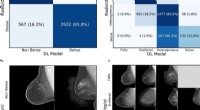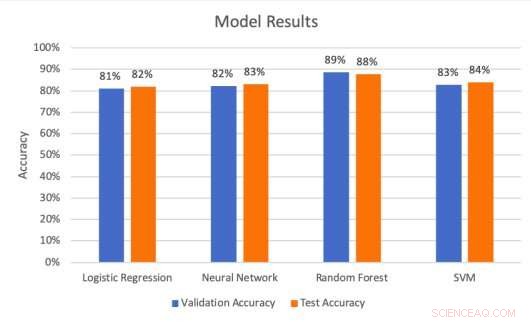
Résultats du modèle sur les ensembles de validation et de test. Crédit :Middlebrook &Sheik.
Deux étudiants et chercheurs de l'Université de San Francisco (USF) ont récemment tenté de prédire les hits des panneaux d'affichage à l'aide de modèles d'apprentissage automatique. Dans leur étude, prépublié sur arXiv, ils ont formé quatre modèles sur des données liées aux chansons extraites à l'aide de l'API Web Spotify, et ensuite évalué leurs performances en prédisant quelles chansons deviendraient des tubes.
"Je suis un grand fan de musique, et j'écoute de la musique toute la journée; pendant mon trajet, au travail, et entre amis, " Kai Middlebrook, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Le printemps dernier, J'ai commencé un projet de recherche sur la classification automatique des genres musicaux avec le professeur David Guy Brizan à l'Université de San Francisco (USF). Le projet nécessitait une grande quantité de données musicales, et les services de streaming de musique populaires ont exactement le type de données dont j'avais besoin."
Alors qu'il travaillait sur un projet lié à la classification automatique des genres musicaux, Middlebrook a appris que Spotify permet aux développeurs d'accéder à ses données musicales. Cela l'a encouragé à commencer à expérimenter avec l'API Web Spotify pour collecter des données pour ses études. Une fois qu'il a terminé les recherches liées à la classification des genres, cependant, il a mis l'API de côté pendant un certain temps.
"Quelques mois après, mon ami Kian, qui est aussi data scientist et aime la musique, et j'ai eu une discussion sur la musique, " Middlebrook a dit. " À un moment donné au cours de la conversation, l'idée généralement répandue que « toutes les chansons à succès sonnent de la même manière » a été évoquée. On ne croyait pas forcément que c'était vrai, mais l'idée nous a fait nous demander :et si les chansons à succès partageaient certaines similitudes ? Cela semblait possible, alors Kian et moi avons décidé d'approfondir l'enquête."
Middlebrook et Cheikh, qui avait auparavant collaboré au projet de classification des genres, a décidé de mener une enquête plus approfondie en utilisant des données extraites de Spotify. Ce nouveau projet serait également la dernière affectation de leur cours d'exploration de données à l'USF.
"Nous collaborions sur plusieurs autres projets pour divers cours, il était donc logique de rester ensemble, " Kian Cheikh, un autre chercheur impliqué dans l'étude, a déclaré TechXplore. "Le tube de Lil Nas X "Old Town Road" venait de sortir de nulle part, et était au sommet du Billboard Hot 100. Kai et moi nous sommes demandé si un ordinateur aurait pu prédire son ascension, ou si c'était juste un single qui sortait du champ gauche. Ce qui a commencé comme un simple projet final s'est terminé par l'épuisement de tous les modèles d'apprentissage supervisé de pointe sur un vaste ensemble de données pour répondre à une simple question :cette chanson sera-t-elle un succès ?"
Dans leur étude, Middlebrook et Sheik ont utilisé l'API Web Spotify pour collecter des données pour 1,8 million de chansons, qui comprenait des fonctionnalités telles que le tempo d'une chanson, clé, valence, etc. Ils ont ensuite également collecté environ 30 ans de données à partir du graphique Billboard Hot 100.
"Notre objectif était de voir si les chansons à succès partageaient des caractéristiques similaires, et si oui, si ces fonctionnalités pourraient être utilisées pour prédire quelles chansons seraient des tubes à l'avenir, ", a déclaré Middlebrook.
Les chercheurs ont formé et évalué quatre modèles différents :une régression logistique, un réseau de neurones, une machine à vecteurs de support (SVM) et une architecture de forêt aléatoire (RF). Pendant la formation, ces modèles ont analysé une variété de caractéristiques de chansons, y compris le tempo, clé, valence, énergie, acoustique, la danse et le volume.
"Quand on lui donne une chanson, nos modèles l'étiqueteraient avec un un ou un zéro, " Middlebrook a expliqué. "Une chanson étiquetée avec un signifie que le modèle prédit que la chanson a été un succès. Une chanson étiquetée avec un zéro signifie que le modèle prédit que la chanson n'était pas un succès."
Le modèle de régression logistique formé par les chercheurs suppose que les données de chansons peuvent être linéairement séparées en deux catégories :les hits et les non-hits. Le modèle attribue un poids à chaque caractéristique de la chanson, puis utilise ces pondérations pour prédire si une chanson appartient à la catégorie « hit » ou « non-hit ».
Les modèles de régression logistique présentent deux avantages importants :l'interprétabilité et la rapidité. En d'autres termes, ce type d'architecture facilite l'interprétation de la relation entre les variables explicatives (i.e., les caractéristiques de la chanson) et la variable de réponse (c'est-à-dire, touché ou non touché), et il peut également être formé relativement rapidement.
Le deuxième modèle formé par les chercheurs était une architecture RF. Ce modèle fonctionne en combinant une grande quantité de blocs de construction appelés arbres de décision.
"Essentiellement, un arbre de décision peut être considéré comme un modèle qui utilise une série de questions oui/non pour séparer les données, " dit Middlebrook. " Ils sont interprétables, mais enclin à suradapter les données. Le surapprentissage signifie qu'un modèle mémorise les données d'apprentissage en les ajustant trop étroitement. Le problème avec le surapprentissage est que le modèle peut ne pas apprendre cette relation réelle entre les caractéristiques de la chanson et la popularité de la chanson, car les données contiennent souvent du bruit non pertinent. »
Pour éviter le problème de surapprentissage, le modèle de forêt aléatoire utilisé par Middlebrook et Sheik combine des centaines de milliers d'arbres de décision, dont chacun est entraîné sur un sous-ensemble différent des données d'entraînement et un sous-ensemble différent des caractéristiques de la chanson. Le modèle fait ensuite une prédiction (c'est-à-dire, décide si une chanson est un succès ou non) en faisant la moyenne de la prédiction de chaque arbre et en combinant ces résultats.
"Dans notre cas d'utilisation, l'avantage du modèle de forêt aléatoire est sa flexibilité, " Middlebrook a déclaré. "Il est plus flexible qu'un modèle linéaire (par exemple, la régression logistique)."
Les troisième et quatrième modèles formés par les chercheurs, à savoir les architectures SVM et réseaux de neurones, sont tous deux non linéaires et sont donc plus difficiles à interpréter. Le modèle SVM fonctionne en essayant de trouver "l'hyperplan" qui sépare le mieux les données dans les deux catégories (c'est-à-dire, coups ou non). L'architecture du réseau de neurones, d'autre part, utilise une couche cachée avec dix filtres pour apprendre des données de la chanson.
Parmi les quatre modèles utilisés par Middlebrook et Sheik, le modèle de régression logistique est le plus simple à interpréter, tandis que celui basé sur le réseau de neurones est le plus difficile. Les deux autres modèles se situent quelque part au milieu.
"Généralement, ces modèles prédisent en fonction des contraintes qu'ils développent grâce à l'entraînement, " a déclaré Sheik. "Chaque modèle a été formé sur le même ensemble de classificateurs sonores. La sortie des modèles est testée par rapport à la vérité historique de l'API Billboard, si oui ou non la piste donnée a déjà figuré sur la liste Billboard Hot 100. Nous avons utilisé une flotte d'ordinateurs à l'USF pour faire le calcul et après quelques semaines de calcul pur, nous avions calculé les paramètres optimaux pour chaque modèle."
Les chercheurs ont effectué une série d'évaluations pour tester dans quelle mesure les quatre modèles pouvaient prédire les hits des panneaux d'affichage. Ils ont constaté que l'architecture SVM atteignait le taux de précision le plus élevé (99,53 %), tandis que le modèle de forêt aléatoire a atteint le meilleur taux de précision (88 pour cent) et le meilleur taux de rappel (85,51 pour cent).
"Le rappel exprime la capacité de trouver toutes les instances pertinentes dans un ensemble de données, tandis que la précision exprime quelle proportion de données que notre modèle dit était pertinente était réellement pertinente, " Middlebrook a expliqué. " En d'autres termes, rappel nous indiquent la probabilité que notre modèle prédit avec précision un coup réel en tant que coup. La précision nous indique la proportion de hits prédits qui étaient réellement des hits."
Selon les chercheurs, si les maisons de disques utilisaient l'un de ces modèles pour prédire quelles chansons auront le plus de succès, ils choisiraient probablement un modèle avec un taux de précision élevé plutôt qu'un modèle avec un taux de précision élevé. En effet, un modèle qui atteint une précision élevée assume moins de risques, car il est moins probable de prédire qu'une chanson qui n'a pas eu de succès deviendra un succès.
"Les maisons de disques ont des ressources limitées, " Middlebrook a déclaré. " S'ils versent ces ressources dans une chanson que le modèle prédit sera un succès et que cette chanson ne le devient jamais, alors le label peut perdre beaucoup d'argent. Donc, si une maison de disques veut prendre un peu plus de risques avec la possibilité de sortir plus de disques à succès, ils pourraient choisir d'utiliser notre modèle de forêt aléatoire. D'autre part, si une maison de disques veut prendre moins de risques tout en sortant quelques tubes, ils devraient utiliser notre modèle SVM."
Middlebrook et Sheik ont découvert que prédire un hit sur un panneau d'affichage en fonction des caractéristiques de l'audio d'une chanson est, En réalité, possible. Dans leurs futures recherches, les chercheurs prévoient d'étudier d'autres facteurs qui pourraient contribuer au succès des chansons, comme la présence sur les réseaux sociaux, expérience d'artiste, et l'influence de l'étiquette.
"Nous pouvons imaginer un monde où les maisons de disques qui sont constamment à la recherche de nouveaux talents sont inondées de mix-tapes et de démos des" prochains artistes en vogue, "" dit Cheikh. "Les gens n'ont que peu de temps pour écouter de la musique avec des oreilles humaines, donc "oreilles artificielles, " comme nos algorithmes, peut permettre aux maisons de disques de former un modèle pour le type de son qu'elles recherchent et de réduire considérablement le nombre de chansons qu'elles doivent elles-mêmes prendre en compte."
Des classificateurs comme ceux développés par Middlebrook et Sheik pourraient finalement aider les maisons de disques à décider dans quelles chansons investir. Bien que l'idée d'utiliser l'apprentissage automatique pour parcourir les démos puisse intéresser l'industrie de la musique, Sheik prévient que cela pourrait également avoir des conséquences indésirables.
"Bien que cela puisse être un avenir opportun, la perspective d'un « billot » proverbial auquel les artistes doivent se mesurer a le potentiel de devenir une chambre d'écho, ou une situation où la nouvelle musique doit ressembler à de la vieille musique pour être diffusée à la radio, " a déclaré Sheik. " Les créateurs de contenu sur des plateformes telles que YouTube, qui utilise également des algorithmes pour décider quelles vidéos sont montrées aux masses, ont dénoncé les pièges de forcer les artistes à travailler pour une machine."
Selon Cheikh, si les entreprises et les producteurs commencent à utiliser des algorithmes pour prendre des décisions artistiques, ces modèles doivent être conçus de manière à ne pas freiner le progrès de l'art. Les architectures développées par les deux chercheurs de l'USF, cependant, ne sont pas encore en mesure d'y parvenir.
"Le biais de nouveauté et d'autres caractéristiques peu orthodoxes devront être introduits et inventés pour que la musique dans son ensemble n'approche pas une singularité culturelle aux mains de l'opportunité, " a conclu Cheikh.
© 2019 Réseau Science X