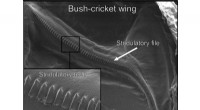
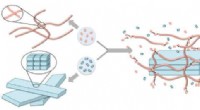
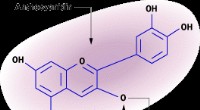
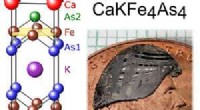
1. Unités discrètes:
* ADN: Les informations sont codées dans la séquence de quatre bases nucléotidiques:adénine (A), thymine (T), cytosine (C) et guanine (G).
* Code Morse: Les informations sont codées à l'aide d'une combinaison de points (.) Et de tirets (-).
2. Combinant des unités:
* ADN: Ces quatre bases sont organisées en séquences spécifiques, formant des gènes et, finalement, l'ensemble du génome.
* Code Morse: Les points et les tirets sont combinés dans des modèles spécifiques pour représenter des lettres, des nombres et une ponctuation.
3. Signification de la séquence:
* ADN: L'ordre des bases dans une séquence d'ADN détermine la séquence d'acides aminés d'une protéine, qui dicte sa fonction.
* Code Morse: L'arrangement spécifique des points et des tirets détermine la signification d'un message.
4. Décodage:
* ADN: Les enzymes spécialisées et les machines cellulaires lisent la séquence d'ADN et la traduisent en protéines.
* Code Morse: Un opérateur qualifié décode le modèle des points et des tirets pour comprendre le message.
Cependant, il existe des différences importantes:
* complexité: Le code de l'ADN est beaucoup plus complexe, codant pour non seulement les instructions de création de protéines mais également des éléments régulatrices et d'autres processus biologiques.
* Redondance: L'ADN a un certain niveau de redondance, ce qui signifie que plusieurs codons peuvent coder pour le même acide aminé. Le code Morse n'est pas redondant.
* médium: L'ADN est une molécule physique, tandis que le code Morse est un système de symboles transmis par divers supports (par exemple, lumière, son, ondes radio).
en résumé:
L'ADN et le code Morse sont des systèmes de codage d'informations à l'aide d'unités discrètes organisées en séquences spécifiques. Bien que le niveau de complexité et le milieu de transmission diffèrent considérablement, ils partagent un concept fondamental de représentation des informations à travers des séquences à motifs.