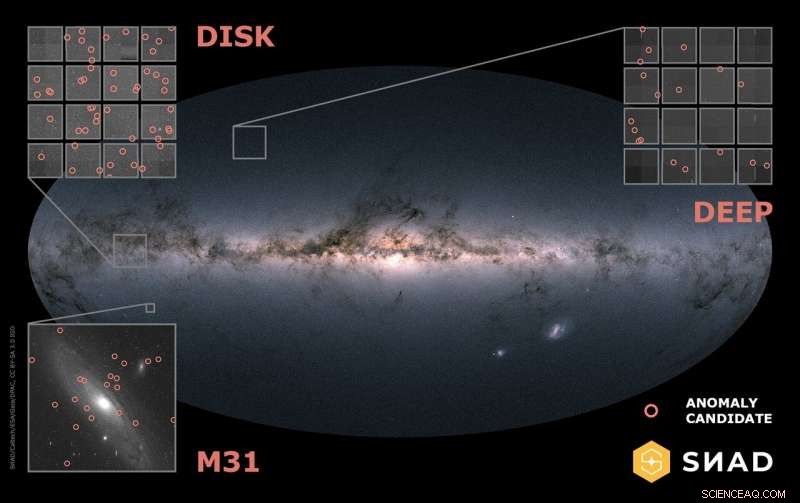
Localisation de trois champs ZTF analysés dans ce travail avec des candidats anormaux marqués. Crédit :Maria Prujinskaya (2020)
L'équipe SNAD, un réseau international formé par des chercheurs de Russie, la France et les États-Unis, a développé un pipeline pour trouver des objets rares et exotiques parmi les meules de foin de données provenant d'études astronomiques.
Compte tenu de la taille toujours croissante des ensembles de données astronomiques, même si nos télescopes détectent des phénomènes astronomiques intéressants inattendus, il est très peu probable que nous puissions les reconnaître au milieu de millions voire de milliards d'observations. La solution réside dans des outils automatiques spécialement conçus pour reconnaître les comportements inhabituels cachés parmi des milliards de mesures. Certains de ces outils existent déjà et sont employés, par exemple, pour identifier les activités frauduleuses de cartes de crédit parmi des millions de transactions chaque jour. Cependant, leur adaptation aux données scientifiques n'est pas simple en raison de complications liées à la nature des observations en astronomie. L'équipe du SNAD travaille depuis 3 ans au développement et à l'adaptation de telles solutions au contexte de l'astronomie.
Lors de leur dernière réunion annuelle, le groupe a concentré ses efforts sur des objets dont la luminosité varie dans le temps. Le pipeline combine les forces des algorithmes d'apprentissage automatique et les connaissances irremplaçables d'experts humains pour créer un outil de détection d'anomalies robuste. L'article décrit les résultats de l'application de ce cadre à la troisième publication de données de l'installation transitoire de Zwicky. Son processus en trois étapes impliquait l'extraction de caractéristiques sur des courbes de lumière (qui suit la luminosité des objets au fil du temps), recherche de candidats anormaux à l'aide de plusieurs algorithmes d'apprentissage automatique et filtrage manuel des candidats par un expert humain. Cette dernière étape comprenait également la réalisation d'observations avec d'autres télescopes lorsque cela était possible. Dans cette étude, 4 algorithmes d'apprentissage automatique ont été utilisés pour signaler 277 anomalies candidates à une enquête humaine, sur un ensemble de données initial de 2,25 millions d'objets.
Le groupe a également développé une interface Web spécialement conçue qui a permis une visualisation immédiate et une correspondance croisée de chaque candidat avec les catalogues astronomiques existants. Ceci a été construit afin de faciliter le travail des experts qui doivent corréler les candidats à l'anomalie avec toute autre information publiquement disponible sur les coordonnées du ciel à l'étude.
Sur les 277 objets considérés comme anormaux par la machine, 188 (68%) présentaient des caractéristiques inhabituelles dues à des effets non astrophysiques (y compris des défauts dus au pipeline de soustraction d'images de ZTF), 66 (24 %) étaient des objets déjà catalogués auparavant et 23 (8 %) étaient des objets auparavant inconnus. La première catégorie comprend quelques curiosités amusantes et les deux derniers cas d'intérêt scientifique. Par exemple, un objet signalé comme anomalie par la machine était en fait l'occultation d'une étoile de fond par l'astéroïde Barcelone, qui du point de vue d'un observateur de la Terre a été détectée comme une source ponctuelle variable alors qu'en réalité ni l'étoile ni l'astéroïde n'ont réellement changé de luminosité. Les auteurs ont également caractérisé les artefacts de soustraction d'images récurrents et exotiques qui interfèrent avec l'analyse de la courbe de lumière et peuvent faire croire à un pipeline de détection d'anomalies qu'il s'agit d'un réel, objet anormal. Afin d'aider à trier rapidement la première classe des candidats restants, ils ont pu identifier une relation bidimensionnelle simple qui peut être utilisée pour aider à filtrer les courbes de lumière potentiellement fausses dans les études futures.
Parmi les deuxième et troisième catégories, les auteurs ont trouvé quatre candidats supernovae, six binaires à éclipse non classés auparavant, quatre candidats pré-séquence principale, une possible fusée naine rouge, et confirmé par spectroscopie une étoile RS Canum Venaticorum, parmi d'autres candidats à l'anomalie.
Séparer rapidement et sans effort les artefacts des candidats d'anomalies intéressants est crucial pour les observatoires actuels et bientôt proches de la prochaine génération, tels que le Vera Rubin Observatory Legacy Survey of Space and Time (LSST). LSST générera environ 10 millions de sources transitoires par nuit - des algorithmes sophistiqués et robustes seront nécessaires pour passer au crible toutes ces données afin de ne pas manquer les objets inattendus et intéressants, et les scientifiques peuvent mieux comprendre ces bizarreries spatiales.
Auteur principal Konstantin Malantchev, chercheur à l'Université de l'Illinois à Urbana-Champaign (États-Unis) et à l'institut d'astronomie Sternberg du Lomonosov Moscou (Russie), dit, « Concevoir des outils spécifiquement dédiés à la recherche d'anomalies d'intérêt astrophysique est notre seule option pour assurer la pleine exploitation des ensembles de données que nous nous sommes battus si durement pour acquérir. L'équipe SNAD est pleinement engagée à aider la communauté astronomique à explorer le plein potentiel des futurs ensembles de données. ."
L'article a été accepté pour publication dans Avis mensuels de la Royal Astronomical Society et est également accessible au public en version pré-imprimée. Le code source et les résultats, comprenant une liste complète d'objets ayant une application scientifique potentielle, ainsi que les techniques de canalisation, sont ouverts au public pour le bénéfice et la vérification de la communauté astronomique.