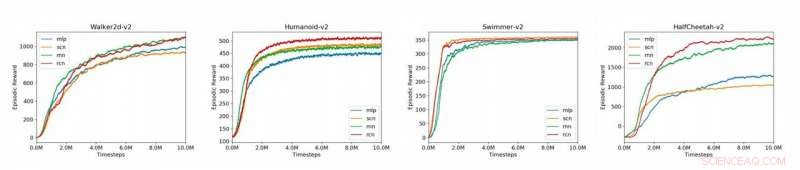
Graphiques comparant les modèles de base (MLP, SCN, RNN, RCN) pour les 4 environnements MuJoCo présentés dans l'article (Humanoid-v2, HalfCheetah-v2, Walker2d-v2, Nageur-v2). Crédit :Liu et al.
Les générateurs de motifs centraux (CPG) sont des circuits neuronaux biologiques qui peuvent produire des sorties rythmiques coordonnées sans nécessiter d'entrées rythmiques. Les CPG sont responsables de la plupart des mouvements rythmiques observés chez les organismes vivants, comme la marche, respirer ou nager.
Des outils pour modéliser efficacement les sorties rythmiques lorsqu'elles sont données des entrées arythmiques pourraient avoir des applications importantes dans une variété de domaines, dont les neurosciences, robotique et médecine. Dans l'apprentissage par renforcement, la plupart des réseaux existants utilisés pour modéliser les tâches des locomotives, tels que les modèles de base de perceptron multicouche (MLP), ne parviennent pas à générer des sorties rythmiques en l'absence d'entrées rythmiques.
Des études récentes ont proposé l'utilisation d'architectures qui peuvent diviser la politique d'un réseau en composants linéaires et non linéaires, tels que les filets de contrôle structurés (SCN), qui se sont avérés surpasser les MLP dans une variété d'environnements. Un SCN comprend un modèle linéaire pour le contrôle local et un module non linéaire pour le contrôle global, dont les résultats sont combinés pour produire l'action politique. En s'appuyant sur des travaux antérieurs avec les réseaux de neurones récurrents (RNN) et les SCN, une équipe de chercheurs de l'université de Stanford a récemment mis au point une nouvelle approche pour modéliser les CPG dans l'apprentissage par renforcement.
"Les CPG sont des circuits neuronaux biologiques capables de produire des sorties rythmiques en l'absence d'entrée rythmique, " Ademi Adeniji, l'un des chercheurs qui a mené l'étude, a déclaré Tech Xplore. "Les approches existantes pour la modélisation des CPG dans l'apprentissage par renforcement incluent le perceptron multicouche (MLP), un simple, réseau de neurones entièrement connecté, et le réseau de contrôle structuré (SCN), qui a des modules séparés pour le contrôle local et global. Notre objectif de recherche était d'améliorer ces lignes de base en permettant au modèle de capturer les observations précédentes, le rendant moins sujet aux erreurs dues au bruit d'entrée."

Capture d'écran de l'environnement HalfCheetah. Crédit :Liu et al.
Le réseau de contrôle récurrent (RCN) développé par Adeniji et ses collègues adopte l'architecture d'un SCN, mais utilise un RNN vanille pour le contrôle global. Cela permet au modèle d'acquérir des locaux, contrôle global et temporel.
"Comme SCN, notre RCN divise le flux d'informations en modules linéaires et non linéaires, " Nathaniel Lee, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Intuitivement, le module linéaire, effectivement une transformation linéaire, apprend les interactions locales, alors que le module non linéaire apprend les interactions globales."
Les approches SCN utilisent un MLP comme module non linéaire, tandis que le RCN imaginé par les chercheurs remplace ce module par un RNN. Par conséquent, leur modèle acquiert une « mémoire » des observations passées, codé par l'état caché du RNN, qu'il utilise ensuite pour générer des actions futures.
Les chercheurs ont évalué leur approche sur la plateforme OpenAI Gym, un environnement physique pour l'apprentissage par renforcement, ainsi que sur la dynamique multi-articulaire avec des tâches contractuelles (Mu-JoCo). Leur RCN correspondait ou surpassait les autres MLP et SCN de base dans tous les environnements testés, apprendre efficacement le contrôle local et global tout en acquérant des modèles à partir de séquences antérieures.

Capture d'écran de l'environnement Humanoïde. Crédit :Liu et al.
"Les CPG sont responsables d'un grand nombre de modèles biologiques rythmiques, " Jason Zhao, un autre chercheur impliqué dans l'étude, mentionné. "La capacité de modéliser le comportement CPG peut être appliquée avec succès à des domaines tels que la médecine et la robotique. Nous espérons également que nos recherches mettront en évidence l'efficacité du contrôle local/global ainsi que des architectures récurrentes pour la modélisation de la génération de motifs centraux dans l'apprentissage par renforcement."
Les résultats recueillis par les chercheurs confirment le potentiel des structures de type SCN pour modéliser les CPG pour l'apprentissage par renforcement. Leur étude suggère également que les RNN sont particulièrement efficaces pour modéliser les tâches des locomotives et que la séparation des modules de commande linéaires et non linéaires peut améliorer considérablement les performances d'un modèle.
"Jusque là, nous n'avons entraîné notre modèle qu'à l'aide de stratégies évolutives (ES), un optimiseur hors gradient, " a déclaré Vincent Liu, l'un des chercheurs impliqués dans l'étude. "À l'avenir, nous prévoyons d'explorer ses performances lors de sa formation avec l'optimisation des politiques proximales (PPO), un optimiseur sur gradient. En outre, les progrès du traitement du langage naturel ont montré que les réseaux de neurones convolutifs sont des substituts efficaces aux réseaux de neurones récurrents, à la fois en termes de performances et de calcul. On pourrait donc envisager d'expérimenter une architecture de réseau de neurones à retard, qui applique la convolution 1-D le long de l'axe du temps des observations passées."
© 2019 Réseau Science X