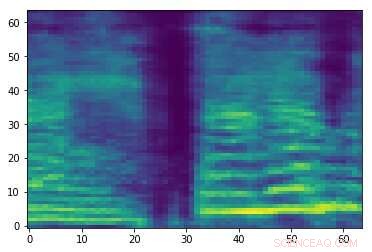
Spectrogramme d'un signal audio aléatoire. Crédit :Esmailpour, Cardinal &Lemeiras Koerich.
Les attaques audio adverses sont de petites perturbations qui ne sont pas perceptibles par les humains et sont intentionnellement ajoutées aux signaux audio pour altérer les performances des modèles d'apprentissage automatique (ML). Ces attaques soulèvent de sérieuses inquiétudes quant à la sécurité des modèles de ML, car ils peuvent les amener à faire des erreurs et finalement générer des prédictions erronées.
Chercheurs de l'École de Technologie Supérieure, partie de l'Université du Québec au Canada ont récemment développé une nouvelle approche qui pourrait aider à sécuriser les outils de classification audio contre les attaques contradictoires. Dans leur papier, prépublié sur arXiv, ils passent en revue certaines des attaques accusatoires existantes les plus puissantes et leur impact sur les performances des modèles de ML courants, proposer ensuite une approche qui pourrait contrer ces attaques.
"À l'heure actuelle, il existe de nombreux classificateurs puissants et rapides (à l'exécution) en termes de précision, à savoir les classificateurs d'apprentissage en profondeur (par exemple, les réseaux de neurones convolutifs), qui peut même surpasser le niveau humain des médias (par exemple, la parole, image, vidéo, animation, texte, etc.) reconnaissance et régression, "Mohammad Esmaeilpour, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Le talon d'Achille de ces algorithmes avancés est leur vulnérabilité aux entrées qui contiennent des perturbations soigneusement conçues, connu sous le nom d'attaques contradictoires.
Les attaques adverses fonctionnent en produisant des échantillons qui ressemblent étroitement à des échantillons d'entraînement légitimes, mais cela conduit en fait un ou des modèles de ML à générer des étiquettes erronées avec des niveaux de confiance élevés. Dans la recherche en ML, s'il y a suffisamment de données pour former un classificateur, le principal défi n'est plus d'améliorer sa précision de reconnaissance, mais assurant sa résilience face aux attaques adverses.
"Les attaques adverses sont des menaces actives pour tous les algorithmes basés sur les données, même ceux formés sur de petits ensembles de données, " a déclaré Esmaeilpour. " Cela a suscité notre intérêt pour étudier la menace d'attaques contradictoires pour les applications de reconnaissance audio et vocale, puisque tous les smartphones sont désormais équipés d'un assistant vocal virtuel tel que Siri, Assistant Google et Cortana."
Dans leur étude, Esmaeilpour et ses collègues ont mené des expériences impliquant des ensembles de données audio environnementales, plutôt que des ensembles de données vocales. Néanmoins, à l'avenir, leur approche pourrait également être étendue à la reconnaissance vocale, ce qui aiderait à protéger les assistants vocaux contre les attaques contradictoires.
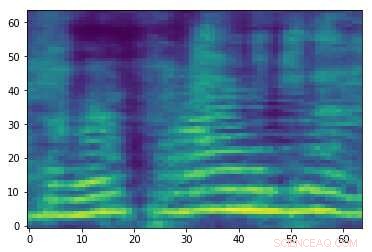
Spectrogramme contradictoire conçu associé au signal audio dans la première image. Bien que les deux images soient similaires, ils ont des étiquettes différentes, suggérant qu'une attaque est en cours. Crédit :Esmailpour, Cardinal &Lemeiras Koerich.
« Notre objectif principal dans cet article était d'étudier la menace d'attaques contradictoires pour les classificateurs audio conventionnels et d'apprentissage en profondeur et, idéalement, de proposer un algorithme plus fiable en termes de résilience contre certaines attaques courantes comme référence vers une véritable classification audio robuste, " a expliqué Esmaeilpour. " Nous voulions faire un juste équilibre pour les classificateurs dans la précision de la reconnaissance, complexité de calcul, et la robustesse contre les attaques adverses."
Généralement, les classificateurs qui sont plus robustes contre les attaques adverses atteignent une précision de reconnaissance inférieure, et vice versa. Dans leur étude, les chercheurs se sont concentrés sur le recyclage accusatoire, l'une des techniques de défense existantes les plus valides qui n'obscurcissent pas les informations de gradient. Malgré ses avantages, cette stratégie de défense particulière est coûteuse (comme les attaques puissantes sont coûteuses, le recyclage contradictoire à l'aide de ces attaques sera plus coûteux) et peut affecter négativement les performances de reconnaissance d'un classificateur.
« Le cas idéal pour nous serait de proposer un classificateur audio sans obscurcissement de gradient et sans recyclage contradictoire qui apprend de manière inhérente des « caractéristiques robustes », " a déclaré Esmaeilpour. " Notre scénario de classification comprend plusieurs étapes, principalement amélioration du spectrogramme (représentation 2D pour les signaux audio), réduction de dimensionnalité à l'aide d'une technique de décomposition algébrique, et lissage en utilisant un auto-encodeur à débruitage convolutif, où les deux dernières étapes (empilées ensemble) ont montré des impacts positifs sur la suppression de petites perturbations antagonistes potentielles inconnues."
Après avoir passé en revue certaines des attaques contradictoires les plus puissantes et leurs effets sur les performances des modèles de ML, les chercheurs ont extrait des caractéristiques des spectrogrammes traités par les modèles, les a organisés dans un livre de codes et formé un algorithme de machine à vecteurs de support (SVM) sur ce livre de codes. Dans leur pipeline de formation, ils n'ont pas mis en œuvre de techniques de détection d'attaques contradictoires proactives ou réactives ni d'algorithmes de défense.
« Notre objectif principal était « d'apprendre des vecteurs de caractéristiques robustes » sans aucun surcoût de pré- ou de post-traitement pour détecter des échantillons contradictoires potentiels, ", a expliqué Esmaeilpour. "Nos résultats montrent que notre classificateur proposé surpasse les algorithmes d'apprentissage en profondeur et conventionnels de pointe contre cinq types d'attaques adverses puissantes pour certains ensembles de données audio environnementales pratiques."
Esmaeilpour et ses collègues ont statistiquement prouvé la vulnérabilité des classificateurs conventionnels (c'est-à-dire des classificateurs qui apprennent à partir de l'espace des caractéristiques) et des algorithmes d'apprentissage en profondeur (c'est-à-dire des algorithmes qui apprennent à partir de données brutes) contre les attaques contradictoires. Selon les chercheurs, il n'existe actuellement aucun algorithme fiable basé sur les données pour la classification audio qui soit également robuste contre les attaques contradictoires. Parmi les modèles existants, les approches basées sur le deep learning semblent être les moins sécurisées contre ces attaques, même s'ils atteignent généralement la précision de reconnaissance la plus élevée.
"Le scénario de classification que nous avons proposé dans notre article utilise un SVM avec noyau polynomial comme classificateur final, " dit Esmaeilpour. " Cependant, l'application d'un auto-encodeur à débruitage convolutif au-dessus d'une décomposition en valeurs singulières suivie d'un regroupement non supervisé de vecteurs de caractéristiques robustes accélérés extraits pourrait aider à apprendre plus de composants structurels et probablement des caractéristiques robustes, ce qui pourrait nous permettre d'atteindre un équilibre raisonnable entre la précision de la reconnaissance (comparable aux performances de pointe) et la robustesse contre cinq attaques adverses puissantes courantes.
Bien que les résultats recueillis par les chercheurs soient très prometteurs, ils peuvent varier en fonction du jeu de données utilisé ou de l'application spécifique d'un classificateur, ils ne sont donc pas encore généralisables. À l'avenir, leur étude pourrait éclairer le développement d'autres classificateurs mieux équipés contre les attaques contradictoires, sans présenter de pertes substantielles de performance (c'est-à-dire la précision de la reconnaissance).
« L'apprentissage des fonctionnalités robustes est un problème ouvert et nous n'avons toujours pas une idée claire de la manière de le résoudre correctement ; il est en cours d'étude par notre équipe de recherche et certains résultats seront publiés prochainement, » dit Esmaeilpour. « Pendant ce temps, nous travaillons sur un nouveau, technique d'attaque adverse forte et rapide visant à utiliser cette attaque pour entraîner de manière contradictoire le modèle d'apprentissage (ce qui améliore sa robustesse) et également enregistrer les performances de reconnaissance du modèle avant de l'entraîner.
© 2019 Réseau Science X