Le modèle peut être formé à la volée pour produire des images de haute qualité en seulement 12 secondes. Crédit :Bochang Moon de l'Institut des sciences et technologies de Gwangju, Corée
L'infographie de haute qualité, avec sa présence omniprésente dans les jeux, les illustrations et la visualisation, est considérée comme l'état de l'art en matière de technologie d'affichage visuel.
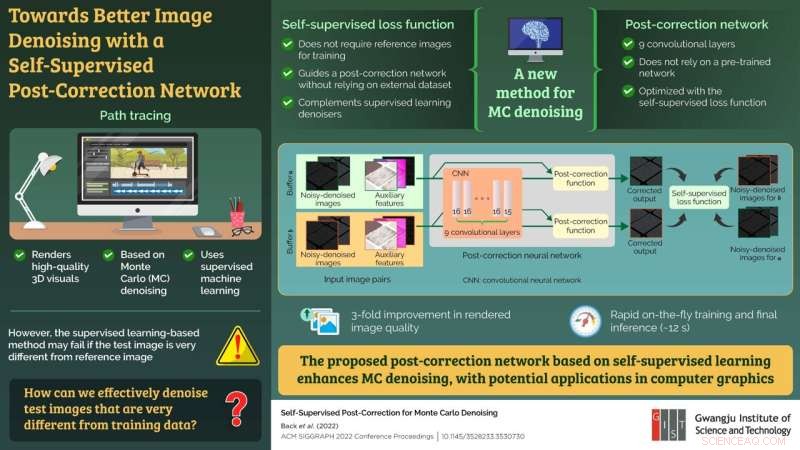
La méthode utilisée pour restituer des images de haute qualité et réalistes est connue sous le nom de "path tracing", qui utilise une approche de débruitage de Monte Carlo (MC) basée sur l'apprentissage automatique supervisé. Dans ce cadre d'apprentissage, le modèle d'apprentissage automatique est d'abord pré-entraîné avec des paires d'images bruitées et propres, puis appliqué à l'image bruitée réelle à restituer (image de test).
Bien que considérée comme la meilleure approche en termes de qualité d'image, cette méthode peut ne pas fonctionner correctement si l'image de test est nettement différente des images utilisées pour la formation.
Pour résoudre ce problème, un groupe de chercheurs, dont Ph.D. l'étudiant Jonghee Back et le professeur agrégé Bochang Moon de l'Institut des sciences et technologies de Gwangju en Corée, le chercheur scientifique Binh-Son Hua de VinAI Research au Vietnam et le professeur agrégé Toshiya Hachisuka de l'Université de Waterloo au Canada, ont proposé, dans une nouvelle étude, un nouvelle méthode de débruitage MC qui ne repose pas sur une référence. Leur étude a été mise en ligne le 24 juillet 2022 et publiée dans ACM SIGGRAPH 2022 Conference Proceedings .
"Les méthodes existantes échouent non seulement lorsque les ensembles de données de test et d'entraînement sont très différents, mais prennent également beaucoup de temps pour préparer l'ensemble de données de formation pour le pré-entraînement du réseau. Ce qu'il faut, c'est un réseau de neurones qui peut être formé avec uniquement des images de test à la volée sans avoir besoin pour la préformation », explique le Dr Moon, expliquant la motivation derrière leur étude.
Pour ce faire, l'équipe a proposé une nouvelle approche de post-correction pour une image débruitée qui comprenait un cadre d'apprentissage automatique auto-supervisé et un réseau de post-correction, essentiellement un réseau neuronal convolutif, pour le traitement d'image. Le réseau post-correction ne dépendait pas d'un réseau pré-formé et pouvait être optimisé en utilisant le concept d'apprentissage auto-supervisé sans s'appuyer sur une référence. De plus, le modèle auto-supervisé a complété et renforcé les modèles supervisés conventionnels pour le débruitage.
Pour tester l'efficacité du réseau proposé, l'équipe a appliqué son approche aux méthodes de débruitage de pointe existantes. Le modèle proposé a démontré une triple amélioration de la qualité de l'image rendue par rapport à l'image d'entrée en préservant des détails plus fins. De plus, l'ensemble du processus de formation à la volée et d'inférence finale n'a pris que 12 secondes.
« Notre approche est la première qui ne repose pas sur la pré-formation à l'aide d'un ensemble de données externe. Cela, en effet, raccourcira le temps de production et améliorera la qualité du contenu basé sur le rendu hors ligne, comme l'animation et les films », déclare le Dr Moon. , spéculant sur les applications potentielles de leurs travaux. Le nouveau modèle de base améliore la précision de l'interprétation des images de télédétection














