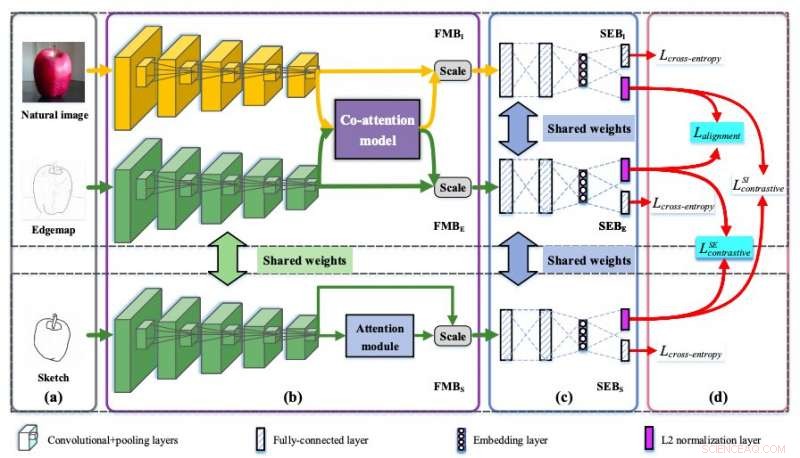
Illustration de l'architecture Semi3-Net. Crédit :Lei et al.
Dans les années récentes, les chercheurs ont développé des techniques de calcul de plus en plus avancées, tels que les algorithmes d'apprentissage en profondeur, pour accomplir une variété de tâches. Une tâche qu'ils ont essayé d'aborder est connue sous le nom de « recherche d'images basée sur des croquis » (SBIR).
Les tâches SBIR impliquent la récupération d'images d'un objet ou d'un concept visuel particulier parmi une large collection ou base de données basée sur des croquis réalisés par des utilisateurs humains. Pour automatiser cette tâche, les chercheurs ont essayé de développer des outils capables d'analyser des croquis humains et d'identifier des images liées au croquis ou contenant le même objet.
Malgré les résultats prometteurs obtenus par certains de ces outils, développer des techniques qui fonctionnent toujours bien sur les tâches SBIR s'est jusqu'à présent avéré difficile. Cela est principalement dû aux différences visuelles marquées entre les croquis abstraits et les images réelles. Par exemple, les croquis réalisés par les humains sont souvent déformés et abstraits, ce qui les rend plus difficiles à relier aux objets dans les images réelles.
Pour surmonter ce défi, Des chercheurs de l'Université de Tianjin et de l'Université des postes et télécommunications de Pékin en Chine ont récemment développé une architecture basée sur un réseau de neurones qui apprend des représentations discriminantes de caractéristiques inter-domaines pour les tâches de récupération d'images basées sur des croquis (SBIR). La technique qu'ils ont créée, présenté dans un article pré-publié sur arXiv, combine une variété de techniques de calcul, y compris la cartographie des caractéristiques semi-hétérogènes, modèles d'intégration sémantique conjointe et de co-attention.
"L'idée clé réside dans la façon dont nous cultivons les relations mutuelles et subtiles entre les croquis, images naturelles et edgemaps, ", ont écrit les chercheurs dans leur article. "La cartographie des caractéristiques semi-hétérogène est conçue pour extraire les caractéristiques inférieures de chaque domaine, où les branches sketch et edgemap sont partagées tandis que la branche image naturelle est hétérogène aux autres branches."
Le modèle conçu par les chercheurs est un réseau d'intégration conjointe à trois voies semi-hétérogène (Semi3-Net). En plus de la cartographie semi-hétérogène, il utilise une technique connue sous le nom d'intégration sémantique conjointe. L'intégration sémantique permet au réseau d'intégrer des fonctionnalités de différents domaines (par exemple, à partir de croquis ou de photographies) dans un espace sémantique commun de haut niveau. Semi3-Net intègre également un modèle de co-attention, qui est conçu pour recalibrer les caractéristiques extraites des deux domaines différents.
Finalement, les chercheurs ont conçu un mécanisme de perte hybride qui peut calculer la corrélation entre les croquis, edgemaps et images naturelles. Ce mécanisme permet au modèle Semi3-Net d'apprendre des représentations invariantes dans les deux domaines (c'est-à-dire, croquis et images prises à l'aide d'appareils photo).
Les chercheurs ont formé et évalué Semi3-Net sur les données de Sketchy et TU-Berlin Extension, deux ensembles de données largement utilisés dans les études axées sur les tâches SBIR. La base de données Sketchy contient 75, 471 croquis et 12, 500 images naturelles, tandis que l'extension TU-Berlin en contient 204, 489 images naturelles et 20, 000 croquis dessinés à la main.
Jusque là, Semi3-Net s'est remarquablement bien comporté dans toutes les expériences menées par les chercheurs, surpassant les autres modèles de pointe pour SBIR. L'équipe prévoit maintenant de continuer à travailler sur le modèle et d'améliorer encore ses performances, peut-être même en l'adaptant pour résoudre d'autres problèmes qui nécessitent de connecter des données de différents domaines.
"À l'avenir, nous nous concentrerons sur l'extension du réseau inter-domaines proposé à la récupération d'images à grain fin et à l'apprentissage de la correspondance des détails à grain fin pour les paires croquis-image, ", ont écrit les chercheurs dans leur article.
© 2019 Réseau Science X