Le modèle à effets mixtes permet une identification plus précise des points chauds dans lesquels les variables atmosphériques se rapportent différemment par rapport à d'autres zones. Crédit :John Wiley &Sons Ltd.
Une méthode plus fiable pour identifier les régions avec des relations différentes entre la pollution atmosphérique et les conditions météorologiques améliore la détection des points chauds de pollution.
La relation entre les conditions météorologiques et la pollution de l'air est complexe et peut varier énormément d'un endroit à l'autre. Cela rend difficile l'identification des sources de pollution et la prévision de son comportement dans l'atmosphère. Alors que les scientifiques des données et les statisticiens ont fait des progrès significatifs dans la lutte contre ce problème, les énormes volumes de données environnementales et la multitude de variables, comme la vitesse du vent, composante température et pollution, nécessitent des compromis pour rendre le problème gérable.
Par exemple, la plupart des approches existantes pour détecter les "points chauds" dans la corrélation entre les variables dans les données spatiales impliquent la construction d'une grille dans laquelle la relation entre les variables dans une cellule est traitée indépendamment de toutes les autres. Bien que cela ne soit pas tout à fait réaliste - il existe souvent une dépendance entre les zones spatiales, en particulier dans les données météorologiques et de pollution de l'air - il est extrêmement difficile de trouver des points chauds spatiaux et de déterminer la structure de dépendance spatiale en même temps.
Ying Sun et Junho Lee du Laboratoire de statistiques environnementales de KAUST ont fait un bond en avant pour résoudre ce problème avec le développement d'un « modèle à effets mixtes » pour la détection des points chauds.

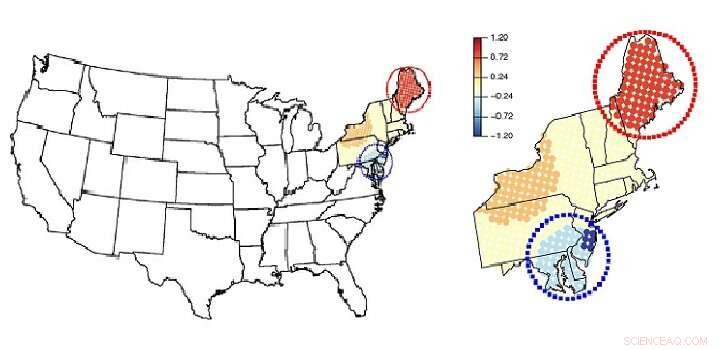
Cette carte montre comment le modèle à effets mixtes divise le nord-est des États-Unis en blocs, leur permettant d'identifier les « points chauds ». Crédit :John Wiley &Sons Ltd
« Nous abordons le problème en utilisant une structure de bloc spatial simple pour approximer la dépendance spatiale, ", explique Lee. "Cela nous permet de trouver des points chauds spatiaux présentant des modèles distincts tout en réduisant le taux de faux positifs dus à la dépendance spatiale."
L'approche, développé en collaboration avec Howard Chang de l'Université Emory aux États-Unis, implique de diviser la région en blocs et d'appliquer séquentiellement des effets aléatoires aux blocs pour dégager de fortes corrélations à partir de la variabilité de fond ou du "bruit". Cela a l'avantage supplémentaire de pouvoir identifier n'importe quel nombre de clusters de points chauds dans les données, y compris les grappes qui peuvent se chevaucher.
"Le principal défi était de savoir comment décider d'une taille de bloc appropriée pour les effets aléatoires, " dit Lee. " Nous avons décidé de faire correspondre la taille du bloc à la plage de dépendance spatiale dans les données. "
L'équipe a appliqué sa méthode pour analyser les données sur la pollution de l'air dans le nord-est des États-Unis. Ils ont découvert qu'en été, les concentrations de particules micrométriques dans l'air (PM2,5) augmentaient avec la température et diminuaient avec l'humidité relative dans la majeure partie de la région.
"Toutefois, avec notre approche, nous pourrions trouver des zones distinctes avec la tendance inverse, comme dans la région de la baie de Chesapeake, lorsqu'il existe une association négative entre les PM2,5 et la température, et autour du Maine où il existe une corrélation positive entre les PM2,5 et l'humidité relative, " dit Lee.