Un classificateur d'images profondes peut déterminer des classes d'images avec plus de 90 % de confiance en utilisant principalement des bordures d'image, plutôt qu'un objet lui-même. Crédit :Rachel Gordon
Malgré tout ce que les réseaux de neurones peuvent accomplir, nous ne comprenons toujours pas vraiment comment ils fonctionnent. Bien sûr, nous pouvons les programmer pour apprendre, mais donner un sens au processus de prise de décision d'une machine reste un peu comme un puzzle fantaisiste avec un motif complexe et vertigineux où de nombreuses pièces intégrales doivent encore être ajustées.
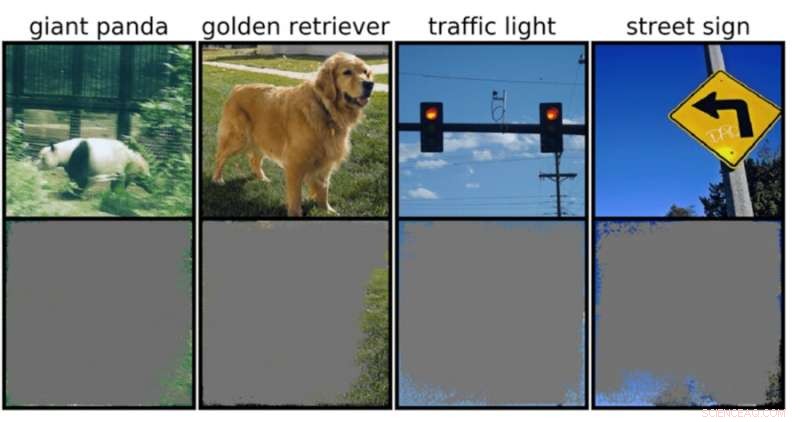
Si un modèle essayait de classer une image dudit puzzle, par exemple, il pourrait rencontrer des attaques adverses bien connues mais ennuyeuses, ou encore des problèmes de données ou de traitement plus courants. Mais un nouveau type d'échec plus subtil récemment identifié par les scientifiques du MIT est une autre cause de préoccupation :la "surinterprétation", où les algorithmes font des prédictions fiables basées sur des détails qui n'ont pas de sens pour les humains, comme des modèles aléatoires ou des bordures d'image.
Cela pourrait être particulièrement inquiétant pour les environnements à enjeux élevés, comme les décisions en une fraction de seconde pour les voitures autonomes et les diagnostics médicaux pour les maladies qui nécessitent une attention plus immédiate. Les véhicules autonomes, en particulier, s'appuient fortement sur des systèmes capables de comprendre avec précision l'environnement et de prendre des décisions rapides et sûres. Le réseau utilisait des arrière-plans, des bords ou des motifs particuliers du ciel pour classer les feux de circulation et les panneaux de signalisation, indépendamment de ce qui se trouvait d'autre dans l'image.
L'équipe a découvert que les réseaux de neurones entraînés sur des ensembles de données populaires comme CIFAR-10 et ImageNet souffraient d'une surinterprétation. Les modèles formés sur CIFAR-10, par exemple, ont fait des prédictions fiables même lorsque 95 % des images d'entrée manquaient, et le reste est insensé pour les humains.
"La surinterprétation est un problème d'ensemble de données causé par ces signaux absurdes dans les ensembles de données. Non seulement ces images à haute confiance sont méconnaissables, mais elles contiennent moins de 10 % de l'image d'origine dans des zones sans importance, telles que les frontières. Nous avons constaté que ces images étaient sans signification pour les humains, mais les modèles peuvent toujours les classer avec une grande confiance », déclare Brandon Carter, Ph.D. du Laboratoire d'informatique et d'intelligence artificielle du MIT. étudiant et auteur principal d'un article sur la recherche.
Les classificateurs d'images profondes sont largement utilisés. En plus du diagnostic médical et de l'amélioration de la technologie des véhicules autonomes, il existe des cas d'utilisation dans la sécurité, les jeux et même une application qui vous indique si quelque chose est ou n'est pas un hot-dog, car parfois nous avons besoin d'être rassurés. La technologie en discussion fonctionne en traitant des pixels individuels à partir de tonnes d'images pré-étiquetées pour que le réseau "apprenne".
La classification des images est difficile, car les modèles d'apprentissage automatique ont la capacité de se verrouiller sur ces signaux subtils absurdes. Ensuite, lorsque les classificateurs d'images sont formés sur des ensembles de données tels que ImageNet, ils peuvent faire des prédictions apparemment fiables basées sur ces signaux.
Bien que ces signaux absurdes puissent conduire à la fragilité du modèle dans le monde réel, les signaux sont en fait valides dans les ensembles de données, ce qui signifie qu'une surinterprétation ne peut pas être diagnostiquée à l'aide de méthodes d'évaluation typiques basées sur cette précision.
Pour trouver la justification de la prédiction du modèle sur une entrée particulière, les méthodes de la présente étude commencent par l'image complète et demandent à plusieurs reprises, que puis-je supprimer de cette image ? Essentiellement, il continue de couvrir l'image, jusqu'à ce qu'il vous reste le plus petit morceau qui prend encore une décision confiante.
À cette fin, il pourrait également être possible d'utiliser ces méthodes comme une sorte de critères de validation. Par exemple, si vous avez une voiture à conduite autonome qui utilise une méthode d'apprentissage automatique pour reconnaître les panneaux d'arrêt, vous pouvez tester cette méthode en identifiant le plus petit sous-ensemble d'entrée qui constitue un panneau d'arrêt. S'il s'agit d'une branche d'arbre, d'une heure particulière de la journée ou de quelque chose qui n'est pas un panneau d'arrêt, vous pourriez craindre que la voiture ne s'arrête à un endroit où elle n'est pas censée s'arrêter.
Bien qu'il puisse sembler que le modèle soit le coupable probable ici, les ensembles de données sont plus susceptibles d'être à blâmer. "Il y a la question de savoir comment nous pouvons modifier les ensembles de données d'une manière qui permettrait aux modèles d'être formés pour imiter plus étroitement la façon dont un humain penserait à classer les images et donc, espérons-le, mieux généraliser dans ces scénarios du monde réel, comme la conduite autonome. et un diagnostic médical, afin que les modèles n'aient pas ce comportement absurde », explique Carter.
Cela peut signifier créer des ensembles de données dans des environnements plus contrôlés. Actuellement, ce ne sont que des images extraites du domaine public qui sont ensuite classées. Mais si vous voulez faire l'identification d'objets, par exemple, il peut être nécessaire de former des modèles avec des objets avec un arrière-plan non informatif.