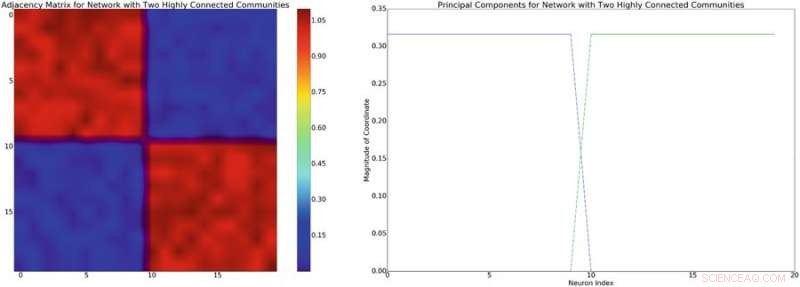
À gauche :exemple d'une matrice d'adjacence avec une structure de bloc-diagonale approximative. En supposant un modèle de mélange linéaire d'interactions neuronales, cette structure de réseau induira une covariance diagonale approximativement par blocs de structure similaire. A droite :les composantes principales associées à la matrice d'adjacence à gauche. Crédit :Mitchell &Petzold
Brian Mitchell et Linda Petzold, deux chercheurs de l'Université de Californie, ont récemment appliqué l'apprentissage par renforcement profond sans modèle aux modèles de dynamique neuronale, obtenir des résultats très prometteurs.
L'apprentissage par renforcement est un domaine de l'apprentissage automatique inspiré de la psychologie comportementale qui entraîne des algorithmes à accomplir efficacement des tâches particulières, en utilisant un système basé sur la récompense et la punition. Une étape importante dans ce domaine a été le développement du Deep-Q-Network (DQN), qui a été initialement utilisé pour former un ordinateur à jouer à des jeux Atari.
L'apprentissage par renforcement sans modèle a été appliqué à une variété de problèmes, mais DQN n'est généralement pas utilisé. La raison principale en est que DQN peut proposer un nombre limité d'actions, tandis que les problèmes physiques nécessitent généralement une méthode qui peut proposer un continuum d'actions.
En lisant la littérature existante sur le contrôle neuronal, Mitchell et Petzold ont remarqué l'utilisation généralisée d'un paradigme classique pour résoudre les problèmes de contrôle neuronal avec des stratégies d'apprentissage automatique. D'abord, l'ingénieur et l'expérimentateur s'accordent sur l'objectif et la conception de leur étude. Puis, ce dernier mène l'expérience et collecte les données, qui sera ensuite analysé par l'ingénieur et utilisé pour construire un modèle du système d'intérêt. Finalement, l'ingénieur développe un contrôleur pour le modèle et l'appareil met en œuvre ce contrôleur.
Résultats de l'expérience contrôlant l'oscillation dans l'espace des phases défini par une seule composante principale. Le premier tracé à partir du haut est un tracé de l'entrée dans la cellule actionnée au fil du temps ; le deuxième tracé en partant du haut est un tracé des pointes de l'ensemble du réseau, où différentes couleurs correspondent à différentes cellules ; le troisième tracé en partant du haut correspond au potentiel membranaire de chaque cellule au cours du temps; le quatrième à partir du graphique du haut montre l'oscillation de la cible ; le graphique du bas montre l'oscillation observée. La politique, malgré la fourniture d'entrée à une seule cellule, est capable d'induire approximativement l'oscillation de la cible dans l'espace des phases observé. Crédit :Mitchell &Petzold 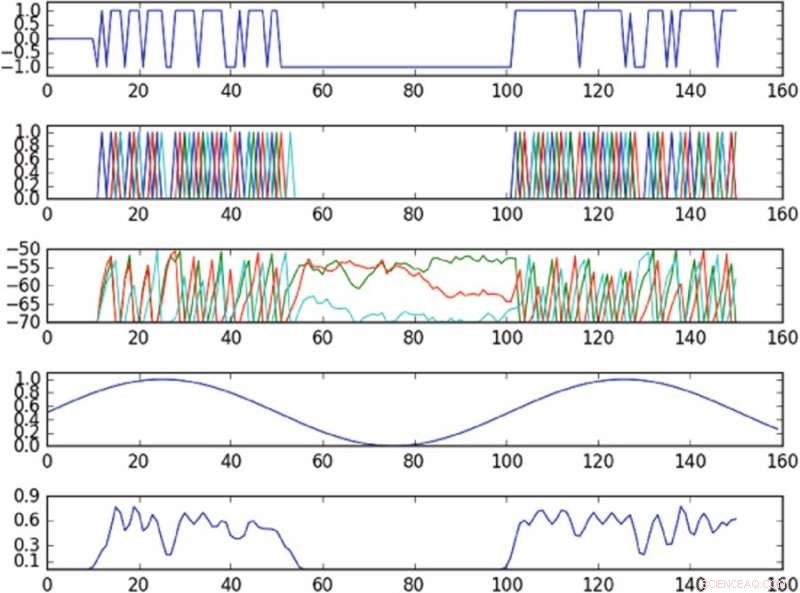
Les chercheurs ont adapté une méthode d'apprentissage par renforcement sans modèle appelée « gradients de politique déterministes profonds » (DDPG) et l'ont appliquée à des modèles de dynamique neuronale de bas et de haut niveau. Ils ont spécifiquement choisi DDPG car il offre un cadre très flexible, qui ne nécessite pas que l'utilisateur modélise la dynamique du système.
Des recherches récentes ont montré que les méthodes sans modèle nécessitent généralement trop d'expérimentation avec l'environnement, ce qui rend plus difficile leur application à des problèmes plus pratiques. Néanmoins, les chercheurs ont découvert que leur approche sans modèle fonctionnait mieux que les méthodes actuelles basées sur un modèle et était capable de résoudre des problèmes de dynamique neuronale plus difficiles, comme le contrôle des trajectoires à travers un espace de phase latent d'un réseau de neurones sous-actionné.
« Pour les problèmes que nous avons examinés dans cet article, les approches sans modèle étaient assez efficaces et ne nécessitaient pas beaucoup d'expérimentation, suggérant que pour les problèmes neuronaux, les contrôleurs à la pointe de la technologie sont plus utiles en pratique que les gens auraient pu le penser, " dit Mitchell.
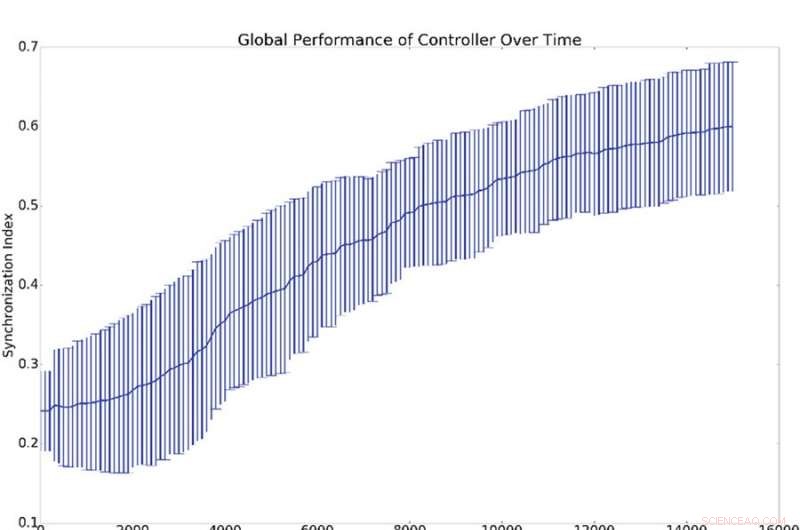
Résumé des résultats de 10 expériences de synchronisation. (a) Représente la moyenne et l'écart type de la synchronisation globale, (c'est-à-dire q de l'équation 16), par rapport au nombre de périodes de formation du contrôleur. (b) Affiche des histogrammes démontrant le niveau de synchronisation de tous les oscillateurs du réseau avec l'oscillateur de référence (c'est-à-dire qi de l'équation 16). C'est-à-dire, un point sur les courbes bleues ou vertes démontre la probabilité d'avoir une valeur donnée pour qi. L'histogramme bleu montre les décomptes avant l'entraînement tandis que l'histogramme vert montre les décomptes après l'entraînement. La synchronisation moyenne avec la référence, qi, est beaucoup plus élevé que la synchronisation globale, q, ce qui s'explique par le fait que la synchronisation avec la référence est plus facile à induire que la synchronisation globale. Crédit :Mitchell &Petzold
Mitchell et Petzold ont réalisé leur étude sous forme de simulation, par conséquent, d'importants aspects pratiques et de sécurité doivent être pris en compte avant que leur méthode ne puisse être introduite dans les milieux cliniques. Des recherches supplémentaires qui intègrent des modèles dans des approches sans modèle, ou qui pose des limites aux contrôleurs sans modèle, pourrait aider à améliorer la sécurité avant que ces méthodes n'entrent dans les milieux cliniques.
Dans le futur, les chercheurs prévoient également d'étudier comment les systèmes neuronaux s'adaptent au contrôle. Les cerveaux humains sont des organes hautement dynamiques qui s'adaptent à leur environnement et changent en réponse à une stimulation externe. Cela pourrait provoquer une compétition entre le cerveau et le contrôleur, en particulier lorsque leurs objectifs ne sont pas alignés.
"Dans de nombreux cas, nous voulons que le contrôleur gagne et la conception de contrôleurs qui gagnent toujours est un problème important et intéressant, " dit Mitchell. " Par exemple, dans le cas où le tissu contrôlé est une région malade du cerveau, cette région peut avoir une certaine progression que le contrôleur essaie de corriger. Dans de nombreuses maladies, cette progression peut résister au traitement (par exemple une tumeur s'adaptant à la chimiothérapie expulsée est un exemple canonique), mais les approches actuelles sans modèle ne s'adaptent pas bien à ce genre de changements. Améliorer les contrôleurs sans modèle pour mieux gérer l'adaptation de la part du cerveau est une direction intéressante que nous examinons. »
La recherche est publiée dans Rapports scientifiques .
© 2018 Tech Xplore














