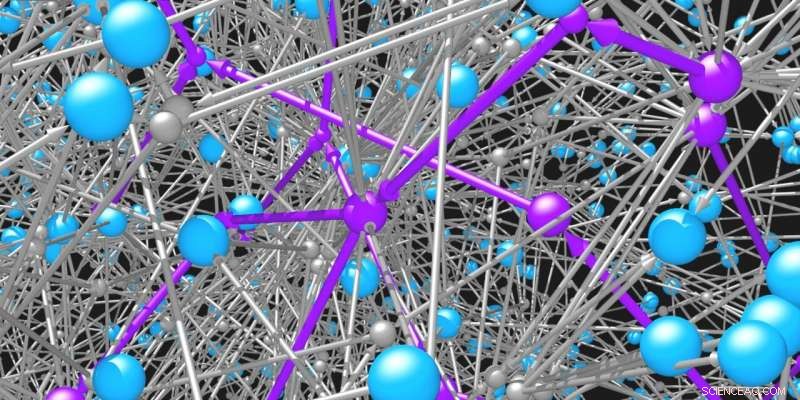
Les molécules (sphères bleues) sont reliées entre elles par les réactions (sphères grises et flèches) auxquelles elles participent. Le réseau de molécules organiques et de réactions possibles est incroyablement vaste. Des algorithmes de recherche intelligents sont nécessaires pour identifier les voies possibles (violet) pour synthétiser les molécules souhaitées. Crédit :Mikolaj Kowalik &Kyle Bishop/Columbia Engineering
Des chercheurs, des biochimistes aux scientifiques des matériaux, ont longtemps compté sur la riche variété de molécules organiques pour résoudre des défis urgents. Certaines molécules peuvent être utiles dans le traitement de maladies, d'autres pour éclairer nos affichages numériques, d'autres encore pour les pigments, des peintures, et plastiques. Les propriétés uniques de chaque molécule sont déterminées par sa structure, c'est-à-dire par la connectivité de ses atomes constitutifs. Une fois qu'une structure prometteuse est identifiée, il reste la tâche difficile de fabriquer la molécule ciblée par une séquence de réactions chimiques. Mais lesquels ?
Les chimistes organiques travaillent généralement à rebours de la molécule cible aux matériaux de départ en utilisant un processus appelé analyse rétrosynthétique. Au cours de ce processus, le chimiste est confronté à une série de décisions complexes et interdépendantes. Par exemple, des dizaines de milliers de réactions chimiques différentes, laquelle choisir pour créer la molécule cible ? Une fois cette décision prise, vous pouvez vous retrouver avec plusieurs molécules réactives nécessaires à la réaction. Si ces molécules ne sont pas disponibles à l'achat, alors comment sélectionnez-vous les réactions appropriées pour les produire ? Choisir intelligemment ce qu'il faut faire à chaque étape de ce processus est essentiel pour naviguer dans le grand nombre de chemins possibles.
Des chercheurs de Columbia Engineering ont développé une nouvelle technique basée sur l'apprentissage par renforcement qui entraîne un modèle de réseau neuronal à sélectionner correctement la « meilleure » réaction à chaque étape du processus de rétrosynthèse. Cette forme d'IA fournit un cadre aux chercheurs pour concevoir des synthèses chimiques qui optimisent les objectifs spécifiés par l'utilisateur tels que le coût de synthèse, sécurité, et durabilité. La nouvelle approche, publié le 31 mai par ACS Science centrale , est plus efficace (d'environ 60 %) que les stratégies existantes pour résoudre ce problème de recherche difficile.
« L'apprentissage par renforcement a créé des joueurs informatiques qui sont bien meilleurs que les humains pour jouer à des jeux vidéo complexes. Peut-être que la rétrosynthèse n'est pas différente ! rétrosynthèse, " dit Alán Aspuru-Guzik, professeur de chimie et d'informatique à l'Université de Toronto, qui n'a pas participé à l'étude.
L'équipe a présenté le défi de la planification rétrosynthétique comme un jeu comme les échecs et le go, où le nombre combinatoire de choix possibles est astronomique et la valeur de chaque choix incertaine jusqu'à ce que le plan de synthèse soit achevé et son coût évalué. Contrairement aux études antérieures qui utilisaient des fonctions de notation heuristiques - de simples règles empiriques - pour guider la planification rétrosynthétique, cette nouvelle étude a utilisé des techniques d'apprentissage par renforcement pour porter des jugements basés sur la propre expérience du modèle neuronal.
"Nous sommes les premiers à appliquer l'apprentissage par renforcement au problème de l'analyse rétrosynthétique, " dit Kyle Bishop, professeur agrégé de génie chimique. "Partant d'un état d'ignorance totale, où le modèle ne connaît absolument rien à la stratégie et applique des réactions au hasard, le modèle peut s'exercer et s'entraîner jusqu'à ce qu'il trouve une stratégie qui surpasse une heuristique définie par l'homme. »
Dans leur étude, L'équipe de Bishop s'est concentrée sur l'utilisation du nombre d'étapes de réaction comme mesure de ce qui constitue une « bonne » voie de synthèse. Leur modèle d'apprentissage par renforcement a adapté sa stratégie à cet objectif. En utilisant l'expérience simulée, l'équipe a formé le réseau neuronal du modèle pour estimer le coût de synthèse attendu ou la valeur d'une molécule donnée sur la base d'une représentation de sa structure moléculaire.
L'équipe prévoit d'explorer différents objectifs à l'avenir, par exemple, entraîner le modèle pour minimiser les coûts plutôt que le nombre de réactions, ou pour éviter les molécules qui pourraient être toxiques. Les chercheurs tentent également de réduire le nombre de simulations nécessaires au modèle pour apprendre sa stratégie, car le processus de formation était assez coûteux en calcul.
"Nous espérons que notre jeu de rétrosynthèse suivra bientôt la voie des échecs et du Go, dans lequel les algorithmes autodidactes surpassent systématiquement les experts humains, » note Bishop. « Et nous accueillons favorablement la concurrence. Comme pour les programmes informatiques de jeu d'échecs, la concurrence est le moteur de l'amélioration de l'état de l'art, et nous espérons que d'autres pourront s'appuyer sur notre travail pour démontrer des performances encore meilleures."
L'étude s'intitule « Apprentissage de la planification rétrosynthétique grâce à une expérience simulée ».