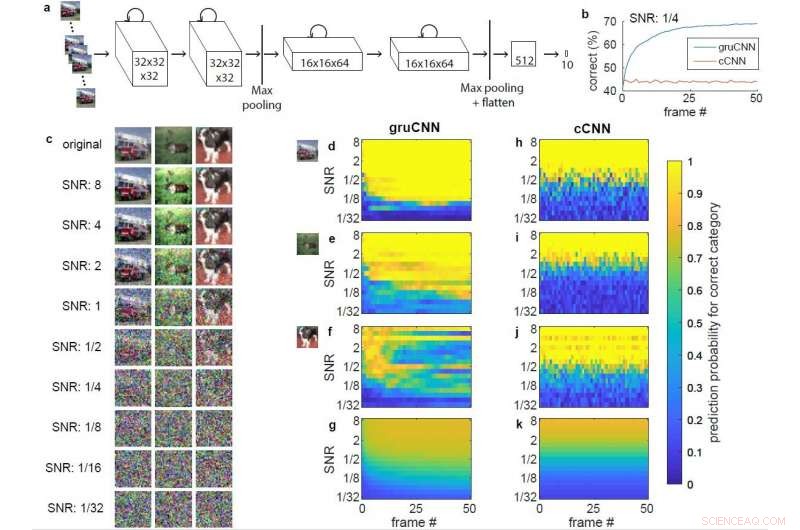
Architecture et exemples de données. a) Architecture de gruCNN. L'activité de chaque canal dépend à la fois de l'entrée actuelle et de l'état précédent. b) Performance de classification de l'exemple gruCNN et cCNN lorsque toutes les séquences de test avaient un SNR de 1/4. c) Image originale et image avec différents SNR pour un camion de pompier (catégorie camion) un renne (catégorie cerf), et un chien, affiché sans gigue. d–k) Probabilités prédites codées par couleur (sortie de softmax) de la catégorie d'image correcte (positive) pour gruCNN (d–g) et cCNN (h–k). Les axes horizontaux montrent les probabilités prédites sur 51 images, axes verticaux sur une plage de SNR. d) &h) et e) &i) correspondent aux performances dans les exemples camion de pompiers et rennes, respectivement. La probabilité prédictive à faible SNR continue de s'améliorer au fil des trames pour les prédictions gruCNN, mais sont relativement constants pour le cCNN. f) &j) Données pour le troisième exemple (le chien), dans lequel le gruCNN échoue (ce qui est rare) tandis que le cCNN prédit correctement la catégorie au plus SNRs. La probabilité moyenne prédite pour la catégorie d'image correcte (positive) pour les 10, 000 images de test sont affichées dans g) et k). Crédit :Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Au cours des dernières années, Les réseaux de neurones convolutifs classiques (cCNN) ont conduit à des avancées remarquables en vision par ordinateur. Beaucoup de ces algorithmes peuvent désormais catégoriser des objets dans des images de bonne qualité avec une grande précision.
Cependant, dans des applications réelles, comme la conduite autonome ou la robotique, les données d'imagerie comprennent rarement des photos prises dans des conditions d'éclairage idéales. Souvent, les images dont les CNN auraient besoin pour traiter les objets occlus, distorsion de mouvement, ou de faibles rapports signal sur bruit (SNR), soit en raison d'une mauvaise qualité d'image ou d'un faible niveau d'éclairage.
Bien que les cCNN aient également été utilisés avec succès pour débruiter les images et améliorer leur qualité, ces réseaux ne peuvent pas combiner les informations de plusieurs images ou séquences vidéo et sont donc facilement surpassés par les humains sur des images de faible qualité. Jusqu'à S. Hartmann, chercheur en neurosciences à la Harvard Medical School, a récemment réalisé une étude qui aborde ces limites, introduire une nouvelle approche CNN pour l'analyse des images bruitées.
Hartmann, qui a une formation en neurosciences, a passé plus d'une décennie à étudier comment les humains perçoivent et traitent les informations visuelles. Dans les années récentes, il est devenu de plus en plus fasciné par les similitudes entre les CNN profonds utilisés dans la vision par ordinateur et le système visuel du cerveau.
Dans le cortex visuel, zone du cerveau spécialisée dans le traitement des entrées visuelles, la majorité des connexions neuronales sont faites dans les directions latérales et de rétroaction. Cela suggère qu'il y a beaucoup plus dans le traitement visuel que les techniques utilisées par les cCNN. Cela a motivé Hartmann à tester des couches convolutives qui intègrent un traitement récurrent, qui est vital pour le traitement des informations visuelles par le cerveau humain.
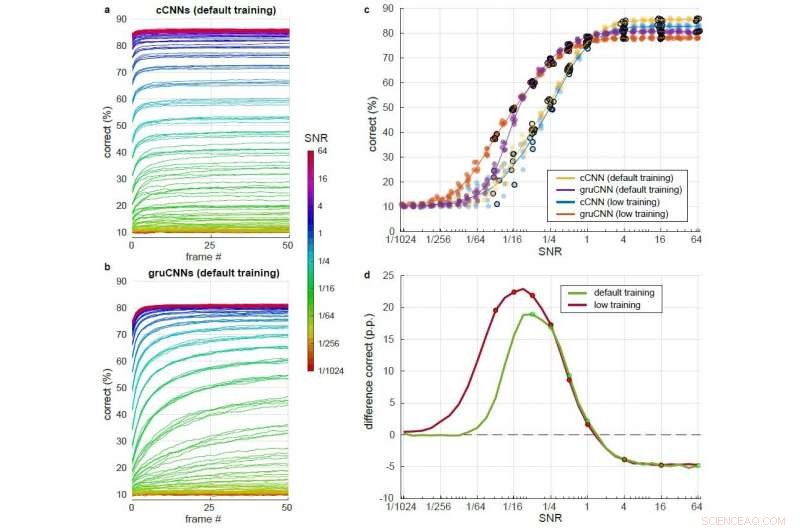
Comparaison détaillée de cCNN avec l'inférence bayésienne et les performances de gruCNN sur une large gamme de niveaux de SNR. Chaque architecture de modèle a été testée après une formation avec des SNR légèrement plus élevés (formation par défaut) et après une formation avec des SNR légèrement inférieurs (formation faible). a) &b) Pourcentage correct au cours de 51 images pour différents SNR (code couleur) en utilisant la formation par défaut pour a) le cCNN (avec inférence bayésienne) et b) le gruCNN. c) Points :classification correcte pour les architectures modèles à la dernière trame. La gigue dans les valeurs SNR a été ajoutée pour augmenter la lisibilité des tracés, mais n'était pas dans les données. Lignes :performances moyennes des cinq modèles par architecture. d) Performance moyenne des gruCNN moins performance moyenne des cCNN pour les modèles entraînés avec des SNR par défaut et inférieurs (vert et rouge, respectivement). Les niveaux de SNR utilisés pendant l'entraînement sont indiqués par des points. Crédit :Till S. Hartmann/arXiv:1811.08537 [cs.CV].
En utilisant des connexions récurrentes au sein des couches convolutives du CNN, L'approche de Hartmann garantit que les réseaux sont mieux équipés pour traiter le bruit des pixels, telles que celles présentes dans les images prises dans de mauvaises conditions d'éclairage. Testé sur des séquences vidéo bruitées simulées, les CNN récurrents (gruCNNs) ont de bien meilleurs résultats que les approches classiques, classer avec succès des objets dans des vidéos simulées de faible qualité, comme celles prises la nuit.
L'ajout de connexions récurrentes à une couche convolutive ajoute finalement une mémoire spatialement contrainte, permettant au réseau d'apprendre à intégrer les informations au fil du temps avant que le signal ne soit trop abstrait. Cette fonctionnalité peut être particulièrement utile lorsque la qualité du signal est faible, comme dans les images qui sont bruyantes ou prises dans de mauvaises conditions d'éclairage.
Dans son étude, Hartmann a découvert que les cCNN fonctionnaient bien sur les images avec des SNR élevés, gruCNNs, les a surpassés sur les images à faible SNR. Même en ajoutant des intégrations temporelles optimales de Bayes, qui permettent aux cCNN d'intégrer plusieurs cadres d'images, ne correspond pas aux performances de gruCNN. Hartmann a également observé qu'à de faibles SNR, Les prédictions de gruCNNs avaient des niveaux de confiance plus élevés que ceux produits par les cCNNs.
Alors que le cerveau humain a évolué pour voir dans l'obscurité, la plupart des CNN existants ne sont pas encore équipés pour traiter des images floues ou bruitées. En offrant aux réseaux la capacité d'intégrer des images dans le temps, l'approche conçue par Hartmann pourrait éventuellement améliorer la vision par ordinateur au point qu'elle correspond, voire dépasse, performances humaines. Cela pourrait être énorme pour des applications telles que les voitures autonomes et les drones, ainsi que dans d'autres situations où une machine a besoin de « voir » dans des conditions d'éclairage non idéales.
L'étude menée par Hartmann pourrait ouvrir la voie au développement de CNN plus avancés capables d'analyser des images prises dans des conditions de faible luminosité. L'utilisation de connexions récurrentes dans les premières étapes du traitement des réseaux de neurones pourrait considérablement améliorer les outils de vision par ordinateur, surmonter les limitations des approches CNN classiques dans le traitement d'images ou de flux vidéo bruités.
Comme prochaine étape, Hartmann pourrait élargir le champ de ses recherches en explorant les applications réelles des gruCNNs, les tester dans un large éventail de scénarios du monde réel. Potentiellement, son approche pourrait également être utilisée pour améliorer la qualité des vidéos amateurs ou tremblantes.
© 2018 Réseau Science X














