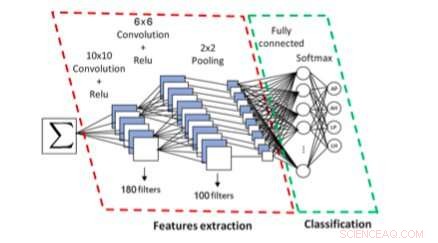
Le système basé sur CNN pour le script de symbole et l'identification de type. Crédit :Khazri &Echi.
Des chercheurs de l'Université de Tunis ont récemment proposé un nouveau système d'écriture de formule mathématique et d'identification de type, qui est basé sur les réseaux de neurones convolutifs (CNN). Leur méthode, présenté dans un article publié par Springer, peut automatiquement faire la distinction entre les formules imprimées/écrites à la main et les formules arabes/latines.
Dans les années récentes, les chercheurs ont essayé de développer des systèmes capables d'identifier les formes sous lesquelles un document est présenté, tels que la langue utilisée et si le texte est imprimé à la machine ou manuscrit, afin de sélectionner le système de reconnaissance approprié pour chaque document. La plupart de ces approches se concentrent sur l'identification de différentes formes de texte, alors que très peu sont conçus pour analyser des formules mathématiques.
"Dans ce contexte, nous présentons une nouvelle approche traitant le problème de l'identification du script, arabe ou latin ; et le genre, manuscrite ou imprimée à la machine, de formules mathématiques, ", ont écrit les chercheurs de l'Université de Tunis dans leur article. "Ce travail s'inscrit dans le cadre de nos recherches sur la reconnaissance hors ligne des formules mathématiques arabes."
Dans leur étude, les chercheurs ont présenté un système orienté syntaxe conçu pour reconnaître les symboles et analyser leur disposition. Pour reconnaître les symboles, leur approche utilise des caractéristiques statistiques et un classificateur de réseau Bayes.
Pour analyser la structure d'une formule, leur système utilise un schéma d'analyse descendant et ascendant basé sur la domination de l'opérateur. En d'autres termes, leur système exécute un lexical, analyse géométrique et syntaxique d'une formule, ce qui l'aide à identifier son écriture (latin vs arabe) et si elle a été manuscrite ou dactylographiée.
"L'analyse de formule consiste à appliquer, de l'opérateur dominant et de son contexte, la règle appropriée pour diviser les formules en sous-formules, qui sera analysé récursivement de la même manière, " expliquent les chercheurs dans leur article.
En utilisant un CNN, l'approche imaginée par les chercheurs extrait d'abord puis classe les composants connexes d'une formule. Les chercheurs ont formé et évalué leur système en utilisant des formules d'écriture latine des bases de données InftyMDB-1 et CROHME, ainsi que des formules arabes scannées à partir de livres de mathématiques ou écrites à la main par cinq écrivains différents.
"Le système de reconnaissance proposé a été testé sur des formules mathématiques complexes contenant une multiplication implicite, indices et exposants, avec des résultats satisfaisants, " les chercheurs ont écrit. "Ajouter plus de fonctionnalités, tester d'autres algorithmes de sélection de caractéristiques et choisir des classificateurs plus rapides devrait améliorer les performances du système proposé."
Globalement, les évaluations réalisées par les chercheurs ont donné des résultats très prometteurs, avec leur système atteignant un taux d'identification de 94,6 pour cent. L'analyseur utilisé pour analyser la structure des formules semble également très robuste, car il a atteint un taux de reconnaissance impressionnant de 97,63 pour cent. Dans leurs futurs travaux, les chercheurs prévoient d'améliorer les performances de leur système en développant davantage les filtres et l'architecture de CNN.
© 2019 Réseau Science X