Découverte, et mesurer le discours de haine contre l'islamophobie sur les réseaux sociaux. Crédit :John Gomez/Shutterstock
Dans un geste marquant, un groupe de députés a récemment publié une définition de travail du terme islamophobie. Ils l'ont défini comme "enraciné dans le racisme", et comme « un type de racisme qui cible les expressions de l'islamité ou de l'identité musulmane perçue ».
Dans notre dernier document de travail, nous voulions mieux comprendre la prévalence et la gravité de ce discours de haine islamophobe sur les réseaux sociaux. Un tel discours nuit aux victimes ciblées, crée un sentiment de peur parmi les communautés musulmanes, et contrevient aux principes fondamentaux d'équité. Mais nous avons été confrontés à un défi majeur :bien qu'extrêmement nocifs, Les discours de haine islamophobes sont en fait assez rares.
Des milliards de publications sont envoyées sur les réseaux sociaux chaque jour, et seul un très petit nombre d'entre eux contiennent une sorte de haine. Nous avons donc entrepris de créer un outil de classification utilisant l'apprentissage automatique qui détecte automatiquement si les tweets contiennent ou non de l'islamophobie.
Détecter les discours de haine islamophobes
D'énormes progrès ont été réalisés dans l'utilisation de l'apprentissage automatique pour classer de manière robuste les discours de haine plus généraux, à grande échelle et en temps opportun. En particulier, beaucoup de progrès ont été réalisés pour catégoriser le contenu selon qu'il est haineux ou non.
Mais le discours de haine islamophobe est bien plus nuancé et complexe que cela. Il couvre toute la gamme des attaques verbales, abuser et insulter les musulmans jusqu'à les ignorer ; de souligner comment ils sont perçus comme "différents" à suggérer qu'ils ne sont pas des membres légitimes de la société ; de l'agression au licenciement. Nous avons voulu prendre en compte cette nuance avec notre outil afin de pouvoir catégoriser si le contenu est ou non islamophobe et si l'islamophobie est forte ou faible.
Nous avons défini le discours de haine islamophobe comme « tout contenu produit ou partagé qui exprime une négativité aveugle contre l'islam ou les musulmans ». Cela diffère de mais est bien aligné avec la définition de travail des députés de l'islamophobie, décrit ci-dessus. Sous nos définitions, une forte islamophobie comprend des déclarations telles que "tous les musulmans sont des barbares", tandis que l'islamophobie faible comprend des expressions plus subtiles, tels que "Les musulmans mangent une nourriture si étrange".
Être capable de faire la distinction entre l'islamophobie faible et forte nous aidera non seulement à mieux détecter et éliminer la haine, mais aussi pour comprendre la dynamique de l'islamophobie, enquêter sur les processus de radicalisation où une personne devient progressivement plus islamophobe, et mieux accompagner les victimes.
Crédit :Vidgen et Yasseri
Réglage des paramètres
L'outil que nous avons créé s'appelle un classificateur d'apprentissage automatique supervisé. La première étape pour en créer un consiste à créer un ensemble de données de formation ou de test - c'est ainsi que l'outil apprend à attribuer des tweets à chacune des classes :faible islamophobie, une forte islamophobie et aucune islamophobie. La création de cet ensemble de données est un processus difficile et long car chaque tweet doit être étiqueté manuellement, la machine a donc une base à partir de laquelle apprendre. Un autre problème est que la détection des discours de haine est intrinsèquement subjective. Ce que je considère fortement islamophobe, vous pourriez penser que c'est faible, et vice versa.
Nous avons fait deux choses pour atténuer cela. D'abord, nous avons passé beaucoup de temps à créer des directives pour étiqueter les tweets. Seconde, nous avons demandé à trois experts d'étiqueter chaque tweet, et ont utilisé des tests statistiques pour vérifier à quel point ils étaient d'accord. Nous avons commencé avec 4, 000 tweets, échantillonné à partir d'un ensemble de données de 140 millions de tweets que nous avons collectés de mars 2016 à août 2018. La plupart des 4, 000 tweets n'exprimaient aucune islamophobie, nous en avons donc supprimé beaucoup pour créer un ensemble de données équilibré, composé de 410 forts, 484 faibles, et 447 aucun (au total, 1, 341 tweets).
La deuxième étape consistait à créer et à ajuster le classificateur en concevant des fonctionnalités et en sélectionnant un algorithme. Les fonctionnalités sont ce que le classificateur utilise pour attribuer réellement chaque tweet à la bonne classe. Notre principale caractéristique était un modèle d'incorporation de mots, un modèle d'apprentissage en profondeur qui représente des mots individuels comme un vecteur de nombres, qui peut ensuite être utilisé pour étudier la similitude des mots et l'utilisation des mots. Nous avons également identifié d'autres caractéristiques des tweets, comme l'unité grammaticale, sentiment et le nombre de mentions de mosquées.
Une fois que nous avons construit notre classificateur, la dernière étape consistait à l'évaluer, ce que nous avons fait en l'appliquant à un nouvel ensemble de données de tweets complètement invisibles. Nous avons sélectionné 100 tweets attribués à chacune des trois classes, donc 300 au total, et avons demandé à nos trois codeurs experts de les renommer. Cela permet d'évaluer les performances du classificateur, comparer les étiquettes attribuées par notre classificateur avec les étiquettes réelles.
La principale limitation du classificateur était qu'il avait du mal à identifier les tweets islamophobes faibles, car ceux-ci se chevauchaient souvent avec des tweets forts et non islamophobes. Cela dit, globalement, sa performance était solide. L'exactitude (le nombre de tweets correctement identifiés) était de 77 % et la précision de 78 %. En raison de notre processus de conception et de test rigoureux, nous pouvons être sûrs que le classificateur est susceptible de fonctionner de la même manière lorsqu'il est utilisé à grande échelle "dans la nature" sur des données Twitter invisibles.
Utilisation de notre classificateur
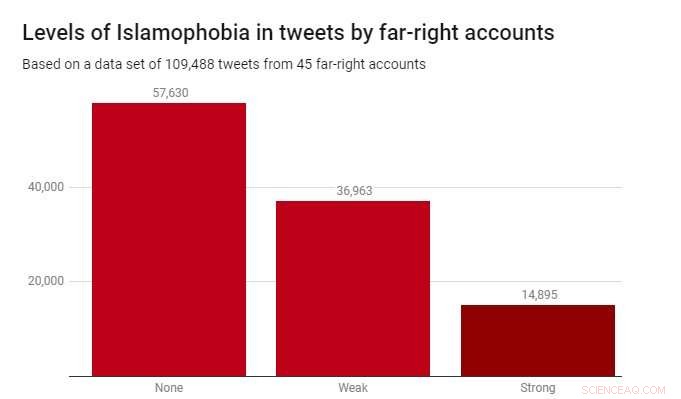
Nous avons appliqué le classificateur à un ensemble de données de 109, 488 tweets produits par 45 comptes d'extrême droite en 2017. Ceux-ci ont été identifiés par l'association caritative Hope Not Hate dans leurs rapports 2015 et 2017 sur l'état de la haine. Le graphique ci-dessous montre les résultats.
Alors que la plupart des tweets – 52,6 % – n'étaient pas islamophobes, L'islamophobie faible était considérablement plus répandue (33,8 %) que l'islamophobie forte (13,6 %). Cela suggère que la plupart de l'islamophobie dans ces récits d'extrême droite est subtile et indirecte, plutôt qu'agressif ou manifeste.
Détecter les discours de haine islamophobes est un défi réel et urgent pour les gouvernements, entreprises technologiques et universitaires. Malheureusement, c'est un problème qui ne disparaîtra pas – et il n'y a pas de solutions simples. Mais si nous voulons vraiment éliminer les discours de haine et l'extrémisme des espaces en ligne, et rendre les plateformes de médias sociaux sûres pour tous ceux qui les utilisent, alors nous devons commencer avec les outils appropriés. Notre travail montre qu'il est tout à fait possible de créer ces outils - non seulement pour détecter automatiquement le contenu haineux, mais aussi pour le faire de manière nuancée et fine.
Cet article est republié à partir de The Conversation sous une licence Creative Commons. Lire l'article original.