Quand l'avenir est incertain, la récompense future peut être représentée par une distribution de probabilité. certains futurs possibles sont bons (sarcelle), d'autres sont mauvais (rouge). L'apprentissage par renforcement distributionnel peut en apprendre davantage sur cette distribution par rapport aux récompenses prédites grâce à une variante de l'algorithme TD. Crédit: La nature (2020). DOI :10.1038/s41586-019-1924-6
Une équipe de chercheurs de DeepMind, L'University College et l'Université Harvard ont découvert que les enseignements tirés de l'application de techniques d'apprentissage aux systèmes d'IA peuvent aider à expliquer le fonctionnement des voies de récompense dans le cerveau. Dans leur article publié dans la revue La nature , le groupe décrit la comparaison de l'apprentissage par renforcement distributionnel dans un ordinateur avec le traitement de la dopamine dans le cerveau de la souris, et ce qu'ils en ont appris.
Des recherches antérieures ont montré que la dopamine produite dans le cerveau est impliquée dans le traitement de la récompense - elle est produite lorsque quelque chose de bien se produit, et son expression se traduit par des sensations de plaisir. Certaines études ont également suggéré que les neurones du cerveau qui réagissent à la présence de dopamine réagissent tous de la même manière :un événement amène une personne ou une souris à se sentir bien ou mal. D'autres études ont suggéré que la réponse neuronale est davantage un gradient. Dans ce nouvel effort, les chercheurs ont trouvé des preuves soutenant cette dernière théorie.
L'apprentissage par renforcement distributionnel est un type d'apprentissage automatique basé sur le renforcement. Il est souvent utilisé lors de la conception de jeux tels que Starcraft II ou Go. Il garde une trace des bons coups par rapport aux mauvais coups et apprend à réduire le nombre de mauvais coups, améliorer ses performances plus il joue. Mais de tels systèmes ne traitent pas tous les bons et les mauvais coups de la même manière :chaque coup est pondéré au fur et à mesure qu'il est enregistré et les poids font partie des calculs utilisés lors des choix de coups futurs.
Les chercheurs ont noté que les humains semblent utiliser une stratégie similaire pour améliorer leur niveau de jeu, également. Les chercheurs de Londres soupçonnaient que les similitudes entre les systèmes d'IA et la façon dont le cerveau effectue le traitement des récompenses étaient probablement similaires, également. Pour savoir s'ils étaient corrects, ils ont réalisé des expériences avec des souris. Ils ont inséré dans leur cerveau des dispositifs capables d'enregistrer les réponses des neurones dopaminergiques individuels. Les souris ont ensuite été entraînées à effectuer une tâche dans laquelle elles ont reçu des récompenses pour avoir répondu de la manière souhaitée.
Les réponses des neurones de souris ont révélé qu'ils ne réagissaient pas tous de la même manière, comme la théorie antérieure l'avait prédit. Au lieu, ils ont répondu de manière fiable de différentes manières - une indication que les niveaux de plaisir ressentis par les souris étaient plus un gradient, comme l'équipe l'avait prédit.
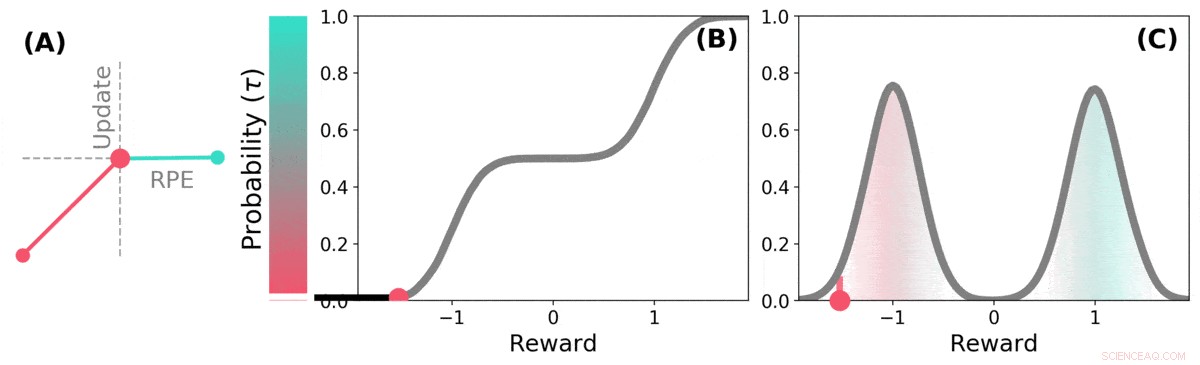
Distribution TD apprend des estimations de valeur pour de nombreuses parties différentes de la distribution des récompenses. la partie couverte par une estimation particulière est déterminée par le type de mise à jour asymétrique appliquée à cette estimation. (a) Une cellule « pessimiste » amplifierait les mises à jour négatives et ignorerait les mises à jour positives, une cellule « optimiste » amplifierait les mises à jour positives et ignorerait les mises à jour négatives. (b) Cela se traduit par une diversité d'estimations de valeur pessimistes ou optimistes, montré ici sous forme de points le long de la distribution cumulative des récompenses, qui capturent (c) La distribution complète des récompenses. Crédit: La nature (2020). DOI :10.1038/s41586-019-1924-6
© 2020 Réseau Science X