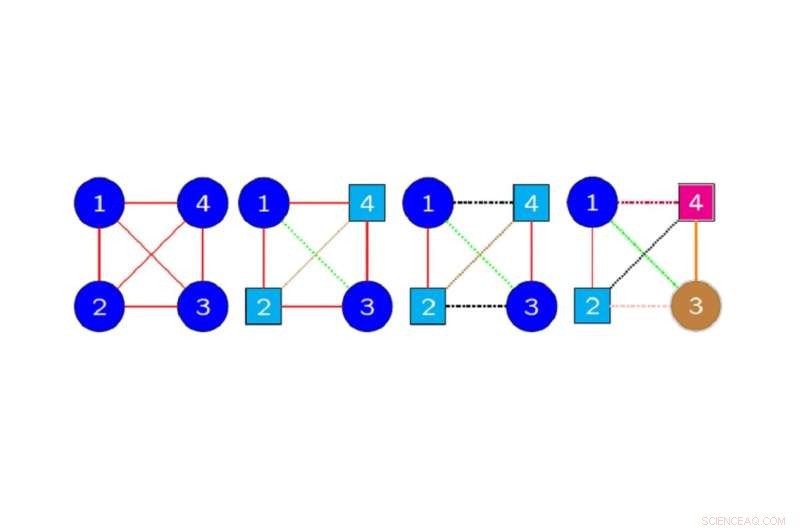
Exemples de graphes colorés désignant des symétries de données à quatre dimensions :les sommets et les arêtes de la même couleur et de la même forme dans un graphe sont mappés les uns aux autres par une permutation de symétrie préservant la structure des données. Crédit :Hideyuki Ishi, Université métropolitaine d'Osaka
Une équipe de recherche internationale dirigée par des scientifiques de l'Université métropolitaine d'Osaka a développé une méthode pour identifier les symétries dans les données multidimensionnelles à l'aide de techniques statistiques bayésiennes.
Cette approche statistique nécessite des calculs complexes d'intégrales, qui ne sont souvent considérées que comme des approximations. Dans leur nouvelle étude, l'équipe de recherche a réussi à dériver de nouvelles formules intégrales exactes. Leurs découvertes contribuent à améliorer la précision des méthodes d'identification des symétries de données, en étendant éventuellement leurs applications à des domaines d'intérêt plus larges, tels que l'analyse génétique.
Les symétries dans la nature rendent les choses belles; les symétries dans les données rendent le traitement des données efficace. Cependant, la complexité de l'identification de tels modèles dans les données a toujours tourmenté les chercheurs. Des scientifiques de l'Université métropolitaine d'Osaka et leurs collègues ont franchi une étape importante dans la détection des symétries dans les données multidimensionnelles en utilisant les statistiques bayésiennes. Leurs conclusions ont été publiées dans The Annals of Statistics .
Les statistiques bayésiennes ont été à l'honneur ces dernières années en raison de l'amélioration des performances des ordinateurs et de leurs applications potentielles en intelligence artificielle. La statistique bayésienne est une approche statistique qui, même lorsque les données sont insuffisantes, dérive la probabilité qu'un événement se produise en fixant d'abord une probabilité a priori, puis, chaque fois que de nouvelles informations sont obtenues, en calculant une probabilité a posteriori - une mise à jour de la probabilité a priori - que le événement se produira. Le calcul des probabilités a posteriori nécessite des calculs complexes d'intégrales et n'est donc souvent considéré que comme une approximation.
L'équipe internationale comprenant le professeur Hideyuki Ishi de l'Université métropolitaine d'Osaka, le professeur Piotr Graczyk de l'Université d'Angers, le professeur Bartosz Kołodziejek de l'Université de technologie de Varsovie et la regrettée professeur Hélène Massam de l'Université York (Toronto) a réussi à dériver de nouvelles formules intégrales exactes , et dans le développement d'une méthode pour rechercher des symétries dans des données multidimensionnelles à l'aide de techniques statistiques bayésiennes.
Lorsque la quantité de données à traiter augmente, le modèle optimal doit être sélectionné parmi un grand nombre de modèles, ce qui rend difficile la résolution précise du problème. Pour relever ce défi, l'équipe a également développé un algorithme efficace pour obtenir une solution approximative même dans de tels cas.
Selon le professeur Ishi, « les symétries dans les données sont omniprésentes dans une grande variété de modèles. Une fois les symétries identifiées, le nombre de paramètres requis pour afficher la structure des données et le nombre d'échantillons requis pour déterminer les paramètres peuvent être considérablement réduit. À l'avenir, les résultats de cette recherche devraient contribuer à l'analyse génétique, en découvrant des chromosomes qui ont la même fonction à différents endroits. La sélection de modèles bayésiens montre un comportement extrêmement polarisé lorsque les modèles sont erronés














