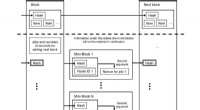
Les chercheurs examinent le problème de la navigation d'une position de départ à une position de but. Leur approche (WayPtNav) se compose d'un module de perception basé sur l'apprentissage et d'un module de planification basé sur un modèle dynamique. Le module de perception prédit un point de cheminement sur la base de l'observation d'image RVB à la première personne actuelle. Ce point de cheminement est utilisé par le module de planification basé sur un modèle pour concevoir un contrôleur qui régule en douceur le système jusqu'à ce point de cheminement. Ce processus est répété pour l'image suivante jusqu'à ce que le robot atteigne l'objectif. Crédit :Bansal et al.
Des chercheurs de l'UC Berkeley et de Facebook AI Research ont récemment développé une nouvelle approche pour la navigation des robots dans des environnements inconnus. Leur approche, présenté dans un article pré-publié sur arXiv, combine des techniques de contrôle basées sur des modèles avec une perception basée sur l'apprentissage.
Le développement d'outils permettant aux robots de naviguer dans les environnements environnants est un défi clé et permanent dans le domaine de la robotique. Au cours des dernières décennies, les chercheurs ont essayé de résoudre ce problème de diverses manières.
La communauté de recherche sur le contrôle a principalement étudié la navigation pour un agent (ou système) connu dans un environnement connu. Dans ces cas, un modèle dynamique de l'agent et une carte géométrique de l'environnement dans lequel il va naviguer sont disponibles, par conséquent, des schémas de contrôle optimal peuvent être utilisés pour obtenir des trajectoires fluides et sans collision pour que le robot atteigne un emplacement souhaité.
Ces schémas sont généralement utilisés pour contrôler un certain nombre de systèmes physiques réels, comme les avions ou les robots industriels. Cependant, ces approches sont quelque peu limitées, car ils nécessitent une connaissance explicite de l'environnement dans lequel un système va naviguer. Dans la communauté de la recherche sur l'apprentissage, d'autre part, la navigation robotique est généralement étudiée pour un agent inconnu explorant un environnement inconnu. Cela signifie qu'un système acquiert des politiques pour mapper directement les lectures des capteurs embarqués pour contrôler les commandes de bout en bout.
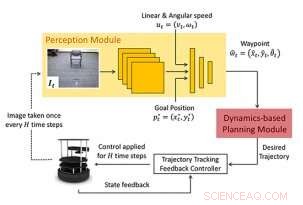
Cadre proposé :La nouvelle approche de la navigation consiste en un module de perception basé sur l'apprentissage et un module de planification basé sur un modèle dynamique. Le module de perception se compose d'un CNN qui émet un prochain état ou point de cheminement souhaité. Ce point de cheminement est utilisé par le module de planification basé sur un modèle pour concevoir un contrôleur afin de réguler en douceur le système jusqu'au point de cheminement. Crédit :Bansal et al.
Ces approches peuvent avoir plusieurs avantages, car ils permettent d'apprendre des politiques sans aucune connaissance du système et de l'environnement dans lequel il naviguera. Néanmoins, des études antérieures suggèrent que ces techniques ne se généralisent pas bien entre différents agents. En outre, l'apprentissage de telles politiques nécessite souvent un grand nombre d'échantillons de formation.
"Dans ce document, nous étudions la navigation des robots dans des environnements statiques sous l'hypothèse d'une mesure parfaite de l'état du robot, " les chercheurs ont écrit dans leur article. " Nous faisons l'observation cruciale que les problèmes les plus intéressants impliquent un système connu dans un environnement inconnu. Cette observation motive la conception d'une approche factorisée qui utilise l'apprentissage pour s'attaquer à des environnements inconnus et exploite un contrôle optimal en utilisant la dynamique du système connu pour produire une locomotion fluide. »
L'équipe de chercheurs de l'UC Berkeley et de Facebook a formé un modèle basé sur un réseau de neurones convolutifs (CNN) sur des politiques de haut niveau, qui utilisent les observations d'images RVB actuelles pour produire une séquence d'états intermédiaires, ou « points de cheminement ». Ces points de cheminement guident finalement un robot vers l'emplacement souhaité en suivant un chemin sans collision, dans des environnements jusque-là inconnus.
Leur approche, navigation basée sur les waypoints (WayPtNav), couple essentiellement des techniques de contrôle basées sur des modèles avec une perception basée sur l'apprentissage. Le module de perception basé sur l'apprentissage génère des waypoints, qui guident le robot vers son emplacement cible via un chemin sans collision. Le planificateur basé sur un modèle, d'autre part, utilise ces waypoints pour générer une trajectoire fluide et réalisable dynamiquement, qui est ensuite exécuté sur le système en utilisant le contrôle de rétroaction.
Les chercheurs ont évalué leur approche sur un banc d'essai matériel, appelé TurtleBot2. Leurs tests ont recueilli des résultats très prometteurs, avec WayPtNav permettant la navigation dans des environnements encombrés et dynamiques, tout en surpassant une approche d'apprentissage de bout en bout.
"Nos expériences dans des environnements encombrés simulés du monde réel et sur un véhicule terrestre réel démontrent que l'approche proposée peut atteindre les objectifs de manière plus fiable et plus efficace dans de nouveaux environnements par rapport à une alternative purement basée sur l'apprentissage de bout en bout, ", ont écrit les chercheurs.
La nouvelle approche présentée par cette équipe de chercheurs pourrait améliorer la navigation des robots dans de nouveaux environnements intérieurs. Des études futures pourraient essayer d'améliorer encore WayPtNav, remédier à certaines de ses limites actuelles.
"Notre approche proposée suppose une estimation parfaite de l'état du robot et utilise une politique purement réactive, " les chercheurs ont expliqué. " Ces hypothèses et choix peuvent ne pas être optimaux, surtout pour les tâches à longue distance. L'intégration de la mémoire spatiale ou visuelle pour répondre à ces limitations serait des orientations futures fructueuses. »
© 2019 Réseau Science X