Crédit :KTH L'Institut royal de technologie
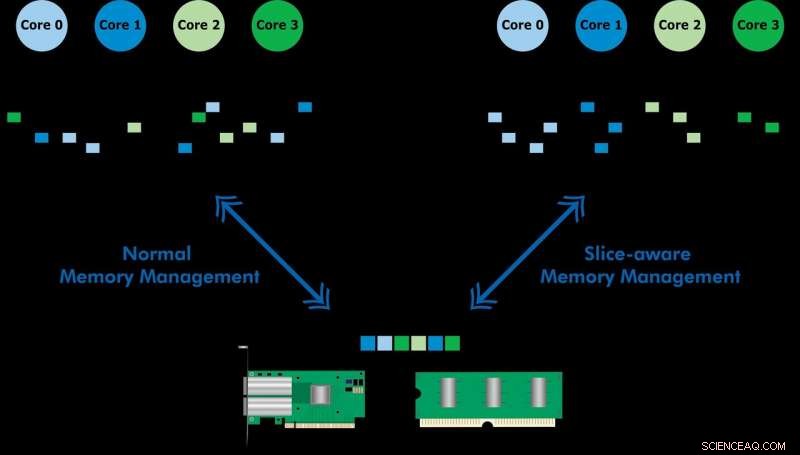
Développé avec Ericsson Research, le schéma de gestion de la mémoire sensible aux tranches permet d'accéder plus rapidement aux données fréquemment utilisées via le cache de mémoire de dernier niveau (LLC) d'un processeur Intel Xeon. En établissant un magasin clé-valeur et en allouant de la mémoire de manière à ce qu'elle corresponde à la tranche LLC la plus appropriée, ils ont démontré à la fois le traitement de paquets à grande vitesse et l'amélioration des performances d'un magasin clé-valeur. L'équipe a utilisé le schéma proposé pour implémenter un outil appelé CacheDirector, qui rend Data Direct I/O (DDIO) sensible aux tranches et a publié un article de conférence, Tirez le meilleur parti du cache de dernier niveau dans les processeurs Intel, qui a été présenté à EuroSys 2019 au printemps.
"À l'heure actuelle, un serveur recevant des paquets de 64 octets à 100 Gbit/s n'a que 5,12 nanosecondes pour traiter chaque paquet avant que le suivant n'arrive, " dit le co-auteur Alireza Farshin, doctorant au laboratoire de systèmes de réseaux de KTH. Mais si les données sont acheminées vers la bonne tranche de cache dans le processeur, il est accessible plus rapidement, ce qui permet un traitement plus rapide de plus de paquets, en moins de 5 nanosecondes.
Data Direct I/O (DDIO) envoie des paquets à des tranches aléatoires, ce qui est loin d'être efficace. Compte tenu de l'architecture de cache non uniforme (NUCA) actuelle, la solution de gestion de cache est inestimable, déclare le professeur KTH Dejan Kostic, qui a dirigé la recherche.
"Lorsqu'il est combiné avec l'introduction d'une marge dynamique dans le kit de développement de plans de données (DPDK), l'en-tête du paquet peut être placé dans la tranche de la LLC la plus proche du cœur de traitement concerné. Par conséquent, le noyau peut accéder aux paquets plus rapidement tout en réduisant le temps de file d'attente, " il dit.
« Notre travail démontre que tirer parti des améliorations en nanosecondes de la latence peut avoir un impact important sur les performances des applications s'exécutant sur des systèmes informatiques déjà hautement optimisés, " dit Farshin. L'équipe a constaté que pour un processeur fonctionnant à 3,2 GHz, CacheDirector peut économiser jusqu'à environ 20 cycles par accès à la LLC, ce qui équivaut à 6,25 nanosecondes. Cela accélère le traitement des paquets et réduit les latences de queue des chaînes de services optimisées de virtualisation des fonctions réseau (NFV) fonctionnant à 100 Gbit/s jusqu'à 21,5 %.