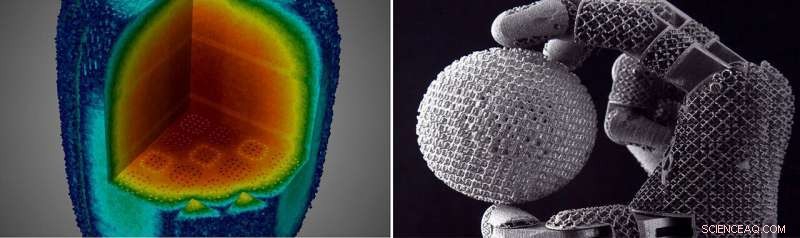
Les ordinateurs Exascale seront utilisés pour résoudre des problèmes dans un large éventail d'applications scientifiques, notamment pour simuler le fonctionnement à vie de petits réacteurs nucléaires modulaires (à gauche) et pour comprendre la relation complexe entre les processus d'impression 3D et les propriétés des matériaux (à droite). Crédit : Laboratoire national d'Oak Ridge
Les ordinateurs Exascale devraient bientôt faire leurs débuts, y compris Frontier à l'Oak Ridge Leadership Computing Facility (OLCF) du Département de l'énergie des États-Unis (DOE) et Aurora à l'Argonne Leadership Computing Facility (ALCF), les deux installations pour les utilisateurs du DOE Office of Science, en 2021. Ces systèmes informatiques de nouvelle génération devraient dépasser de cinq à dix fois la vitesse des supercalculateurs les plus puissants d'aujourd'hui. Cette amélioration des performances permettra aux scientifiques de s'attaquer à des problèmes autrement insolubles en termes de complexité et de temps de calcul.
Mais atteindre un tel niveau de performance nécessitera des adaptations logicielles. Par exemple, OpenMP—les interfaces de programmation d'applications standard pour le calcul parallèle à mémoire partagée, ou l'utilisation de plusieurs processeurs pour accomplir une tâche - devra évoluer pour prendre en charge la superposition de différentes mémoires, les accélérateurs matériels tels que les unités de traitement graphique (GPU), diverses architectures de calcul exascale, et les dernières normes pour C++ et d'autres langages de programmation.
Faire évoluer OpenMP vers exascale avec le projet SOLLVE
En septembre 2016, le DOE Exascale Computing Project (ECP) a financé un projet de développement logiciel appelé SOLLVE (pour Scaling OpenMP via Low-Level Virtual Machine for Exascale Performance and Portability) pour aider à cette transition. L'équipe du projet SOLLVE, dirigée par le laboratoire national de Brookhaven du DOE et composée de collaborateurs de l'Argonne du DOE, Laurent Livermore, et les laboratoires nationaux d'Oak Ridge, et Georgia Tech—a conçu, exécution, et standardiser les fonctionnalités clés d'OpenMP que les développeurs d'applications ECP ont identifiées comme importantes.
Piloté par SOLLVE et sponsorisé par ECP, La Computational Science Initiative (CSI) de Brookhaven Lab a organisé un hackathon OpenMP de quatre jours du 29 avril au 2 mai, organisé conjointement avec Oak Ridge et IBM. Le hackathon OpenMP est le dernier d'une série de hackathons proposés par CSI, y compris ceux qui se concentrent sur les GPU NVIDIA et les processeurs multicœurs Intel Xeon Phi.
"OpenMP subit des changements substantiels pour répondre aux exigences des futurs systèmes informatiques exascale, " a déclaré le coordinateur de l'événement local Martin Kong, un informaticien au sein du groupe d'informatique et de mathématiques de CSI et représentant du Brookhaven Lab au sein du comité d'examen de l'architecture OpenMP, qui supervise la spécification standard OpenMP. « Porter des codes scientifiques vers le nouveau matériel et les nouvelles architectures exascale sera un grand défi. La principale motivation de ce hackathon est l'engagement des applications - pour interagir plus profondément avec différents utilisateurs, en particulier ceux des laboratoires du DOE, et les faire prendre conscience des changements auxquels ils doivent s'attendre dans OpenMP et comment ces changements peuvent bénéficier à leurs applications scientifiques."

Le supercalculateur Summit. Crédit : Laboratoire national d'Oak Ridge
Jeter les bases de la portabilité des performances des applications
Scientifiques informatiques et de domaine, développeurs de code, et des experts en matériel informatique de Brookhaven, Argonne, Laurent Berkeley, Laurent Livermore, Oak Ridge, Géorgie Tech, Université de l'Indiana, Université du riz, Université de l'Illinois à Urbana-Champaign, IBM, et la National Aeronautics and Space Administration (NASA) ont participé au hackathon. Les huit équipes ont été guidées par le laboratoire national, Université, et des mentors de l'industrie qui ont été sélectionnés sur la base de leur vaste expérience dans la programmation de GPU, participer au comité des langues OpenMP, et mener des travaux de recherche et de développement sur des outils prenant en charge les dernières spécifications OpenMP.
Pendant la semaine, les équipes ont travaillé au portage de leurs applications scientifiques des unités centrales (CPU) vers les GPU et à leur optimisation avec la dernière version d'OpenMP (4.5+). Entre les sessions de piratage, les équipes disposaient de tutoriels sur diverses fonctionnalités avancées d'OpenMP, y compris la programmation de l'accélérateur, des outils de profilage pour évaluer la performance, et les stratégies d'optimisation des applications.
Certaines équipes ont également utilisé les dernières fonctionnalités OpenMP pour programmer les processeurs IBM Power9 accélérés avec les GPU NDIVIA. Le supercalculateur le plus rapide au monde, le supercalculateur Summit de l'OLCF, repose sur cette nouvelle architecture, avec plus de 9000 processeurs IBM Power9 et plus de 27, 000 GPU NVIDIA.
Faire des pas vers l'exascale
Les applications des équipes couvraient de nombreux domaines, y compris la physique nucléaire et des hautes énergies, lasers et optiques, la science des matériaux, systèmes autonomes, et la mécanique des fluides.
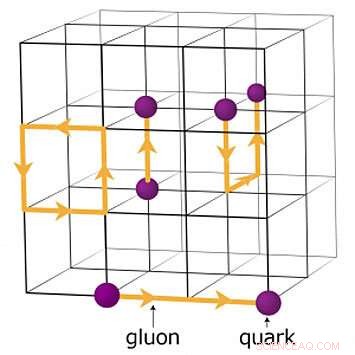
Un schéma du réseau pour les calculs de chromodynamique quantique. Les points d'intersection sur la grille représentent les valeurs des quarks, tandis que les lignes entre elles représentent les valeurs de gluons. Crédit :Laboratoire national de Brookhaven
Le participant David Wagner du NASA Langley Research Center High Performance Computing Incubator et ses collègues Gabriele Jost et Daniel Kokron du NASA Ames Research Center sont venus avec un code pour simuler l'élasticité. Leur objectif au hackathon était d'augmenter l'instruction unique, le parallélisme à données multiples (SIMD) - un type de calcul dans lequel plusieurs processeurs effectuent la même opération sur de nombreux points de données simultanément - et optimisent la vitesse à laquelle les données peuvent être lues et stockées en mémoire.
"Les scientifiques de la NASA essaient de comprendre comment et pourquoi les matériaux des avions et des engins spatiaux échouent, " a déclaré Wagner. "Nous devons nous assurer que ces matériaux sont suffisamment durables pour résister à toutes les forces qui sont présentes lors d'une utilisation normale pendant le service. Au hackathon, nous travaillons sur une mini-application représentative des parties les plus gourmandes en calcul du programme plus vaste pour modéliser ce qui se passe physiquement lorsque les matériaux sont chargés, courbé, et étiré. Notre code contient de nombreuses petites formules qui doivent être exécutées des milliards de fois. Le défi consiste à effectuer tous les calculs très rapidement."
Selon Wagner, l'une des raisons pour lesquelles la NASA fait pression pour cette capacité de calcul maintenant est de comprendre les processus utilisés pour générer des pièces fabriquées de manière additive (imprimées en 3D) et les différentes propriétés matérielles de ces pièces, qui sont de plus en plus utilisés dans les avions. Il est important de connaître ces informations pour assurer la sécurité, fiabilité, et la durabilité des matériaux tout au long de leur durée de vie opérationnelle.
"Le hackathon a été un succès pour nous, " a déclaré Wagner. " Nous avons configuré notre code pour une exécution massivement parallèle et s'exécute correctement sur le matériel GPU. Nous allons continuer avec le débogage et le réglage des performances en parallèle, car nous nous attendons à ce que le matériel et les logiciels appropriés de la NASA soient bientôt disponibles."
Une autre équipe a adopté une approche similaire en essayant de faire fonctionner OpenMP pour une petite partie de leur code, un code de chromodynamique quantique sur réseau (QCD) qui est au centre d'un projet ECP appelé Lattice QCD :Lattice Quantum Chromodynamics for Exascale. Lattice QCD est un cadre numérique pour simuler les interactions fortes entre les particules élémentaires appelées quarks et gluons. De telles simulations sont importantes pour de nombreux problèmes de haute énergie et de physique nucléaire. Les simulations typiques nécessitent des mois de fonctionnement sur des supercalculateurs.
"Nous aimerions que notre code fonctionne sur différentes architectures exascale, " a déclaré le membre de l'équipe et informaticien Meifeng Lin, chef de groupe adjoint du nouveau groupe d'informatique quantique de CSI et coordinateur local des précédents hackathons. "À l'heure actuelle, le code fonctionne sur des GPU NVIDIA, mais les prochains ordinateurs exascale devraient avoir au moins deux architectures différentes. Nous espérons qu'en utilisant OpenMP, qui est pris en charge par les principaux fournisseurs de matériel, nous pourrons plus facilement porter notre code sur ces plateformes émergentes. Nous avons passé les deux premiers jours du hackathon à essayer de faire en sorte qu'OpenMP décharge le code du CPU vers le GPU dans toute la bibliothèque, sans grand succès."

John Mellor-Crummey fait une présentation sur le HPCToolkit, une suite intégrée d'outils pour mesurer et analyser les performances des programmes sur des systèmes allant des ordinateurs de bureau aux superordinateurs. Crédit :Laboratoire national de Brookhaven
Mentor Lingda Li, chercheur associé au CSI et membre du projet SOLLVE, a aidé Lin et son collègue Chulwoo Jung, un physicien du groupe de théorie des hautes énergies de Brookhaven, avec le déchargement OpenMP.
Bien que l'équipe ait réussi à faire fonctionner OpenMP avec quelques centaines de lignes de code, ses performances initiales étaient médiocres. Ils ont utilisé divers outils de profilage des performances pour déterminer la cause du ralentissement. Avec ces informations, ils ont pu faire des progrès fondamentaux dans leur stratégie globale d'optimisation, y compris la résolution des problèmes liés au déchargement initial du GPU et la simplification du mappage des données.
Parmi les outils de profilage disponibles pour les équipes du hackathon, il y en avait un développé par l'Université Rice et l'Université du Wisconsin.
"Notre outil mesure les performances des codes accélérés par GPU à la fois sur l'hôte et sur le GPU, " a déclaré John Mellor-Crummey, professeur d'informatique et de génie électrique et informatique à l'Université Rice et chercheur principal du projet ECP correspondant Extending HPCToolkit to Measure and Analyze Code Performance on Exascale Platforms. "Nous l'avons utilisé sur plusieurs codes de simulation cette semaine pour examiner les performances relatives du calcul et du mouvement des données dans et hors des GPU. Nous pouvons dire non seulement combien de temps un code s'exécute, mais aussi combien d'instructions ont été exécutées et si l'exécution était à toute vitesse ou au point mort, et en cas de blocage, Pourquoi. Nous avons également identifié des problèmes de mappage avec les informations du compilateur qui associent le code machine et le code source."
D'autres mentors d'IBM étaient sur place pour montrer aux équipes comment utiliser les compilateurs IBM XL, conçus pour exploiter toute la puissance des processeurs IBM Power, et les aider à résoudre tous les problèmes rencontrés.
"Les compilateurs sont des outils que les scientifiques utilisent pour traduire leurs logiciels scientifiques en code lisible par le matériel, par les plus grands supercalculateurs du monde—Summit et Sierra [à Lawrence Livermore], " dit Doru Bercea, membre du personnel de recherche du groupe Advanced Compiler Technologies du IBM TJ Watson Research Center. "Le hackathon nous offre l'opportunité de discuter des décisions de conception du compilateur pour faire en sorte qu'OpenMP fonctionne mieux pour les scientifiques."
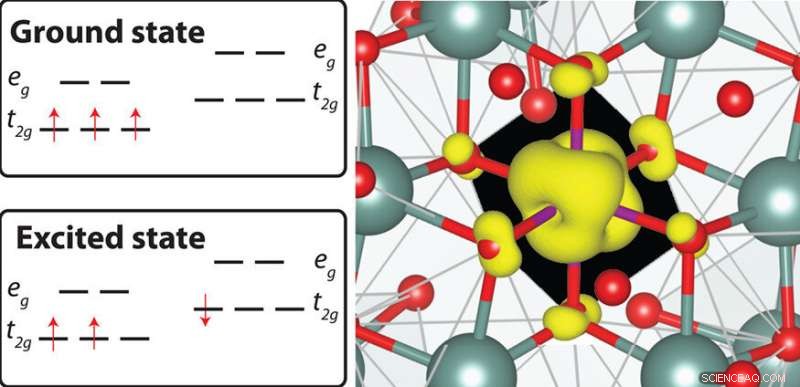
QMCPack peut être utilisé pour calculer les énergies de l'état fondamental et excité des défauts localisés dans les isolants et les semi-conducteurs, par exemple, en manganèse (Mn) 4+ -des phosphores dopés, qui sont des matériaux prometteurs pour améliorer la qualité des couleurs et la luminosité des diodes électroluminescentes blanches. Crédit :Laboratoire national de Brookhaven
Selon le mentor Johannes Doerfert, chercheur postdoctoral à l'ALCF, les applications que les équipes ont apportées au hackathon étaient à divers stades en termes de préparation pour les systèmes informatiques à venir.
"Certaines équipes sont confrontées à des problèmes de portage, certains ont du mal avec les compilateurs, et certains ont des problèmes de performances des applications, " a expliqué Doerfert. " En tant que mentors, nous recevons des questions venant de n'importe où dans ce large spectre."
Parmi les autres applications scientifiques apportées par les équipes, citons un code (pf3d) pour simuler les interactions entre les lasers à haute intensité et le plasma (gaz ionisé) dans des expériences au National Ignition Facility de Lawrence Livermore, et un code de calcul de la structure électronique des atomes, molécules, et solides (QMCPack, également un projet ECP). Une autre équipe ECP a apporté un environnement de programmation portable (RAJA) pour le langage de programmation C++.
"Nous développons une abstraction de haut niveau appelée RAJA afin que les gens puissent utiliser tous les frameworks matériels ou logiciels disponibles sur le backend de leurs systèmes informatiques, " a déclaré le mentor Tom Scogland, chercheur postdoctoral au Center for Applied Scientific Computing de Lawrence Livermore. "RAJA cible principalement OpenMP sur l'hôte et CUDA [un autre modèle de programmation informatique parallèle] sur le backend. Mais nous voulons que RAJA fonctionne avec d'autres modèles de programmation sur le backend, y compris OpenMP."
"Le thème du hackathon était OpenMP 4.5+, une version évolutive et pas encore totalement mature, " a expliqué Kong. " Les équipes sont reparties avec une meilleure compréhension des nouvelles fonctionnalités d'OpenMP, connaissance des nouveaux outils qui deviennent disponibles sur Summit, et une feuille de route à suivre sur le long terme."
"J'ai appris un certain nombre de choses sur OpenMP 4.5, " a déclaré Steve Langer, membre de l'équipe pf3d, un physicien computationnel à Lawrence Livermore. « Le plus grand avantage a été les discussions avec les mentors et les employés d'IBM. Je sais maintenant comment emballer mes directives de déchargement OpenMP pour utiliser les GPU NVIDIA sans rencontrer de limitations de mémoire. »