La promesse du big data est à l'horizon du domaine des sciences sociales depuis des années, mais jusqu'à présent, personne n'a été en mesure de tenir cette promesse. Dans sa leçon inaugurale du 22 mars, Le professeur et méthodologiste de recherche Bernard Veldkamp explique pourquoi et propose des solutions. Son point principal :nous devons trouver différentes manières de traiter ce type de données. "La question pourquoi devrait être remplacée par l'interprétation des modèles."
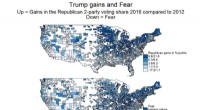
Il y a actuellement une révolution en cours en termes de quantité de données. En raison de l'essor d'Internet, des médias sociaux, téléphones portables et toutes sortes de capteurs, la quantité de données augmente jusqu'à quarante pour cent par an. Pour les sociologues, qui traitent du comportement des individus et des groupes, ces énormes quantités de données peuvent être une mine d'or. Cependant, même si la promesse du big data se profile à l'horizon pour le domaine des sciences sociales depuis de nombreuses années, l'analyse n'a pas donné les résultats escomptés. Par conséquent, l'enthousiasme se transforme peu à peu en scepticisme. En attendant, les informaticiens qui développent des méthodes pour analyser les données s'emparent de la marchandise. Un inconvénient important, cependant, est-ce que les informaticiens, étant donné leur parcours, sont incapables de prendre suffisamment en compte le contexte et les informations qu'ils étudient. Par conséquent, l'utilité de leurs conclusions est limitée.
Réduire l'écart
Selon le professeur Veldkamp, il est temps de changer de paradigme. L'une des principales raisons pour lesquelles les chercheurs en sciences sociales ont perdu la première bataille, il mentionne le fait qu'ils ont essayé de traiter et d'analyser les données en utilisant des méthodes traditionnelles pendant beaucoup trop longtemps. Pour les méthodes traditionnelles, la quantité de données est tout simplement trop importante. De plus, et peut-être plus important encore, le type de données concernées est complètement différent des données précédemment disponibles. Parce que les données, contrairement aux données des échantillons traditionnels, observations ou questionnaires - n'a pas été spécifiquement collecté pour une analyse scientifique, l'origine et la qualité ne sont pas toujours claires. Ou, comme Veldkamp le dit simplement :« Il y a beaucoup de bruit blanc dedans. C'est pourquoi il croit qu'il est très important de choisir une approche différente. Le domaine de la méthodologie de recherche, le champ de Veldkamp, est idéalement adapté pour combler le fossé entre les mégadonnées et le domaine des sciences sociales. "Les données valent leur pesant d'or proverbial, mais il n'y a actuellement pas assez de mineurs d'or qualifiés pour le travail."
Motifs
Le professeur Veldkamp estime que le fait que l'origine des données soit parfois inconnue et qu'il puisse y avoir beaucoup de bruit blanc ne doit pas nécessairement être un problème, mais c'est quelque chose que vous devez prendre en compte dans votre analyse. Big Data, précisément en raison de la grande quantité, offre la possibilité de corriger statistiquement les incertitudes. En outre, Le professeur Veldkamp estime qu'il est essentiel de "modéliser dans le bruit blanc". Cela signifie que vous devez être plus prudent avec les hypothèses et que toutes les conclusions que vous tirez doivent être moins fermes. Professeur Veldkamp :« Pour cette raison, il devient plus important d'interpréter les connexions que d'examiner la causalité. Ou, pour le dire plus simplement, l'interprétation des modèles devrait remplacer la question du pourquoi."