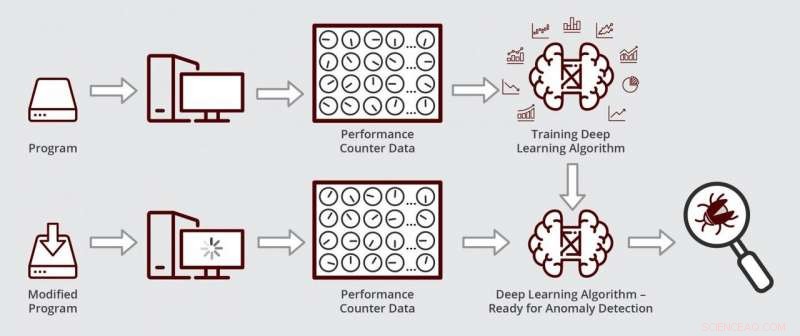
Schéma illustrant le fonctionnement de l'algorithme d'apprentissage en profondeur de Muzahid. L'algorithme est prêt pour la détection d'anomalies après avoir été formé pour la première fois sur les données de compteur de performances d'une version sans bogue d'un programme. Crédit :Texas A&M Engineering
Nous avons tous partagé la frustration :les mises à jour logicielles destinées à accélérer l'exécution de nos applications finissent par faire le contraire par inadvertance. Ces bogues, surnommés dans le domaine informatique comme régressions de performance, sont longues à corriger, car la localisation des erreurs logicielles nécessite normalement une intervention humaine importante.
Pour surmonter cet obstacle, chercheurs de la Texas A&M University, en collaboration avec des informaticiens d'Intel Labs, ont maintenant développé un moyen entièrement automatisé d'identifier la source des erreurs causées par les mises à jour logicielles. Leur algorithme, basé sur une forme spécialisée d'apprentissage automatique appelée apprentissage profond, n'est pas seulement clé en main, mais aussi rapide, trouver des bugs de performances en quelques heures au lieu de quelques jours.
« La mise à jour d'un logiciel peut parfois se retourner contre vous lorsque des erreurs s'installent et provoquent des ralentissements. Ce problème est encore plus exagéré pour les entreprises qui utilisent des systèmes logiciels à grande échelle en constante évolution, " a déclaré le Dr Abdullah Muzahid, professeur adjoint au Département d'informatique et de génie. "Nous avons conçu un outil pratique pour diagnostiquer les régressions de performances qui est compatible avec toute une gamme de logiciels et de langages de programmation, étendre considérablement son utilité."
Les chercheurs ont décrit leurs résultats dans la 32e édition de Advances in Neural Information Processing Systems à partir des actes de la conférence Neural Information Processing Systems en décembre.
Pour identifier la source des erreurs dans le logiciel, les débogueurs vérifient souvent l'état des compteurs de performances au sein de l'unité centrale de traitement. Ces compteurs sont des lignes de code qui surveillent la façon dont le programme est exécuté sur le matériel de l'ordinateur dans la mémoire, par exemple. Donc, lorsque le logiciel s'exécute, les compteurs gardent une trace du nombre de fois qu'il accède à certains emplacements mémoire, le temps qu'il y reste et quand il sort, entre autres. D'où, lorsque le comportement du logiciel tourne mal, les compteurs sont à nouveau utilisés pour le diagnostic.
"Les compteurs de performances donnent une idée de la santé d'exécution du programme, " dit Muzahid. " Alors, si un programme ne s'exécute pas comme il est censé le faire, ces compteurs auront généralement le signe révélateur d'un comportement anormal."
Cependant, les nouveaux postes de travail et serveurs ont des centaines de compteurs de performances, ce qui rend pratiquement impossible le suivi manuel de tous leurs états, puis la recherche de modèles aberrants indiquant une erreur de performance. C'est là qu'intervient l'apprentissage automatique de Muzahid.
En utilisant l'apprentissage en profondeur, les chercheurs ont pu suivre des données provenant d'un grand nombre de compteurs simultanément en réduisant la taille des données, ce qui revient à compresser une image haute résolution à une fraction de sa taille d'origine en modifiant son format. Dans les données de dimension inférieure, leur algorithme pourrait alors rechercher des modèles qui s'écartent de la normale.
Lorsque leur algorithme était prêt, les chercheurs ont testé s'il pouvait trouver et diagnostiquer un bug de performance dans un logiciel de gestion de données disponible dans le commerce utilisé par les entreprises pour suivre leurs chiffres et leurs chiffres. D'abord, ils ont entraîné leur algorithme à reconnaître les données de compteur normales en exécutant un ancien, version sans problème du logiciel de gestion des données. Prochain, ils ont exécuté leur algorithme sur une version mise à jour du logiciel avec la régression des performances. Ils ont découvert que leur algorithme localisait et diagnostiquait le bogue en quelques heures. Muzahid a déclaré que ce type d'analyse pouvait prendre un temps considérable s'il était effectué manuellement.
En plus de diagnostiquer les régressions de performances dans les logiciels, Muzahid a noté que leur algorithme d'apprentissage en profondeur a également des utilisations potentielles dans d'autres domaines de recherche, comme le développement de la technologie nécessaire à la conduite autonome.
"L'idée de base est encore une fois la même, c'est être capable de détecter un modèle anormal, " a déclaré Muzahid. " Les voitures autonomes doivent être capables de détecter si une voiture ou un humain se trouve devant elle et ensuite agir en conséquence. Donc, c'est encore une forme de détection d'anomalies et la bonne nouvelle est que c'est ce pour quoi notre algorithme est déjà conçu."
Parmi les autres contributeurs à la recherche figurent le Dr Mejbah Alam, Dr Justin Gottschlich, Dr Nesime Tatbul, Dr Javier Turek et Dr Timothy Mattson d'Intel Labs.