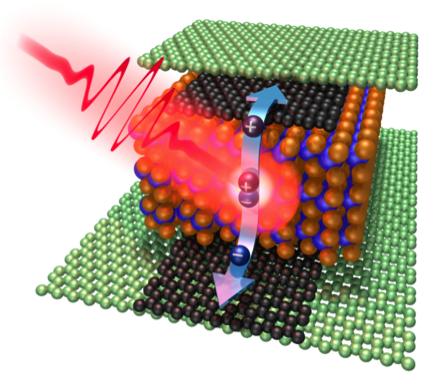
Exemples d'images fixes de traductions générées par le modèle (la rangée du haut contient de vraies images humaines, la rangée du bas sont de fausses images de robots). Crédit :Smith et al.
Dans les années récentes, des équipes de recherche du monde entier ont utilisé l'apprentissage par renforcement (RL) pour enseigner aux robots comment accomplir une variété de tâches. Entraîner ces algorithmes, cependant, peut être très difficile, car cela nécessite également des efforts humains substantiels pour définir correctement les tâches que le robot doit accomplir.
Une façon d'enseigner aux robots comment accomplir des tâches spécifiques consiste à faire des démonstrations humaines. Bien que cela puisse sembler simple, il peut être très difficile à mettre en œuvre, principalement parce que les robots et les humains ont des corps très différents, ils sont donc capables de mouvements différents.
Des chercheurs de l'Université de Californie à Berkeley ont récemment développé un nouveau cadre qui pourrait aider à surmonter certains des défis rencontrés lors de la formation de robots via l'apprentissage par imitation (c'est-à-dire, en utilisant des démonstrations humaines). leur cadre, appelé AVID, sur la base de deux modèles d'apprentissage en profondeur développés dans des recherches antérieures.
"Lors du développement d'AVID, nous nous sommes appuyés en grande partie sur deux travaux récents, CycleGAN et SOLAIRE, qui a introduit des approches pour remédier aux limitations fondamentales qui ont empêché l'apprentissage à partir de vidéos humaines dans le domaine du changement et la formation sur un robot physique à partir d'une entrée visuelle, respectivement, " Laura Smith, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore.
Au lieu d'utiliser des techniques qui ne tiennent pas compte des différences entre un robot et le corps d'un utilisateur humain, Smith et ses collègues ont utilisé Cycle-GAN, une technique qui peut transformer les images au niveau du pixel. En utilisant Cycle-GAN, leur méthode convertit des démonstrations humaines sur la façon d'accomplir une tâche donnée en vidéos d'un robot effectuant la même tâche. Ils ont ensuite utilisé ces vidéos pour développer une fonction de récompense pour un algorithme RL.

Exemples d'images fixes de traductions générées par le modèle (la rangée du haut contient de vraies images humaines, la rangée du bas sont de fausses images de robots). Crédit :Smith et al.
"AVID fonctionne en demandant au robot d'observer un humain effectuer une tâche, puis d'imaginer à quoi cela ressemblerait pour lui-même d'effectuer la même chose, " Smith a expliqué. " Pour apprendre comment atteindre réellement ce succès imaginaire, nous laissons le robot apprendre par essais et erreurs."
En utilisant le cadre développé par Smith et ses collègues, un robot apprend les tâches étape par étape, réinitialiser chaque étape et réessayer sans nécessiter l'intervention d'un utilisateur humain. Le processus d'apprentissage devient ainsi largement automatisé, avec le robot apprenant de nouvelles compétences avec une intervention humaine minimale.
"Un avantage clé de notre approche est que l'enseignant humain peut interagir avec l'élève robot pendant qu'il apprend, " Smith a expliqué. " De plus, nous concevons notre cadre de formation pour être prêt à apprendre un comportement à long terme avec un minimum d'effort."