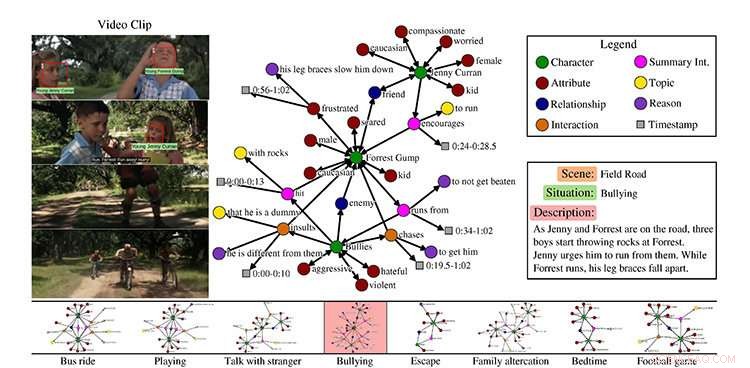
Un exemple du jeu de données MovieGraphs, scène du film Forrest Gump. Crédit :Université de Toronto
Si votre ami est triste, vous pouvez dire quelque chose pour les aider à remonter le moral. Si vous demandez à votre collègue de faire du café, ils connaissent les étapes pour accomplir cette tâche.
Mais comment les robots artificiellement intelligents, ou IA, apprendre à se comporter de la même manière que les humains ?
Des chercheurs de l'Université de Toronto présentent de nouvelles approches vers des IA socialement intelligentes, à la conférence Computer Vision and Pattern Recognition (CVPR), le premier événement annuel de vision par ordinateur cette semaine à Salt Lake City, Utah.
Comment apprend-on à un robot à se comporter ?
Dans leur article MovieGraphs:Towards Understanding Human-Centric Situations from Videos, Paul Vicol, un doctorat étudiant en informatique, Makarand Tapaswi, un chercheur post-doctoral, Lluis Castrejon, une maîtrise en informatique de l'Université de Toronto et maintenant un doctorat. étudiant à l'Institut des algorithmes d'apprentissage de l'Université de Montréal, et Sanja Fidler, professeur adjoint au département des sciences mathématiques et informatiques de l'Université de Toronto et au département d'informatique des trois campus, ont amassé un ensemble de données de clips vidéo annotés de plus de 50 films.
"MovieGraphs est une étape vers la prochaine génération d'agents cognitifs qui peuvent raisonner sur la façon dont les gens se sentent et sur les motivations de leurs comportements, " dit Vicol. "Notre objectif est de permettre aux machines de se comporter de manière appropriée dans des situations sociales. Nos graphiques capturent de nombreuses propriétés de haut niveau de situations humaines qui n'ont pas été explorées dans des travaux antérieurs."
Leur ensemble de données se concentre sur les films dans le drame, romance, et genres comiques, comme Forrest Gump et Titanic, et suit les personnages au fil du temps. Ils n'incluent pas les films de super-héros comme Thor car ils ne sont pas très représentatifs de l'expérience humaine.
"L'idée était d'utiliser les films comme proxy du monde réel, " dit Vicol.
Chaque clip, il dit, est associé à un graphique qui capture des détails riches sur ce qui se passe dans le clip :quels personnages sont présents, leurs relations, interactions entre eux ainsi que les raisons pour lesquelles ils interagissent, et leurs émotions.
Vicol explique que l'ensemble de données montre, par exemple, non seulement que deux personnes se disputent, mais de quoi ils se disputent, et les raisons pour lesquelles ils se disputent, qui proviennent à la fois d'indices visuels et de dialogues. L'équipe a créé son propre outil pour permettre l'annotation, ce qui a été fait par un seul annotateur pour chaque film.
"Tous les clips d'un film sont annotés consécutivement, et l'ensemble du graphique associé à chaque clip est créé par une seule personne, ce qui nous donne une structure cohérente dans chaque graphique, et entre les graphiques au fil du temps, " il dit.
Avec leur ensemble de données de plus de 7, 500 extraits, les chercheurs introduisent trois tâches, explique Vicol. Le premier est la récupération vidéo, sur la base du fait que les graphiques sont ancrés dans les vidéos.
"Donc, si vous effectuez une recherche en utilisant un graphique indiquant que Forrest Gump se dispute avec quelqu'un d'autre, et que les émotions des personnages sont tristes et en colère, alors vous pouvez trouver le clip, " il dit.
Le second est l'ordre d'interaction, qui fait référence à la détermination de l'ordre le plus plausible des interactions entre les personnages. Par exemple, il explique si un personnage devait faire un cadeau à un autre personnage, la personne recevant le cadeau dirait « merci ».
"Vous ne diriez généralement pas 'merci, ' puis recevez un cadeau. C'est une façon d'évaluer si nous capturons la sémantique des interactions."
Leur tâche finale est la prédiction de la raison basée sur le contexte social.
"Si nous nous concentrons sur une interaction, pouvons-nous déterminer la motivation derrière cette interaction et pourquoi elle s'est produite ? Il s'agit donc essentiellement d'essayer de prédire quand quelqu'un crie après quelqu'un d'autre, la phrase réelle qui expliquerait pourquoi, " il dit
Tapaswi dit que l'objectif final est d'apprendre le comportement.
"Imaginez par exemple dans un clip, la machine incarne essentiellement Jenny [du film Forrest Gump]. Quelle est une action appropriée pour Jenny ? Dans une scène, c'est pour encourager Forrest à fuir les intimidateurs. Nous essayons donc de faire en sorte que les machines apprennent le comportement approprié. »
« Approprié au sens où les films le permettent, bien sûr."

Capture d'écran :MIT CSAIL/VirtualHome :Simulation d'activités ménagères via des programmes
Comment un robot apprend-il les tâches ménagères ?
Dirigé par le professeur adjoint Antonio Torralba du Massachusetts Institute of Technology et Fidler de l'Université de Toronto, VirtualHome :Simulation d'activités ménagères via des programmes, forme un agent humain virtuel en utilisant le langage naturel et une maison virtuelle, pour que le robot puisse apprendre non seulement par le langage, mais en voyant, explique Jiaman Li, étudiant à la maîtrise en informatique de l'Université de Toronto, un auteur collaborateur avec U of T Ph.D. étudiant en informatique Wilson Tingwu Wang.
Li explique que l'action de haut niveau peut être « travailler sur ordinateur » et la description comprend :allumer l'ordinateur, assis devant, en tapant sur le clavier et en saisissant la souris pour faire défiler.
« Donc, si nous disons à un humain cette description, 'travailler sur ordinateur, ' l'humain peut effectuer ces actions tout comme les descriptions. Mais si nous disons simplement aux robots cette description, comment font-ils exactement ? Le robot n'a pas ce bon sens. Il faut des étapes très claires, ou des programmes."
Parce qu'il n'y a pas d'ensemble de données qui inclut toutes ces connaissances, elle dit que les chercheurs en ont construit un en utilisant une interface Web pour rassembler les programmes, qui fournissent le nom de l'action et la description.
"Ensuite, nous avons construit un simulateur afin d'avoir un humain virtuel dans une maison virtuelle qui peut effectuer ces tâches, " elle dit.
Pour sa part dans le projet en cours, Li utilise l'apprentissage en profondeur - une branche de l'apprentissage automatique qui entraîne les ordinateurs à apprendre - pour générer automatiquement des programmes à partir de texte ou de vidéo pour ces programmes.
Cependant, ce n'est pas une tâche facile d'effectuer chaque action dans le simulateur, dit Li, comme l'ensemble de données a généré plus de 5, 000 programmes.
"Simuler tout ce que l'on fait dans une maison est extrêmement difficile, et nous faisons un pas dans cette direction en mettant en œuvre les actions atomiques les plus fréquentes telles que la marche, asseoir, et ramasser, " dit Fidler.
"Nous espérons que notre simulateur sera utilisé pour entraîner des robots à des tâches complexes dans un environnement virtuel, avant de passer au monde réel."
MovieGraphs a été soutenu en partie par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG) et VirtualHome est soutenu en partie par le Réseau de matériel informatique pour les applications émergentes de détection intelligente (COHESA) du CRSNG.