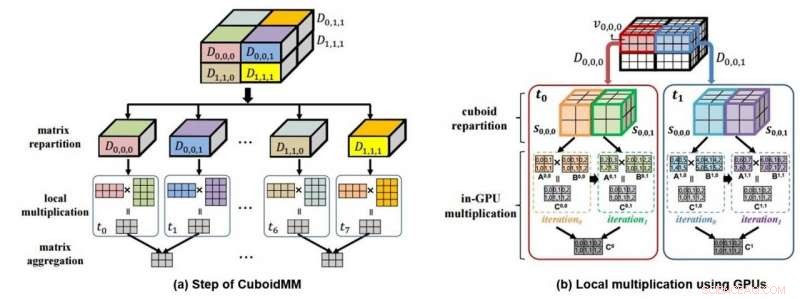
Il s'agit d'un diagramme mimétique (a) de multiplication de données 3D via CuboidMM et d'un diagramme mimétique (b) de calcul de traitement de données à l'aide de GPU. Crédit :DGIST
La DGIST a annoncé le 4 juillet que l'équipe du professeur Min-Soo Kim du Département d'ingénierie de l'information et de la communication a développé la technologie DistME (Distributed Matrix Engine) qui peut analyser 100 fois plus de données 14 fois plus rapidement que les technologies existantes. Cette nouvelle technologie devrait être utilisée dans l'apprentissage automatique qui nécessite un traitement de données volumineuses ou divers domaines industriels pour analyser des données à grande échelle à l'avenir.
Données « matrice », qui exprime des nombres en ligne et en colonne, est la forme de données la plus largement utilisée dans divers domaines tels que l'apprentissage automatique et la technologie scientifique. Alors que « SystemML » et « ScaLAPACK » sont évalués comme les technologies les plus populaires pour analyser les données matricielles, mais la capacité de traitement de la technologie existante a récemment atteint ses limites avec la taille croissante des données. Il est particulièrement difficile de faire des multiplications, qui sont nécessaires au traitement des données, pour l'analyse de données volumineuses avec les méthodes existantes, car elles ne peuvent pas effectuer d'analyse et de traitement élastiques et nécessitent une énorme quantité de transfert de données réseau pour le traitement.
En réponse, L'équipe du professeur Kim a développé une méthode de multiplication matricielle distribuée différente de celle existante. Aussi appelé CuboidMM, cette méthode forme une multiplication matricielle dans un hexaèdre 3-D, puis divise et traite en plusieurs morceaux appelés cuboïdes. La taille optimale du cuboïde est déterminée de manière flexible en fonction des caractéristiques des matrices, c'est à dire., la taille, la dimension, et la rareté de la matrice, afin de minimiser les coûts de communication. CuboidMM inclut non seulement toutes les méthodes existantes mais peut également effectuer une multiplication matricielle avec un coût de communication minimum. En outre, L'équipe du professeur Kim a conçu une technologie de traitement de l'information en combinant avec GPU (Graphics Processing Unit) qui a considérablement amélioré les performances de la multiplication matricielle.
La technologie DistME développée par l'équipe du professeur Kim a augmenté la vitesse de traitement en combinant CuboidMM avec GPU, qui est respectivement 6,5 et 14 fois plus rapide que ScaLAPACK et SystemML et peut analyser des données matricielles 100 fois plus volumineuses que SystemML. Il devrait ouvrir une nouvelle applicabilité de l'apprentissage automatique dans divers domaines nécessitant un traitement de données à grande échelle, notamment les centres commerciaux en ligne et les SNS.
Le professeur Kim du Département d'ingénierie de l'information et de la communication a déclaré :« La technologie d'apprentissage automatique, qui a attiré l'attention du monde entier, présente des limitations en termes de vitesse d'analyse des mégadonnées sous forme matricielle et de taille du traitement de l'analyse. La technologie de traitement de l'information développée cette fois-ci peut surmonter ces limitations et sera utile non seulement dans l'apprentissage automatique, mais également dans des applications dans des domaines plus larges d'applications d'analyse de données scientifiques et technologiques."
Cette recherche a été participé par Donghyoung Han, un doctorat étudiant au Département d'Ingénierie de l'Information et de la Communication en tant que premier auteur et a été présenté le 3 juillet à l'ACM SIGMOD 2019, la conférence académique la plus renommée dans le domaine des bases de données tenue à Amsterdam, Pays-Bas.