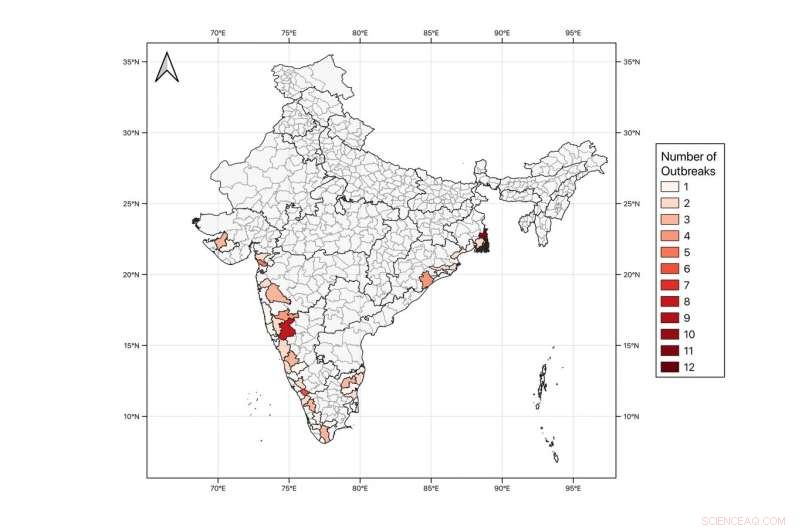
Nombre d'épidémies de choléra signalées dans les rapports épidémiologiques hebdomadaires publiés par le Programme intégré de surveillance des maladies de l'Inde (IDSP) au cours de la période de janvier 2010 à décembre 2018 pour les 40 districts côtiers de l'Inde sélectionnés dans l'étude. Seuls les districts ayant communiqué des données sur l'incidence du choléra pour lesquels les sept ensembles de données de variables climatiques essentielles (VCE) étaient disponibles sont indiqués. Crédit :Campbell et al., 2020
Les données climatiques prises par les satellites en orbite terrestre, combinées à des techniques d'apprentissage automatique, aident à mieux prévoir les épidémies de choléra et potentiellement à sauver des vies.
Le choléra est une maladie d'origine hydrique causée par l'ingestion d'eau ou d'aliments contaminés par la bactérie Vibrio cholerae, que l'on trouve dans de nombreuses régions côtières du monde, surtout dans les zones tropicales densément peuplées. L'agent pathogène responsable vit généralement sous des températures chaudes, salinité et turbidité modérées, et peut être hébergé par le plancton et les détritus dans l'eau.
Le réchauffement climatique et l'augmentation des phénomènes météorologiques extrêmes sont à l'origine d'épidémies de choléra, une maladie qui touche 1,3 à 4 millions de personnes chaque année dans le monde et cause jusqu'à 143 000 décès. Une nouvelle étude montre comment les épidémies de choléra dans les régions côtières de l'Inde peuvent être prédites avec un taux de réussite de 89 %, dans la première démonstration de l'utilisation de la salinité de la surface de la mer pour la prévision du choléra.
La recherche publiée hier dans le Revue internationale de recherche environnementale et de santé publique se concentre sur la prévision des épidémies de choléra dans le nord de l'océan Indien, où plus de la moitié des cas mondiaux de la maladie ont été signalés au cours de la période 2010-16.
Les relations entre les facteurs environnementaux de l'incidence du choléra sont complexes, et varient selon les saisons, avec différents effets décalés, par exemple de la mousson. Les algorithmes d'apprentissage automatique peuvent aider à surmonter ces problèmes en apprenant à reconnaître des modèles dans de grands ensembles de données afin de faire des prédictions testables.
L'étude a été dirigée par Amy Campbell lors d'un stage d'études supérieures d'un an au Bureau du climat de l'ESA. Amy, avec ses co-auteurs au Plymouth Marine Laboratory (PML), a utilisé un algorithme d'apprentissage automatique populaire dans les applications des sciences de l'environnement, le classificateur de forêts aléatoires, qui peut reconnaître des modèles dans de longs ensembles de données et faire des prédictions testables.
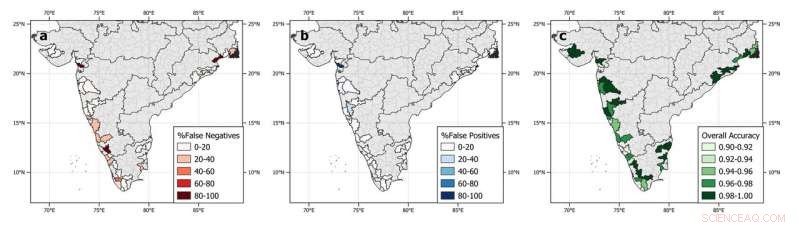
Les résultats des mesures de performance du modèle forestier aléatoire lorsqu'ils sont appliqués à des données de test invisibles pour les districts individuels de la côte indienne qui ont signalé des épidémies de choléra. Les districts côtiers où aucune épidémie de choléra n'a été signalée au cours de la période d'étude et les districts non côtiers sont indiqués en gris. Crédit :Campbell et al., 2020
L'algorithme a été formé sur les épidémies signalées dans les districts côtiers de l'Inde entre 2010 et 2018, et appris les relations avec six enregistrements climatiques satellitaires générés par l'Initiative sur le changement climatique (CCI) de l'ESA.
En incluant ou en supprimant des variables environnementales et des sous-réglages pour différentes saisons, l'algorithme a identifié des variables clés pour prédire les épidémies de choléra comme la température à la surface des terres, la salinité de la surface de la mer, concentration de chlorophylle-a et différence du niveau de la mer par rapport à la moyenne (anomalie du niveau de la mer).
Amy Campbell a dit, "Le modèle a montré des résultats prometteurs, et il existe de nombreuses possibilités de développer ce travail en utilisant différents ensembles de données de surveillance du choléra ou dans différents endroits. Dans notre étude, nous avons testé différentes techniques d'apprentissage automatique et avons trouvé que le classificateur de forêt aléatoire était le meilleur, mais il y a beaucoup plus de techniques qui pourraient être étudiées.
« Il serait intéressant de tester l'impact de l'inclusion d'ensembles de données socio-économiques ; les données de télédétection pourraient être utilisées pour développer des enregistrements pour tenir compte des facteurs humains qui sont importants pour l'incidence du choléra, comme l'accès aux ressources en eau.
L'étude et ses nouvelles connaissances ont contribué au projet UKRI-NERC Pathways Of Dispersal for Cholera And Solution Tools (PODCAST) dirigé par la co-auteure Marie-Fanny Racault à PML, qui évalue l'impact du réchauffement climatique et des extrêmes climatiques sur les habitats propices à Vibrio cholerae.
Les résultats de l'étude seront démontrés lors de la réunion COP26 de la CCNUCC en 2021 via un outil de prévision en ligne dans le cadre du projet PODCAST-DEMO.