Crédit :Gupta et al.
L'apprentissage par renforcement (RL) est une technique d'apprentissage machine largement utilisée qui consiste à former des agents d'IA ou des robots à l'aide d'un système de récompense et de punition. Jusque là, les chercheurs dans le domaine de la robotique ont principalement appliqué des techniques de RL dans des tâches qui sont accomplies sur des périodes de temps relativement courtes, comme avancer ou saisir des objets.
Une équipe de chercheurs de Google et Berkeley AI Research a récemment développé une nouvelle approche qui combine RL et apprentissage par imitation, un processus appelé apprentissage des politiques de relais. Cette approche, présenté dans un article prépublié sur arXiv et présenté à la Conférence sur l'apprentissage robotique (CoRL) 2019 à Osaka, peut être utilisé pour former des agents artificiels à s'attaquer à des tâches à plusieurs étapes et à long terme, telles que les tâches de manipulation d'objets qui s'étendent sur de plus longues périodes.
« Nos recherches sont issues de plusieurs, la plupart du temps sans succès, expérimenter des tâches très longues en utilisant l'apprentissage par renforcement (RL), " Abhishek Gupta, l'un des chercheurs qui a mené l'étude, a déclaré TechXplore. "Aujourd'hui, La RL en robotique est principalement appliquée à des tâches qui peuvent être accomplies dans un court laps de temps, comme saisir, pousser des objets, marcher en avant, etc. Bien que ces applications aient beaucoup de valeur, notre objectif était d'appliquer l'apprentissage par renforcement à des tâches qui nécessitent plusieurs sous-objectifs et fonctionnent sur des échelles de temps beaucoup plus longues, comme mettre une table ou nettoyer une cuisine."
Avant de commencer à développer leur approche, Gupta et ses collègues ont passé en revue la littérature précédente pour essayer de déterminer pourquoi les tâches plus longues sont particulièrement difficiles à aborder en utilisant les techniques actuelles de RL. Dans leur papier, ils suggèrent qu'il y a généralement deux raisons principales à cela.
D'abord, il est difficile pour un robot d'identifier par lui-même les solutions optimales pour résoudre des tâches longues et complexes. Seconde, il est difficile pour l'agent d'aborder avec succès une tâche longue pour laquelle un retour d'information n'est fourni qu'à la fin d'une longue séquence. Relais de l'apprentissage des politiques, la nouvelle approche de l'apprentissage qu'ils ont présentée, est conçu pour relever ces deux défis de front.
Crédit :Gupta et al.
« Pour relever le défi consistant à faire en sorte que les robots résolvent eux-mêmes des tâches à long terme, nous avons décidé de simplifier le problème et d'utiliser des démonstrations fournies par l'homme, " a déclaré Gupta. " Résoudre de longues tâches est difficile car il est extrêmement difficile de faire découvrir à un robot un comportement intéressant par lui-même. Les démonstrations fournies par l'homme peuvent être utilisées comme guide pour des choses intéressantes à faire dans un environnement. "
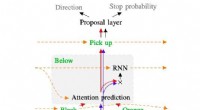
L'approche d'apprentissage robotique proposée par Gupta et ses collègues comporte deux étapes distinctes, l'un dans lequel un agent apprend en imitant les humains et l'autre basé sur la RL. Au stade de l'apprentissage par imitation, un robot est nourri de démonstrations humaines sur la façon d'accomplir une tâche et produit des politiques hiérarchiques conditionnées par des objectifs.
Dans leur étude, les chercheurs ont utilisé leur approche pour former un agent artificiel appelé Franka à des tâches de manipulation à plusieurs étapes et à long terme dans un environnement de cuisine simulé, qui a été modélisé à l'aide de la plate-forme de simulation physique MuJoCo. Cet environnement se composait d'une cuisine avec un micro-onde ouvrable, quatre brûleurs de four, un interrupteur d'éclairage de four, une bouilloire, deux armoires à charnières et une porte d'armoire coulissante.

Crédit :Gupta et al.
" Surtout, apprendre des démonstrations seules ne suffit pas pour résoudre les tâches difficiles dans notre environnement de cuisine simulé, " Karol Hausman, un autre chercheur impliqué dans l'étude, a déclaré TechXplore. « Afin d'améliorer cette première solution, nous permettons aux robots de pratiquer les tâches par eux-mêmes pour affiner davantage leurs comportements."
Essentiellement, en utilisant la méthode d'apprentissage des politiques de relais proposée par les chercheurs, un agent apprend d'abord en traitant des démonstrations humaines sur la façon d'accomplir une tâche donnée, puis continue à apprendre par lui-même via RL. Pour faciliter le processus d'apprentissage des politiques à long terme, l'équipe a utilisé un nouvel algorithme de réétiquetage des données qui permet à un agent d'apprendre des politiques hiérarchiques conditionnées par des objectifs.
« Afin de relever le défi du manque de commentaires, nous utilisons une structure hiérarchique pour nos politiques de contrôle :la politique de haut niveau propose des objectifs que la politique de bas niveau essaie d'accomplir, par exemple, fermer une armoire, éteindre le brûleur, etc., " expliqua Hausman. " Par ici, la tâche peut être facilement décomposée en sous-problèmes plus petits qui peuvent être résolus avec un apprentissage par renforcement amorcé à partir de démonstrations fournies par l'homme."

Crédit :Gupta et al.
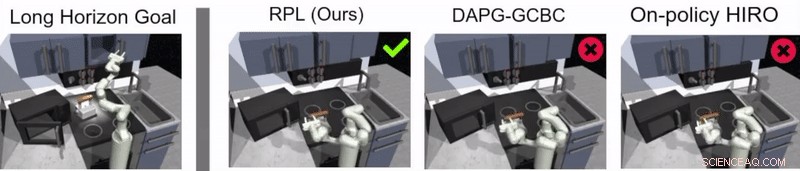
Guppta, Hausman et leurs collègues ont évalué l'efficacité de l'apprentissage des politiques de relais pour former des robots à des tâches à long terme dans l'environnement de cuisine simulé qu'ils ont créé, obtenir des résultats très prometteurs. Ils ont découvert qu'avec la bonne structure politique et les bonnes données de démonstration, leur approche a permis aux robots de s'attaquer à des tâches à horizon beaucoup plus long qu'ils ne le pensaient initialement possible.
« Nous espérons que nos découvertes pourront ouvrir de nouvelles voies pour combiner la recherche sur l'apprentissage par imitation et par renforcement et nous donner une direction potentielle qui peut permettre aux robots de fonctionner longtemps, tâches complexes, ", a déclaré Hausman.
À l'avenir, l'approche d'apprentissage des politiques de relais introduite par Gupta, Hausman et leurs collègues pourraient être utilisés pour entraîner des robots sur un plus large éventail de tâches à long terme. Les chercheurs n'ont jusqu'à présent testé leur technique que dans un environnement simulé; Donc, il serait intéressant de l'évaluer dans des conditions réelles et de voir s'il obtient des résultats tout aussi prometteurs.
« Comme prochaine étape, nous voudrions nous pencher sur le problème de la généralisation au-delà des données de démonstration, " Hausman a dit. " Finalement, nous souhaitons également améliorer encore l'efficacité des données de notre méthode, passer aux observations de pixels et permettre l'apprentissage du monde réel sur un robot physique."
© 2019 Réseau Science X