Crédit :Nvidia
L'objectif :transformer des images 2D en modèles 3D à l'aide d'une architecture encodeur-décodeur spéciale. Les acteurs :Nvidia. L'éloge :une utilisation intelligente de l'apprentissage automatique avec des applications bénéfiques du monde réel.
Paul Lilly dans Matériel chaud était parmi les observateurs techniques qui ont noté que la façon dont ils sont passés de 2D à 3D était une nouvelle. Ce n'est pas une grande surprise lorsque le chemin est inverse—de la 3D vers la 2D—mais "créer un modèle 3D sans alimenter un système en données 3D est bien plus difficile".
Lilly a cité Jun Gao, l'un des membres de l'équipe de recherche qui a travaillé sur l'approche de rendu. "C'est essentiellement la première fois que vous pouvez prendre à peu près n'importe quelle image 2D et prédire les propriétés 3D pertinentes."
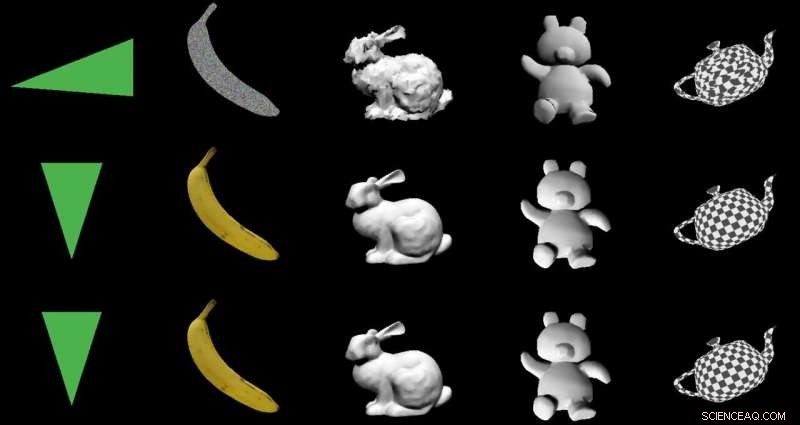
Leur sauce magique pour produire un objet 3D à partir d'images 2D est un "rendu différentiable basé sur l'interpolation, " ou DIB-R. Les chercheurs de Nvidia ont formé leur modèle sur des ensembles de données comprenant des images d'oiseaux. Après la formation, DIB-R avait la capacité de prendre une image d'oiseau et de fournir une représentation en 3D, avec la bonne forme et la bonne texture d'un oiseau 3-D.
Nvidia a en outre décrit l'entrée transformée en une carte de caractéristiques ou un vecteur utilisé pour prédire des informations spécifiques telles que la forme, Couleur, la texture et l'éclairage d'une image.
Pourquoi cela est important : Gizmodo le titre le résumait. "Nvidia a appris à une IA à générer instantanément des modèles 3D entièrement texturés à partir d'images 2D plates." Ce mot « instantanément » est important.
DIB-R peut produire un objet 3D à partir d'une image 2D en moins de 100 millisecondes, a déclaré Lauren Finkle de Nvidia. "Il le fait en modifiant une sphère polygonale, le modèle traditionnel qui représente une forme en 3D. DIB-R la modifie pour qu'elle corresponde à la forme réelle de l'objet représenté dans les images en 2D."
Andrew Liszewski dans Gizmodo a mis en évidence cet élément de temps de 100 millisecondes. « Cette vitesse de traitement impressionnante est ce qui rend cet outil particulièrement intéressant car il a le potentiel d'améliorer considérablement la façon dont les machines comme les robots, ou voitures autonomes, voir le monde, et comprendre ce qui les attend."
Concernant les voitures autonomes, Liszewski a dit, "Les images fixes extraites d'un flux vidéo en direct d'une caméra pourraient être instantanément converties en modèles 3D permettant une voiture autonome, par exemple, pour évaluer avec précision la taille d'un gros camion qu'il doit éviter."

L'équipe a testé DIB-R sur quatre images 2D d'oiseaux (à l'extrême gauche). La première expérience a utilisé une image d'une paruline jaune (en haut à gauche) et a produit un objet 3D (deux rangées du haut). Crédit :Nvidia
Un modèle qui pourrait déduire un objet 3D à partir d'une image 2D serait capable d'effectuer un meilleur suivi d'objet, et Lilly s'est penchée sur son utilisation en robotique. "En transformant des images 2D en modèles 3D, un robot autonome serait mieux placé pour interagir avec son environnement de manière plus sûre et efficace, " il a dit.
Nvidia a noté que les robots autonomes, afin de le faire, « doit être capable de détecter et de comprendre son environnement. DIB-R pourrait potentiellement améliorer ces capacités de perception de la profondeur. »
Gizmodo est Liszewski, pendant ce temps, mentionné ce que l'approche Nvidia pourrait faire pour la sécurité. "DIB-R pourrait même améliorer les performances des caméras de sécurité chargées d'identifier les personnes et de les suivre, car un modèle 3D généré instantanément faciliterait la réalisation de correspondances d'images lorsqu'une personne se déplace dans son champ de vision."
Les chercheurs de Nvidia présenteraient leur modèle ce mois-ci lors de la conférence annuelle sur les systèmes de traitement de l'information neuronale (NeurIPS), à Vancouver.
Ceux qui souhaitent en savoir plus sur leurs recherches peuvent consulter leur article sur arXiv, "Apprendre à prédire les objets 3D avec un moteur de rendu différentiable basé sur l'interpolation." Les auteurs sont Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson et Sanja Fidler.
Ils ont proposé "un moteur de rendu différentiable complet basé sur la rastérisation pour lequel les gradients peuvent être calculés analytiquement". Lorsqu'il est enroulé autour d'un réseau de neurones, leur cadre a appris à prédire la forme, texture, et la lumière des images individuelles, ils ont dit, et ils ont présenté leur cadre "pour apprendre un générateur de formes texturées en 3D".
Dans leur résumé, les auteurs ont observé que « de nombreux modèles d'apprentissage automatique fonctionnent sur des images, mais ignorer le fait que les images sont des projections 2D formées par une géométrie 3D interagissant avec la lumière, dans un processus appelé rendu. Permettre aux modèles ML de comprendre la formation d'images pourrait être la clé de la généralisation."
Ils ont présenté DIB-R comme un cadre permettant de calculer analytiquement les gradients pour tous les pixels d'une image.
Ils ont déclaré que la clé de leur approche était de « considérer la rastérisation de premier plan comme une interpolation pondérée des propriétés locales et la rastérisation d'arrière-plan comme une agrégation de la géométrie globale basée sur la distance. Notre approche permet une optimisation précise sur les positions des sommets, couleurs, normales, directions de la lumière et coordonnées de texture à travers une variété de modèles d'éclairage."
© 2019 Réseau Science X