Crédit :CC0 Domaine public
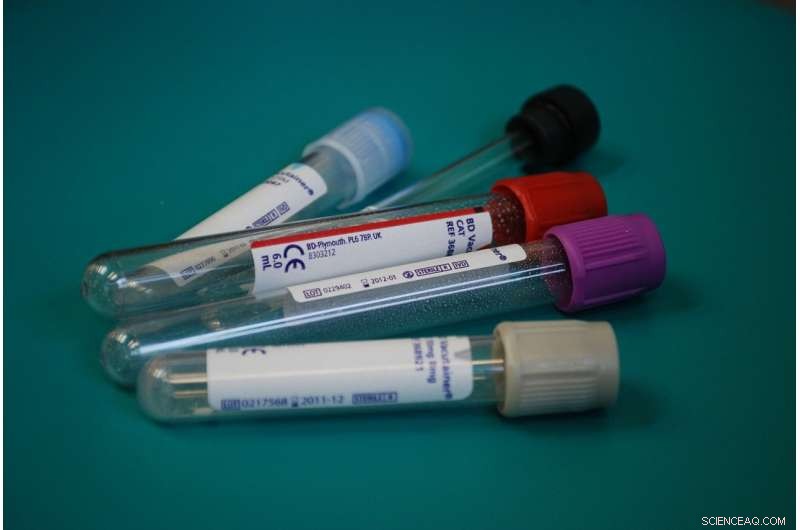
Les médecins des unités de soins intensifs sont confrontés à un dilemme permanent :chaque analyse de sang qu'ils commandent pourrait fournir des informations critiques, mais ajoute également des coûts et des risques pour les patients. Pour relever ce défi, des chercheurs de l'Université de Princeton développent une approche informatique pour aider les cliniciens à surveiller plus efficacement l'état des patients et à prendre des décisions sur les meilleures opportunités de commander des tests de laboratoire pour des patients spécifiques.
En utilisant les données de plus de 6, 000 malades, Les étudiants diplômés Li-Fang Cheng et Niranjani Prasad ont travaillé avec la professeure agrégée d'informatique Barbara Engelhardt pour concevoir un système qui pourrait à la fois réduire la fréquence des tests et améliorer le calendrier des traitements critiques. L'équipe a présenté ses résultats le 6 janvier au Pacific Symposium on Biocomputing à Hawaï.
L'analyse a porté sur quatre tests sanguins mesurant le lactate, créatinine, l'azote uréique du sang et les globules blancs. Ces indicateurs sont utilisés pour diagnostiquer deux problèmes dangereux pour les patients en soins intensifs :l'insuffisance rénale ou une infection systémique appelée sepsis.
"Étant donné que l'un de nos objectifs était de réfléchir à la possibilité de réduire le nombre de tests en laboratoire, nous avons commencé à regarder les panels [de test sanguin] qui sont les plus commandés, " dit Cheng, co-auteur principal de l'étude avec Prasad.
Les chercheurs ont travaillé avec la base de données MIMIC III, qui comprend des dossiers détaillés de 58, 000 admissions en soins intensifs au Beth Israel Deaconess Medical Center de Boston. Pour l'étude, les chercheurs ont sélectionné un sous-ensemble de 6, 060 enregistrements d'adultes qui sont restés en soins intensifs entre un et 20 jours et ont eu des mesures pour les signes vitaux courants et des tests de laboratoire.
« Ces données médicales, à l'échelle dont nous parlons, sont devenus disponibles au cours des deux dernières années de manière à pouvoir les analyser avec des méthodes d'apprentissage automatique, " dit Engelhardt, l'auteur principal de l'étude. "C'est super excitant, et une belle opportunité."
L'algorithme de l'équipe utilise une "fonction de récompense" qui encourage un ordre de test basé sur le degré d'information du test à un moment donné. C'est-à-dire, il y a une plus grande récompense à administrer un test s'il y a une probabilité plus élevée que l'état d'un patient soit significativement différent de la dernière mesure, et si le résultat du test est susceptible de suggérer une intervention clinique telle que l'instauration d'antibiotiques ou l'assistance respiratoire par ventilation mécanique. À la fois, la fonction ajoute une pénalité pour le coût monétaire du test et le risque pour le patient. Prasad a noté que, Dépendant de la situation, un clinicien pourrait décider de donner la priorité à l'un de ces composants par rapport aux autres.
Cette approche, connu sous le nom d'apprentissage par renforcement, vise à recommander des décisions qui maximisent la fonction de récompense. Cela traite la question des tests médicaux "comme le problème de prise de décision séquentielle qu'il est, où vous expliquez toutes les décisions et tous les états que vous avez vus au cours de la période précédente et décidez ce que vous devez faire à l'heure actuelle pour maximiser les récompenses à long terme pour le patient, " a expliqué Prasad, un étudiant diplômé en informatique.
Trier ces informations en temps opportun pour un environnement clinique nécessite une puissance de calcul considérable, dit Engelhardt, membre associé du corps professoral du Princeton Institute for Computational Science and Engineering (PICSciE). Cheng, un étudiant diplômé en génie électrique, a travaillé avec son co-conseiller Kai Li, le professeur Paul M. et Marcia R. Wythes en informatique, pour exécuter les calculs de l'équipe à l'aide des ressources PICSciE.
Pour tester l'utilité de la politique de tests en laboratoire qu'ils ont développée, les chercheurs ont comparé les valeurs de la fonction de récompense qui auraient résulté de l'application de leur politique aux schémas de test qui ont été réellement utilisés pour le 6, 060 patients dans l'ensemble de données d'entraînement, qui ont été admis à l'USI entre 2001 et 2012. Ils ont également comparé ces valeurs à celles qui auraient résulté des politiques de tests de laboratoire randomisés.
Pour chaque composant de test et de récompense, la politique générée par l'algorithme d'apprentissage automatique aurait conduit à des valeurs de récompense améliorées par rapport aux politiques réelles utilisées dans l'hôpital. Dans la plupart des cas, l'algorithme a également surpassé les politiques aléatoires. Le test de lactate était une exception notable; cela pourrait s'expliquer par la fréquence relativement faible des commandes de test de lactate, conduisant à un degré élevé de variance dans le caractère informatif du test.
Globalement, l'analyse des chercheurs a montré que leur politique optimisée aurait fourni plus d'informations que le régime de test réel suivi par les cliniciens. L'utilisation de l'algorithme aurait pu réduire le nombre de commandes de tests de laboratoire jusqu'à 44% dans le cas des tests de globules blancs. Ils ont également montré que cette approche aurait permis d'informer les cliniciens d'intervenir parfois des heures plus tôt lorsque l'état d'un patient commençait à se détériorer.
« Avec la politique de commande de tests en laboratoire développée par cette méthode, nous avons pu commander des laboratoires pour déterminer que la santé du patient s'était suffisamment dégradée pour nécessiter un traitement, en moyenne, quatre heures avant que le clinicien ne commence réellement le traitement sur la base des laboratoires commandés par le clinicien, " dit Engelhardt.
« Il y a une pénurie de lignes directrices fondées sur des preuves en soins intensifs concernant la fréquence appropriée des mesures de laboratoire, " dit Chamim Nemati, un professeur adjoint d'informatique biomédicale à l'Université Emory qui n'a pas participé à l'étude. "Des approches basées sur les données telles que celle proposée par Cheng et ses co-auteurs, lorsqu'il est combiné avec un aperçu plus approfondi du flux de travail clinique, ont le potentiel de réduire le fardeau de la cartographie et le coût des tests excessifs, et améliorer la connaissance de la situation et les résultats."
Le groupe d'Engelhardt collabore avec des scientifiques des données de l'équipe de soins de santé prédictifs de Penn Medicine pour introduire cette politique dans la clinique au cours des prochaines années. De tels efforts visent à "donner aux cliniciens les super-pouvoirs que d'autres personnes dans d'autres domaines sont donnés, " a déclaré Corey Chivers, scientifique principal des données de Penn. " Avoir accès à l'apprentissage automatique, l'intelligence artificielle et la modélisation statistique avec de grandes quantités de données" aideront les cliniciens "à prendre de meilleures décisions, et finalement améliorer les résultats pour les patients, " il ajouta.
"C'est l'une des premières fois que nous pourrons adopter cette approche d'apprentissage automatique et la mettre réellement en soins intensifs, ou en milieu hospitalier, et conseiller les soignants de manière à ce que les patients ne courent aucun risque, " dit Engelhardt. " C'est vraiment quelque chose de nouveau. "
Ce travail a été soutenu par le Helen Shipley Hunt Fund, qui soutient la recherche visant à améliorer la santé humaine; et le Fonds Eric et Wendy Schmidt pour l'innovation stratégique, qui soutient la recherche en intelligence artificielle et en apprentissage automatique.