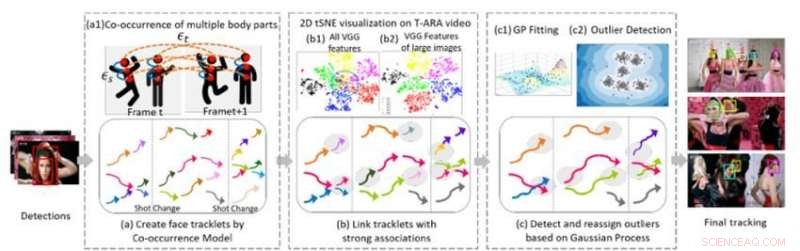
Figure 1. Trois composants algorithmiques de base de notre méthode de suivi multi-visage dans une séquence vidéo. Crédit :IBM
Lors de la récente conférence 2018 sur la vision par ordinateur et la reconnaissance de formes, J'ai présenté un nouvel algorithme de suivi multi-faces, un élément essentiel dans la compréhension de la vidéo. Pour comprendre des séquences visuelles impliquant des personnes, Les systèmes d'IA doivent être capables de suivre plusieurs individus à travers les scènes, malgré les changements d'angles de caméra, éclairage, et les apparences. Le nouvel algorithme permet aux systèmes d'IA d'accomplir cette tâche.
Les travaux antérieurs dans ce domaine se sont largement concentrés sur le suivi d'une seule personne ou de plusieurs personnes dans un plan. L'étape suivante consiste à suivre plusieurs personnes tout au long d'une vidéo entière composée de nombreux plans différents. Cette tâche est difficile car les gens peuvent quitter et réintégrer la vidéo à plusieurs reprises. Leurs apparences peuvent changer radicalement grâce à la garde-robe, coiffure, et maquillage. Leurs poses changent, et leurs faces peuvent être partiellement obstruées par l'angle de vue, éclairage, ou d'autres objets de la scène. L'angle de la caméra et le zoom changent également, et des caractéristiques telles qu'une mauvaise qualité d'image, mauvais éclairage, et le flou de mouvement peut augmenter la difficulté de la tâche. Les technologies de reconnaissance faciale existantes peuvent fonctionner dans des cas plus contraints, où les images sont de bonne qualité et montrent le visage complet d'une personne, mais échouer dans la vidéo sans contrainte, où les visages des gens peuvent être de profil, occlus, tondu, ou flou.
Une méthode de suivi multi-faces
En collaboration avec le professeur Ying Hung, du Département de statistique et de biostatistique de l'Université Rutgers, nous avons développé une méthode pour repérer différents individus dans une séquence vidéo et les reconnaître s'ils partent puis rentrent dans la vidéo, même s'ils sont très différents. Pour faire ça, nous créons d'abord des tracklets pour les personnes présentes dans la vidéo. Les tracklets sont basés sur la cooccurrence de plusieurs parties du corps (visage, tête et épaules, haut du corps, corps entier) afin que les personnes puissent être suivies même lorsqu'elles ne sont pas entièrement en vue de la caméra (par exemple, leurs visages sont détournés ou obstrués par d'autres objets). Nous formulons le problème de suivi multi-personnes comme une structure de graphe G =(ν, ε) avec deux types d'arêtes :εs et εt. Les bords spatiaux s désignent les connexions de différentes parties du corps d'un candidat dans un cadre et sont utilisés pour générer l'état hypothétique d'un candidat. Les bords temporels εt désignent les connexions des mêmes parties du corps sur des cadres adjacents et sont utilisés pour estimer l'état de chaque personne dans différents cadres. Nous générons des tracklets de visage à l'aide de boîtes de délimitation de visage à partir des tracklets de chaque personne et extrayons les traits du visage pour le regroupement.
La deuxième partie de la méthode relie les tracklets qui appartiennent à la même personne. La figure 1 (b) montre la visualisation tSNE 2-D de la caractéristique extraite du visage VGG sur une vidéo musicale. Il montre que par rapport à toutes les caractéristiques (b1), caractéristique des grandes images (b) sont plus discriminantes. Nous construisons des connexions sans ambiguïté entre les tracklets en analysant la résolution de l'image du visage des objets et les distances relatives des caractéristiques profondes extraites. Cette étape génère un résultat de clustering initial. Des études empiriques montrent que les modèles basés sur CNN sont sensibles au flou et au bruit des images, car les réseaux sont généralement entraînés sur des images de haute qualité. Nous générons des résultats de clustering finaux robustes en utilisant un modèle de processus gaussien (GP) pour compenser les limitations profondes des fonctionnalités et pour capturer la richesse des données. Différent des approches basées sur CNN, Les modèles GP fournissent une approche paramétrique flexible pour capturer la non-linéarité et la corrélation spatio-temporelle du système sous-jacent. Par conséquent, c'est un outil attrayant à combiner avec l'approche basée sur CNN pour réduire davantage la dimension sans perdre des informations spatio-temporelles complexes et importer. Nous appliquons le modèle GP pour détecter les valeurs aberrantes, supprimer les connexions entre les valeurs aberrantes et autres tracklets, puis réaffecter les valeurs aberrantes aux clusters raffinés formés après la déconnexion des valeurs aberrantes, produisant ainsi des grappes de haute qualité.
Suivi multi-visage dans les vidéos musicales
Pour évaluer la performance de notre approche, nous l'avons comparé à des méthodes de pointe pour analyser des ensembles de données difficiles de vidéos sans contraintes. Dans une série d'expériences, nous avons utilisé des clips vidéo, qui présentent une qualité d'image élevée mais significative, changements rapides de scène, réglage de la caméra, mouvement de la caméra, se réconcilier, et accessoires (tels que des lunettes). Notre algorithme a surpassé les autres méthodes en ce qui concerne à la fois la précision du regroupement et le suivi. La pureté du clustering était nettement meilleure avec notre algorithme par rapport aux autres méthodes (0,86 pour notre algorithme contre 0,56 pour le concurrent le plus proche utilisant l'un des clips musicaux). En outre, notre méthode déterminait automatiquement le nombre de personnes, ou des grappes, à suivre sans avoir besoin d'une analyse vidéo manuelle.
Les performances de suivi de notre algorithme étaient également supérieures aux méthodes de pointe pour la plupart des métriques, y compris le rappel et la précision. Notre méthode a sensiblement augmenté les cas les plus suivis (MT) et réduit les instances de commutation d'identité (IDS) et les fragments de suivi (Frag). La vidéo ci-dessous montre des exemples de résultats de suivi dans plusieurs vidéos musicales. Notre algorithme suit de manière fiable plusieurs individus sur différents plans dans l'ensemble des vidéos sans contrainte, même si certaines personnes ont une apparence faciale très similaire, plusieurs chanteurs principaux apparaissent dans un fond encombré rempli de public, ou certains visages sont fortement occlus. Ce cadre pour le suivi multi-faces dans la vidéo sans contrainte est une étape importante dans l'amélioration de la compréhension de la vidéo. L'algorithme et ses performances sont décrits plus en détail dans notre article CVPR, "Une méthode sans précédent pour le suivi multi-faces dans les vidéos sans contraintes."
Cette histoire est republiée avec l'aimable autorisation d'IBM Research. Lisez l'histoire originale ici.