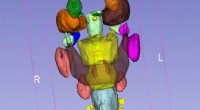
Un système de « vision par ordinateur » développé à l'UCLA permet d'identifier des objets à partir d'aperçus partiels seulement, comme en utilisant ces extraits de photos d'une moto. Crédit :Université de Californie, Los Angeles
Les ingénieurs de l'UCLA et de l'Université de Stanford ont démontré un système informatique capable de découvrir et d'identifier les objets du monde réel qu'il « voit » sur la base de la même méthode d'apprentissage visuel que celle utilisée par les humains.
Le système est une avancée dans un type de technologie appelé « vision par ordinateur, " qui permet aux ordinateurs de lire et d'identifier des images visuelles. Cela pourrait être une étape importante vers des systèmes d'intelligence artificielle généraux - des ordinateurs qui apprennent par eux-mêmes, sont intuitifs, prendre des décisions fondées sur le raisonnement et interagir avec les humains d'une manière beaucoup plus humaine. Bien que les systèmes de vision par ordinateur IA actuels soient de plus en plus puissants et capables, ils sont spécifiques à une tâche, ce qui signifie que leur capacité à identifier ce qu'ils voient est limitée par combien ils ont été formés et programmés par les humains.
Même les meilleurs systèmes de vision par ordinateur d'aujourd'hui ne peuvent pas créer une image complète d'un objet après en avoir vu seulement certaines parties, et les systèmes peuvent être trompés en visualisant l'objet dans un cadre inconnu. Les ingénieurs visent à créer des systèmes informatiques dotés de ces capacités, tout comme les humains peuvent comprendre qu'ils regardent un chien, même si l'animal se cache derrière une chaise et que seules les pattes et la queue sont visibles. Humains, bien sûr, peut également facilement deviner où se trouvent la tête du chien et le reste de son corps, mais cette capacité échappe toujours à la plupart des systèmes d'intelligence artificielle.
Les systèmes de vision par ordinateur actuels ne sont pas conçus pour apprendre par eux-mêmes. Ils doivent être formés sur exactement ce qu'il faut apprendre, généralement en examinant des milliers d'images dans lesquelles les objets qu'ils essaient d'identifier sont étiquetés pour eux. Des ordinateurs, bien sûr, ne peuvent pas non plus expliquer leur justification pour déterminer ce que l'objet sur une photo représente :les systèmes basés sur l'IA ne construisent pas une image interne ou un modèle de bon sens d'objets appris comme le font les humains.
La nouvelle méthode des ingénieurs, décrit dans le Actes de l'Académie nationale des sciences , montre un moyen de contourner ces lacunes.
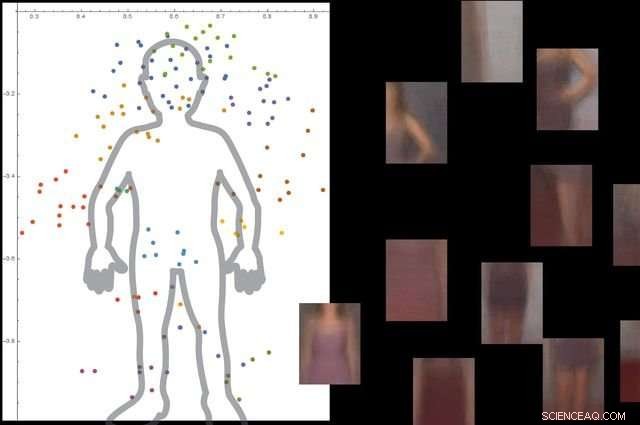
Le système comprend ce qu'est un corps humain en regardant des milliers d'images avec des personnes à l'intérieur, puis en ignorant les objets d'arrière-plan non essentiels. Crédit :Université de Californie, Los Angeles
L'approche se compose de trois grandes étapes. D'abord, le système divise une image en petits morceaux, que les chercheurs appellent "viewlets". Seconde, l'ordinateur apprend comment ces viewlets s'assemblent pour former l'objet en question. Et enfin, il regarde quels autres objets se trouvent dans la zone environnante, et si oui ou non les informations sur ces objets sont pertinentes pour décrire et identifier l'objet principal.
Pour aider le nouveau système à « apprendre » davantage comme les humains, les ingénieurs ont décidé de l'immerger dans une réplique Internet de l'environnement dans lequel vivent les humains.
"Heureusement, Internet fournit deux choses qui aident un système de vision par ordinateur inspiré par le cerveau à apprendre de la même manière que les humains, " dit Vwani Roychowdhury, un professeur de génie électrique et informatique de l'UCLA et le chercheur principal de l'étude. « L'une est une mine d'images et de vidéos qui représentent les mêmes types d'objets. La seconde est que ces objets sont montrés sous de nombreux angles :obscurcis, yeux d'oiseau, de près et ils sont placés dans tous les types d'environnements. »
Pour développer le cadre, les chercheurs ont tiré des enseignements de la psychologie cognitive et des neurosciences.
« En commençant comme les nourrissons, nous apprenons ce qu'est quelque chose parce que nous en voyons de nombreux exemples, dans de nombreux contextes, " a déclaré Roychowdhury. " Cet apprentissage contextuel est une caractéristique clé de notre cerveau, et cela nous aide à construire des modèles d'objets robustes qui font partie d'une vision du monde intégrée où tout est fonctionnellement connecté."
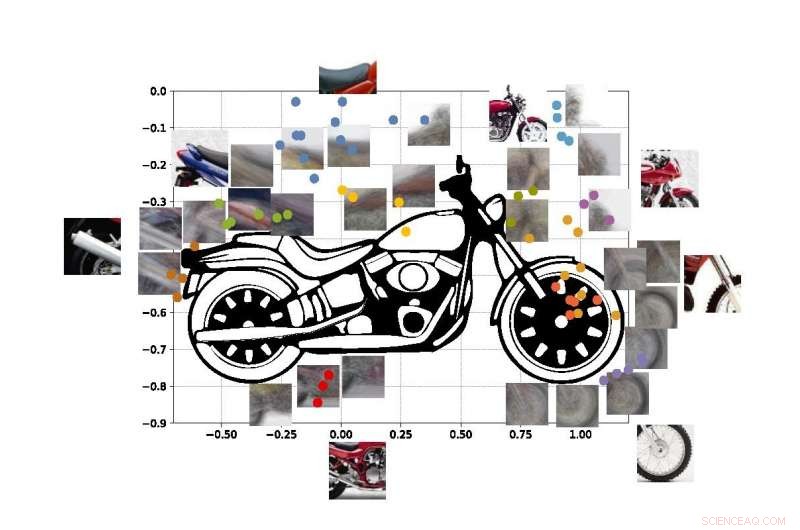
Les points colorés sur la figure montrent les coordonnées estimées des centres de certaines des vues de notre moto SUVM. Chaque représentation viewlet est un composite d'exemples de vues/correctifs ayant des apparences similaires. Crédit :Lichao Chen, Tianyi Wang, et Vwani Roychowdhury (Université de Californie, Los Angeles).
Les chercheurs ont testé le système avec environ 9, 000 images, chacun montrant des personnes et d'autres objets. La plate-forme a pu construire un modèle détaillé du corps humain sans guidage externe et sans que les images soient étiquetées.
Les ingénieurs ont effectué des tests similaires en utilisant des images de motos, voitures et avions. Dans tous les cas, leur système fonctionnait mieux ou au moins aussi bien que les systèmes de vision par ordinateur traditionnels qui ont été développés avec de nombreuses années de formation.
Le co-auteur principal de l'étude est Thomas Kailath, professeur émérite de génie électrique à Stanford qui était le directeur de doctorat de Roychowdhury dans les années 1980. Les autres auteurs sont d'anciens doctorants de l'UCLA Lichao Chen (maintenant ingénieur de recherche chez Google) et Sudhir Singh (qui a fondé une entreprise qui construit des compagnons d'enseignement robotiques pour les enfants).
Singh, Roychowdhury et Kailath ont précédemment travaillé ensemble pour développer l'un des premiers moteurs de recherche visuels automatisés pour la mode, le StileEye maintenant fermé, qui a donné lieu à certaines des idées de base derrière la nouvelle recherche.