompenses plus faibles, en raison d'un grand poids α dans l'équation (8), en réduisant l'oubli ultérieur permet au contrôleur d'échantillonner de meilleures architectures, comme indiqué par la récompense plus élevée dans la seconde moitié. Crédit :Benyahia, Yu et al.
"Dans l'oubli multi-modèle, notre principe directeur était de penser par formules et pas seulement par simple intuition ou heuristique, " Benyahia et Yu ont déclaré. "Nous croyons fermement que cette 'pensée en formules' peut conduire les chercheurs à de grandes découvertes. C'est pourquoi pour des recherches plus approfondies, nous visons à appliquer cette approche à d'autres domaines de l'apprentissage automatique. En outre, nous prévoyons d'adapter notre perte aux récentes méthodes autoML de pointe pour démontrer son efficacité à résoudre le problème de partage de poids que nous avons observé."
© 2019 Réseau Science X