Le robot collecte des données d'interaction aléatoires à utiliser pour l'apprentissage d'une représentation et en tant que données hors politique pour RL. Crédit :Nair et al.
L'apprentissage par renforcement (RL) s'est jusqu'à présent avéré être une technique efficace pour entraîner des agents artificiels sur des tâches individuelles. Cependant, lorsqu'il s'agit de former des robots polyvalents, qui devrait être capable d'accomplir une variété de tâches qui nécessitent des compétences différentes, la plupart des approches de RL existantes sont loin d'être idéales.
Avec ça en tête, une équipe de chercheurs de l'UC Berkeley a récemment développé une nouvelle approche RL qui pourrait être utilisée pour apprendre aux robots à adapter leur comportement en fonction de la tâche qui leur est présentée. Cette approche, décrit dans un article prépublié sur arXiv et présenté à la conférence de cette année sur l'apprentissage robotique, permet aux robots d'inventer automatiquement des comportements et de les pratiquer au fil du temps, apprendre lesquelles peuvent être exécutées dans un environnement donné. Les robots peuvent ensuite réutiliser les connaissances acquises et les appliquer à de nouvelles tâches que les utilisateurs humains leur demandent d'accomplir.
"Nous sommes convaincus que les données sont essentielles pour la manipulation robotique et pour obtenir suffisamment de données pour résoudre la manipulation de manière générale, les robots devront collecter eux-mêmes les données, "Ashvin Nair, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "C'est ce que nous appelons l'apprentissage par robot auto-supervisé :un robot qui peut collecter activement des données d'exploration cohérentes et comprendre par lui-même s'il a réussi ou échoué dans des tâches afin d'acquérir de nouvelles compétences."
La nouvelle approche développée par Nair et ses collègues est basée sur un cadre RL conditionné par les objectifs présenté dans leurs travaux précédents. Dans cette étude précédente, les chercheurs ont introduit la définition d'objectifs dans un espace latent comme technique pour entraîner des robots à des compétences telles que pousser des objets ou ouvrir des portes directement à partir de pixels, sans avoir besoin d'une fonction de récompense externe ou d'une estimation d'état.
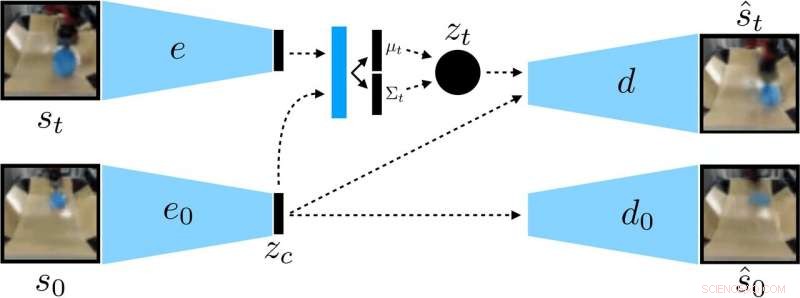
Les chercheurs ont formé une VAE contextuelle sur les données, qui démêle un contexte qui reste constant pendant un déploiement. Crédit :Nair et al.
« Dans notre nouveau travail, nous nous concentrons sur la généralisation :comment pouvons-nous faire un apprentissage auto-supervisé pour non seulement apprendre une seule compétence, mais aussi être capable de généraliser à la diversité visuelle tout en exécutant cette compétence ?", a déclaré Nair. "Nous pensons que la capacité de généraliser à de nouvelles situations sera la clé d'une meilleure manipulation robotique."
Plutôt que d'entraîner un robot sur de nombreuses compétences individuellement, le modèle d'établissement d'objectifs conditionnel proposé par Nair et ses collègues est conçu pour définir des objectifs spécifiques réalisables pour le robot et alignés sur son état actuel. Essentiellement, l'algorithme qu'ils ont développé apprend un type spécifique de représentation qui sépare les choses que le robot peut contrôler de celles qu'il ne peut pas contrôler.
Lors de l'utilisation de leur méthode d'apprentissage auto-supervisé, le robot collecte initialement des données (c'est-à-dire un ensemble d'images et d'actions) en interagissant de manière aléatoire avec son environnement environnant. Ensuite, il forme une représentation compressée de ces données qui convertit les images en vecteurs de faible dimension qui contiennent implicitement des informations telles que la position des objets. Plutôt que de se faire dire explicitement ce qu'il faut apprendre, cette représentation comprend automatiquement les concepts via son objectif de compression.
"En utilisant la représentation savante, le robot s'entraîne à atteindre différents objectifs et forme une politique en utilisant l'apprentissage par renforcement, " Nair a expliqué. " La représentation compressée est la clé pour cette phase de pratique :elle est utilisée pour mesurer la proximité de deux images afin que le robot sache quand il a réussi ou échoué, et il est utilisé pour échantillonner des objectifs que le robot doit pratiquer. Au moment des tests, il peut ensuite correspondre à une image d'objectif spécifiée par un humain en exécutant sa politique apprise."
Les chercheurs ont évalué l'efficacité de leur approche dans une série d'expériences dans lesquelles un agent artificiel a manipulé des objets inédits dans un environnement créé à l'aide de la plate-forme de simulation MuJuCo. De façon intéressante, leur méthode de formation a permis à l'agent robotique d'acquérir automatiquement des compétences qu'il pourrait ensuite appliquer à de nouvelles situations. Plus précisement, le robot était capable de manipuler une variété d'objets, généraliser les stratégies de manipulation qu'il a précédemment acquises à de nouveaux objets qu'il n'avait pas rencontrés lors de l'entraînement.
"Nous sommes très enthousiastes à propos de deux résultats de ce travail, " dit Nair. " D'abord, nous avons découvert que nous pouvons former une politique pour pousser des objets dans le monde réel sur environ 20 objets, mais la politique apprise peut également pousser d'autres objets. Ce type de généralisation est la principale promesse des méthodes de deep learning, et nous espérons que c'est le début de formes de généralisation bien plus impressionnantes à venir."
Remarquablement, dans leurs expériences, Nair et ses collègues ont pu former une politique à partir d'un ensemble de données fixe d'interactions sans avoir à collecter une grande quantité de données en ligne. C'est une réalisation importante, comme la collecte de données pour la recherche en robotique est généralement très coûteuse, et être capable d'acquérir des compétences à partir d'ensembles de données fixes rend leur approche beaucoup plus pratique.
À l'avenir, le modèle d'apprentissage auto-supervisé développé par les chercheurs pourrait aider au développement de robots capables de s'attaquer à une plus grande variété de tâches sans s'entraîner individuellement sur un large éventail de compétences. En attendant, Nair et ses collègues prévoient de continuer à tester leur approche dans des environnements simulés, tout en recherchant des moyens de l'améliorer davantage.
"Nous poursuivons maintenant quelques axes de recherche différents, y compris la résolution de tâches avec une bien plus grande diversité visuelle, ainsi que de résoudre un grand nombre de tâches simultanément et de voir si nous sommes capables d'utiliser la solution sur une tâche pour accélérer la résolution de la tâche suivante, " a déclaré Nair.
© 2019 Réseau Science X