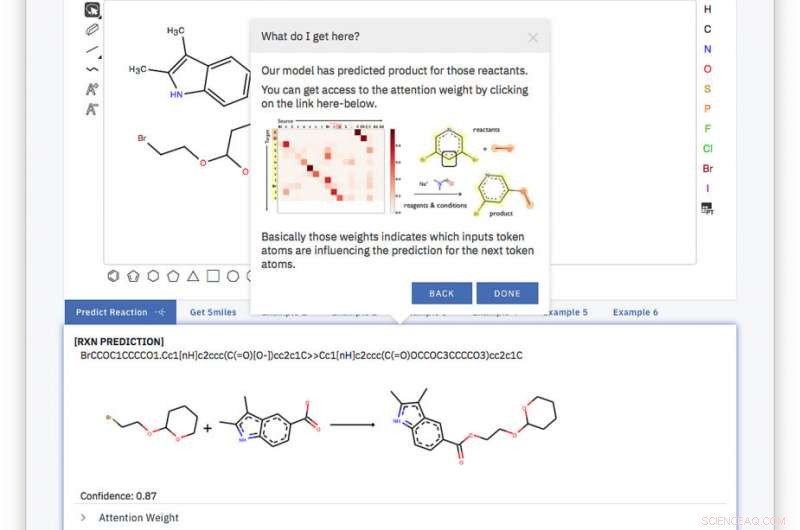
L'outil Web est simple, et le modèle est entraîné de bout en bout, entièrement piloté par les données et sans aide à interroger une base de données ou toute information externe supplémentaire. Crédit :IBM
Depuis plus de 200 ans, la synthèse de molécules organiques reste l'une des tâches les plus importantes de la chimie organique. Le travail des chimistes a des implications scientifiques et commerciales qui vont de la production d'aspirine à celle de nylon. Encore, peu a été fait pour changer radicalement les anciennes pratiques et permettre une nouvelle ère de productivité basée sur la science et les technologies pionnières de l'intelligence artificielle (IA).
Le défi des chimistes organiques dans des domaines tels que la chimie, la science des matériaux, pétrole et gaz, et les sciences de la vie, c'est qu'il y a des centaines de milliers de réactions et, alors qu'il est gérable d'en retenir quelques dizaines dans un domaine de spécialisation étroit, il est impossible d'être un généraliste expert.
Pour y remédier, nous nous sommes demandé, pouvons-nous utiliser le deep learning et l'intelligence artificielle pour prédire les réactions des composés organiques ?
D'abord, puisque nous avons étudié l'ingénierie et les sciences des matériaux, mais pas la chimie organique, nous avons dû frapper les livres. Il ne fallut pas longtemps avant que nous commencions à voir de la chimie organique partout—matin, midi et soir. Les atomes sont apparus à la place des lettres, molécules matérialisées à partir de mots et, alors, quelque chose d'incroyable s'est produit :une idée est née.
Nous avons réalisé que les jeux de données de chimie organique et les jeux de données linguistiques ont beaucoup en commun :ils dépendent tous les deux de la grammaire, sur les dépendances à longue portée, et une petite particule ou un mot comme « pas » peut changer tout le sens d'une phrase, tout comme la stéréochimie peut transformer la thalidomide en médicament ou en poison mortel.
En tant qu'anglophones non natifs, nous connaissons tous les deux les outils de traduction en ligne, qui ont fait des merveilles pour transformer l'anglais en français, et de l'allemand vers l'anglais, alors pourquoi ne pas essayer de les utiliser pour transformer des produits chimiques aléatoires en composés fonctionnels ?
Lors de la conférence NIPS 2017, nous présentons nos résultats :une application Web qui reprend l'idée de relier la chimie organique à un langage et applique des méthodes de traduction automatique neuronale de pointe pour passer de la conception de matériaux à la génération de produits à l'aide de séquences. modèles à séquencer (seq2seq).
Chimie 101
De retour au lycée, nous avons dû dessiner à la main les hexagones et pentagones et toutes les différentes lignes représentant les liaisons des molécules organiques. Nous avons maintenant mis au point un système qui prend exactement la même représentation et peut prédire comment les molécules réagiront en un clic.
L'outil global est simple, et le modèle est entraîné de bout en bout, entièrement piloté par les données et sans aide à interroger une base de données ou toute information externe supplémentaire. Avec cette approche, nous surpassons les solutions actuelles en utilisant leurs propres ensembles de formation et de test en atteignant une précision de 80,3 % et en établissant un premier score de 65,4 % sur un ensemble de données sur les réactions d'un seul produit bruyant extraites de brevets américains.
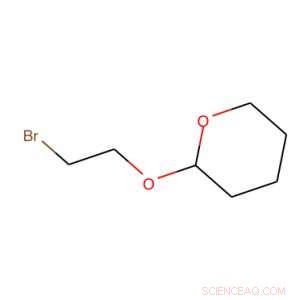
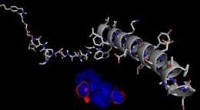
À l'aide de SOURIRE, cette molécule est traduite en BrCCOC1OCCCC1. Crédit :IBM
Le secret de notre outil est ce qu'on appelle un système d'entrée de ligne à entrée moléculaire simplifiée ou SMILES. SMILES représente une molécule comme une séquence de caractères. Par exemple, l'image de droite, devient BrCCOC1OCCCC1.
Nous avons entraîné notre modèle à l'aide d'un ensemble de données de réaction chimique librement disponible, ce qui correspond à 1 million de réactions de brevets.
À l'avenir, nous visons à améliorer le modèle et à améliorer notre précision en élargissant notre ensemble de données. Actuellement, nos données sont tirées d'informations accessibles au public dans les brevets américains publiés en ligne, mais il n'y a aucune raison pour que l'outil ne puisse pas être entraîné sur des données provenant d'autres sources, tels que les manuels de chimie et les publications scientifiques.
Nous prévoyons également de rendre cet outil accessible gratuitement au public sur le cloud début 2018.
Inscrivez-vous sur www.zurich.ibm.com/foundintranslation pour recevoir une alerte lorsque l'outil Web est prêt.